一.scrapy暂停与重启
1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息:
scrapy crawl spider_name -s JOBDIR=dir/001——spider_name是你要爬取得spider的py文件名,JOBDIR是命令参数,即代表存放位置参数,dir是中间信息要保存的目录,001新生成的文件夹名是保存的中间信息,重启则读取该文件信息。可以将JOBDIR 设置在setting中,或写在custom_settings中,在Pycharm中都会执行,但是在Pycharm中无法发送ctrl+c,即无法将进程放入后台并暂停。
2.执行命令:scrapy crawl jobbole -s JOBDIR=jobs/001
2.1有可能会报以下错误,这是因为未进入到项目目录(crawl会搜索scrapy.cfg文件):

2.2进入目录正常运行后,ctrl+c暂停进程:
会在jobs下生成一个001文件夹生成如下图文件,request.seen是保存的已经访问了的url,spider.state是spider的状态信息,request.queue中有active.json和p0两个文件,p0是还需要继续做的request(跑完该文件就没有了)


3.重启(也是执行scrapy crawl jobbole -s JOBDIR=jobs/001):
会读取相关信息并继续执行,p0文件会减小,request.seen文件会增大(读取新的request,存入url),两次ctrl+c强制关掉,若需从新爬则可以指定新的文件夹,如jobs/002.
二.scrapy去重原理
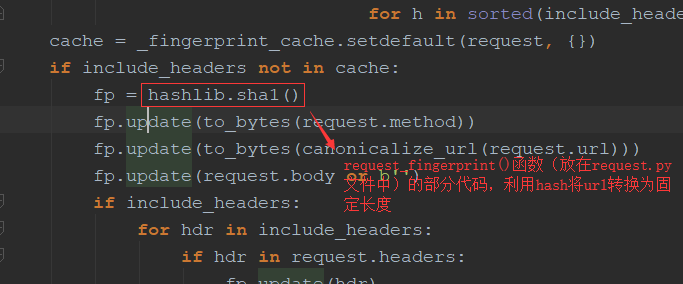
对于每一个url的请求,调度器都会根据请求得相关信息加密(request_fingerprint)得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。

三.telnet的简单使用
1.telnet简介:
Scrapy配有内置的telnet控制台,用于检查和控制Scrapy运行过程。telnet控制台只是在Scrapy进程中运行的常规python shell,所以你可以从中做任何事情。
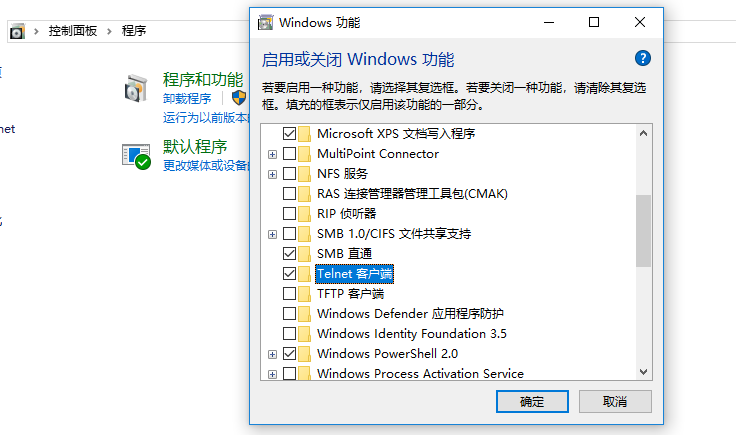
2.windows打开telnet客户端和服务端:
3.telenet连接:
telnet控制台侦听TELNETCONSOLE_PORT设置中定义的TCP端口 ,默认为6023,如下:
telenet localhost 6023
4.telenet简单使用(相当于一个python终端):
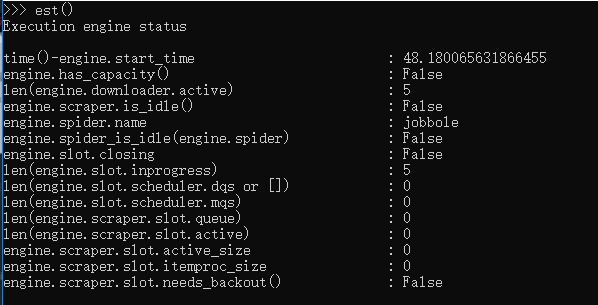
变量: