1. 本周学习总结
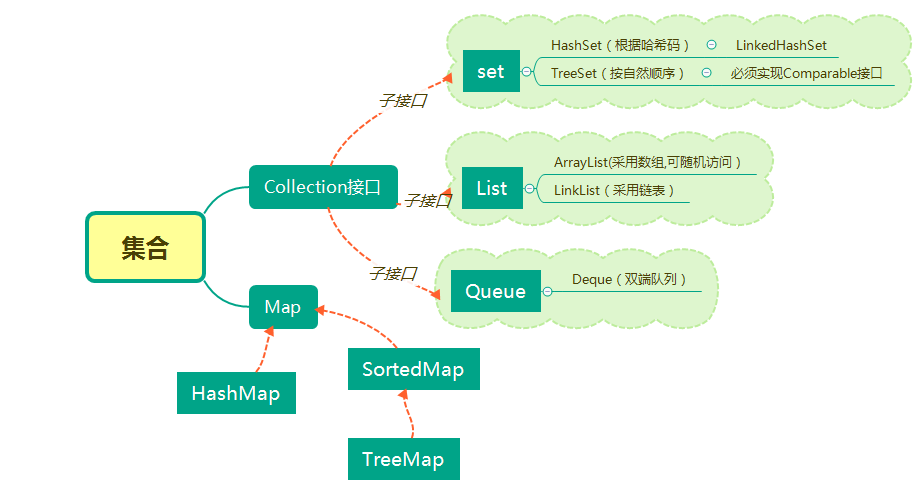
以你喜欢的方式(思维导图或其他)归纳总结集合相关内容。
2. 书面作业
ArrayList代码分析
1.1 解释ArrayList的contains源代码
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) { //找到元素就返回当前位置,否则返回-1
if (o == null) { //因为对于null没有分配内存空间,且不是对象,不能用equals来比较
for (int i = 0; i < size; i++)
if (elementData[i]==null) //elementData是数组缓冲区中存储元素的数组
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
1.2 解释E remove(int index)源代码
public E remove(int index) {
rangeCheck(index); //检查是否在范围内
modCount++; //初始值为0
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved); //将移除位置之后的元素向前挪动一个位置
elementData[--size] = null; // clear to let GC do its work
//将最后一个元素置空
return oldValue;
}
1.3 结合1.1与1.2,回答ArrayList存储数据时需要考虑元素的类型吗?
答:首先ArrayList存储的要是引用类型数据,在实例化一个动态数组时,人为地指定类型,如下图所示,所以不管用的是什么类型的,ArrayList都能转换
1.4 分析add源代码,回答当内部数组容量不够时,怎么办?
add源代码:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确认下个元素进来是否已经放不下了,如果是就扩充
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); // DEFAULT_CAPACITY = 10,默认长度为10
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) { //增加容量
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //新的=旧的*1.5
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity; //如果容量够了,就直接以这个长度创建数组
if (newCapacity - MAX_ARRAY_SIZE > 0) //如果不够,再扩充
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//最后将原来的复制到新的数组中
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE; //MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8
}
1.5 分析private void rangeCheck(int index)源代码,为什么该方法应该声明为private而不声明为public?
源代码:
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
public IndexOutOfBoundsException(String s) {
super(s);
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
get的源码:
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
答:比如在get方法的内部中,就可以用到rangeCheck的方法,不允许其他外面的类访问,所以设为private的类型
HashSet原理
2.1 将元素加入HashSet(散列集)中,其存储位置如何确定?需要调用那些方法?
add的源代码:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
将key和value放入map中
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//如果Key值为空,返回原hash值与原hash值右移16位的值按位异或的结果
}
那么这个putVals:(这么长,好难的样子...)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//table为空或长度为0,说明未创建
n = (tab = resize()).length; //创建
if ((p = tab[i = (n - 1) & hash]) == null) //判断下标为i的节点是否存在
tab[i] = newNode(hash, key, value, null);
else { //说明这个坑已经被占了,那么久要开始处理冲突了
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这个putVal处理冲突的好像有点复杂,那还是看看这个链接吧,讲得比较详细请戳此处
2.2 选做:尝试分析HashSet源代码后,重新解释2.1
答:使用hashCode方法的哈希码来确定位置,
构造函数:
public HashSet() {
map = new HashMap<>();
}
其本质上是HashMap
源代码:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; //计算哈希地址
}
hash = h;
}
return h;
}
eclipse自动生成的:
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x; //计算地址
return result;
}
ArrayListIntegerStack
题集jmu-Java-05-集合之5-1 ArrayListIntegerStack
3.1 比较自己写的ArrayListIntegerStack与自己在题集jmu-Java-04-面向对象2-进阶-多态、接口与内部类中的题目5-3自定义接口ArrayIntegerStack,有什么不同?(不要出现###大段代码)
答:不同之处在于前者使用了ArrayList的动态数组,不需要判断是否栈满,直接使用ArrayList内部的方法,后者是已经定义了数组的长度,纯粹就是对数组的操作
3.2 简单描述接口的好处.
这题我漏做了...现在补上
简而言之:接口含有实现这个接口的类所拥有共性的属性和方法,在接口里定义方法(不需要具体的实现),在实现类中复写我们想要的实现方式,比较方便
Stack and Queue
4.1 编写函数判断一个给定字符串是否是回文,一定要使用栈,但不能使用java的Stack类(具体原因自己搜索)。请粘贴你的代码,类名为Main你的学号。
public class Main063 {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println("请输入字符串:");
while (scan.hasNext()) {
ArrayListStack stack = new ArrayListStack();
String s = scan.next();
String s1="";
for (int i = 0; i < s.length(); i++) {
s1 = s.substring(i, i + 1);
stack.push(s1);
}
s1 = "";
for (int i = 0; i < s.length(); i++) {
s1 = s1 + stack.peek();
stack.pop();
}
if (s.equals(s1)) {
System.out.println("是回文");
}else {
System.out.println("不是回文");
}
System.out.println("请输入字符串:");
}
scan.close();
}
}
大概思路:利用到接口,复写入栈,出栈的方法,取栈顶元素的方法
4.2 题集jmu-Java-05-集合之5-6 银行业务队列简单模拟。(不要出现大段代码)
统计文字中的单词数量并按单词的字母顺序排序后输出

答:这题主要用的是用到Queue接口,如上图所示,我们只能用Queue的实现类,比如LinkList来实现,这题我用了三个对,第一个放奇数,第二个放偶数,第三个是放真正的顺序,好像有点多此一举...好像可以利用几个循环就好了
题集jmu-Java-05-集合之5-2 统计文字中的单词数量并按单词的字母顺序排序后输出 (不要出现大段代码)
5.1 实验总结
分析:这题我用到了比较器(p为实现比较器接口的一个实现类,根据题意在该类中比较大小)
TreeSet<String> set = new TreeSet<String>(new p());
最后打印出前十个就好了
选做:加分考察-统计文字中的单词数量并按出现次数排序
题集jmu-Java-05-集合之5-3 统计文字中的单词数量并按出现次数排序(不要出现大段代码)
- 6.1 伪代码
s.equals("!!!!!") break
map.containsKey(s)?map.put(s, map.get(s) + 1):map.put(s, 1);
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() )
for i in range 10
list.get(i).toString()
- 6.2 实验总结
这题用到了map映射,用其中containsKey方法来判断是否已经存在当前的映射,将统计累加的数字,还有对应的单词放入map当中,用到Collections的sort方法,以第二个参数对象的方法来比较大小,注意的是map当中的每一个元素都是Map.Entry<String, Integer>类型,如下定义:
ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
其中map.entrySet()的源代码:
@return a set view of the mappings contained in this map
Set<Map.Entry<K, V>> entrySet();
面向对象设计大作业-改进
7.1 完善图形界面(说明与上次作业相比增加与修改了些什么)
答:因为上周的是只有唯一的账号和密码,功能比较单一,可以增加一个注册的功能,将这些信息保存在集合列表中,比如用映射,在输出商品信息时,我用的是文本框域,这周考虑使用JTable来改进,而且发现每次登陆了账号,购物车就要重新new一个,还是有很多不足的地方
7.2 使用集合类改进大作业
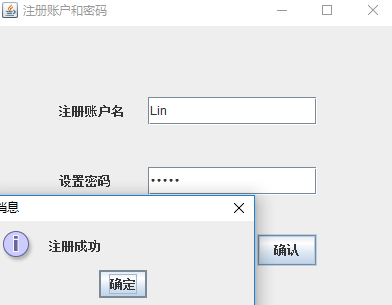
- 新添加注册的功能:
- 用JTable列表来显示信息:
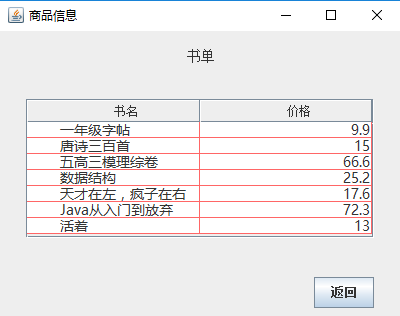
- 购物车的列表:
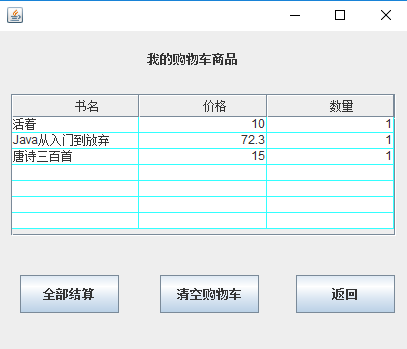
新增的用map映射来保存信息
Map<String, String> map = new HashMap<String, String>();//账户和密码一一对应
Map<String,Cart> mapcart = new HashMap<String, Cart>(); //每个账户有独立的购物车,也存在映射
ArrayList<Goods> list=new ArrayList<Goods>();
public Shopping() {
new Login().setVisible(true);
}
将list当中的商品在列表中显示出来:
public void push(ArrayList<Goods> g){
for (int i = 0; i < g.size(); i++) {
jTable1.setValueAt(g.get(i).getName(),0,1);
jTable1.setValueAt(g.get(i).getPrice(),0,2);
jTable1.setValueAt(g.get(i).getNumber(),0,3);
}
}
这次相对上次有了挺大改进,但是仍存在bug尚未解决,毕竟能力有限...
参考资料:
JTable参考项目
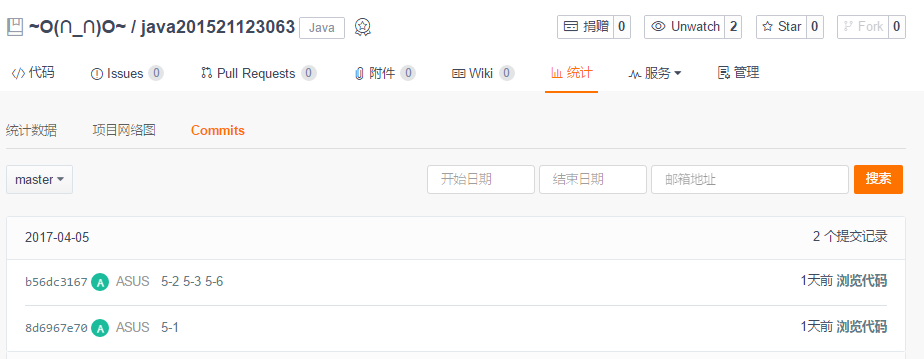
3. 码云上代码提交记录及PTA实验总结
题目集:jmu-Java-05-集合
3.1. 码云代码提交记录
在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图