一.Selenium介绍
1.Selenium(浏览器自动化测试框架):
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
2.Selenium框架图:
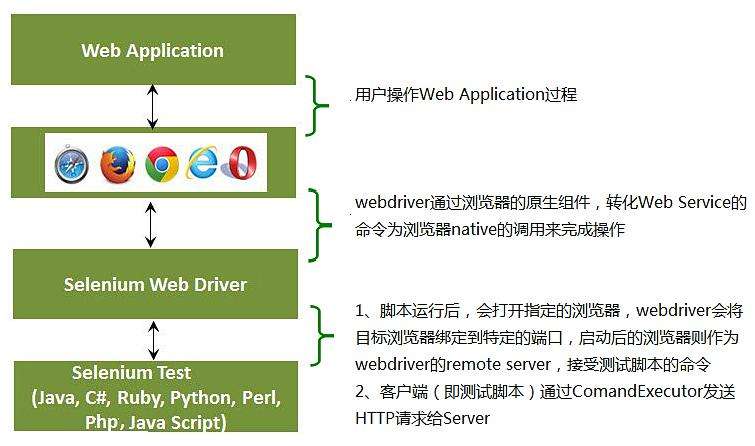
二.Selenium的安装和简单使用:
1.安装:(官方文档:https://selenium-python.readthedocs.io/api.html)
pip install selenium或使用安装包
2.浏览器的安装(若没在环境变量中,请下载):

3.简单使用Selenium:
3.1简单获取百度网页并退出(会弹出浏览器模拟操作):
from selenium import webdriver from scrapy.selector import Selector # 打开谷歌浏览器 # 若没将浏览器Chrome的exe文件添加到PATH下,则带参数指定浏览exe文件的位置 # brower=webdriver.Chrome(executable_path='....') # 添加在PATH下自动找取 brower = webdriver.Chrome() # 获取的是js和css文件加载完后的网页,而不是该网页源代码 brower.get('https://www.baidu.com/') # 获取js和css加载完后的网页 print(brower.page_source) ''' selenium提供了很多提取网页内容的方法,如下等,但是selenium是用纯python写的, 提取效率慢,若知是提取内容,建议用scrapy,模拟输入密码和点击时用selenium的方法 brower.find_element_by_css_selector() brower.find_elements_by_css_selector() ...... ''' #利用scrapy的selector解析,速度更快 t_select=Selector(text=brower.page_source) ...... # 退出 brower.quit()
3.2模拟登录微博:
from selenium import webdriver import urllib browser = webdriver.Chrome() browser.get('https://weibo.com/') import time time.sleep(10) username = browser.find_element_by_css_selector('#loginname') passwd=browser.find_element_by_css_selector('input[node-type="password"]') if username: username.send_keys('yourphone') else: print('未找到用户名输入框!!!标签错误') if passwd: passwd.send_keys('yourpasswd') else: print('未找到密码输入框!!!标签错误') yanzhengma=browser.find_element_by_css_selector('.code.W_fl img') if yanzhengma: #获取验证码图片下载地址并下载到本地 img_url=yanzhengma.get_attribute('src') data = urllib.request.urlopen(img_url).read() f = open('weibo.png' , 'wb') f.write(data) f.close() code_input=browser.find_element_by_css_selector('input[node-type="verifycode"]') #可以使用打码平台或自动识别验证码 codes=input('请输入截图里的验证码:') code_input.send_keys(codes) browser.find_elements_by_css_selector('a[node-type="submitBtn"]')[0].click()
3.3selenium实现页面滚动下拉:
from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.oschina.net/blog') #执行js代码,可以设定下拉到底部或某个位置等 for i in range(3): #下拉三次 browser.execute_script( "window.scrollTo(0,document.body.scrollHeight); var lenofPage=document.body.scrollHeight; return lenofPage;") time.sleep(3)
3.4selenium设置不加载图片(加快效率):
from selenium import webdriver #设置chromedriver不加载图片,加速页面的加载 option=webdriver.ChromeOptions() prefs={'profile.managed_default_content_settings.images':2} option.add_experimental_option("prefs",prefs) browser=webdriver.Chrome(chrome_options=option) browser.get('https://www.taobao.com/')
3.5phantomjs的简单使用(无界面的浏览器,速率快,但多进程情况下性能下降很严重):
注:selenium3.11.0及以上版本不在支持phantomjs,若需使用则要安装旧版的selenium(pip3 uninstall selenium 安装历史版本:pip3 install selenium==3.10.0或更旧的版本)
from selenium import webdriver browser = webdriver.PhantomJS(executable_path='E:/phantomjs-2.1.1-windows/bin/phantomjs.exe') browser.get('https://www.cnblogs.com/lyq-biu/p/9753969.html') print(browser.page_source)
3.6selenium集成到scrapy(若要使用,记得在setting中添加到中间件):
注:scrapy本身是异步的,经过这样的selenium集成会变成同步的,会降低速率,若想集成仍是异步的,则需重写downloader。参考:https://github.com/flisky/scrapy-phantomjs-downloader
#第一种
from selenium import webdriver from scrapy.http import HtmlResponse class SeleniumMiddleware(object): #通过selenium请求动态网页 def process_request(self,request,spider): #spider的名字是jobbole才使用selenium方法 if spider.name=='jobbole': #请求一次打开一个窗口,很慢 browser=webdriver.Chrome() browser.get(request.url) return HtmlResponse(url=request.url,body=browser.page_source)
#第二种 from selenium import webdriver from scrapy.http import HtmlResponse class SeleniumMiddleware(object): # 通过selenium请求动态网页 def __init__(self): #使用一个Chrome,return之后无法关闭,则初始化可以放入spider中,调用spider.close()关闭 self.browser = webdriver.Chrome() super(SeleniumMiddleware, self).__init__() def process_request(self, request, spider): if spider.name == 'jobbole': self.browser.get(request.url) return HtmlResponse(url=request.url, body=self.browser.page_source)
#第三种 from scrapy.xlib.pydispatch import dispatcher from scrapy import signals ...... class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts'] def __init__(self): self.browser = webdriver.Chrome() super(JobboleSpider, self).__init__() #分发给spider_close,使用信号量spider_closed dispatcher.connect(self.spider_close,signals.spider_closed ) def spider_close(self): #爬虫退出时关闭Chrome self.browser.quit() ......
class SeleniumMiddleware(object): # 通过selenium请求动态网页 def process_request(self, request, spider): if spider.name == 'jobbole': # browser=webdriver.Chrome() spider.browser.get(request.url) return HtmlResponse(url=request.url, body=spider.browser.page_source)
3.7pyvirtualdisplay的简单使用(无界面):
安装:pip install pyvirtualdisplay
from selenium import webdriver from pyvirtualdisplay import Display #设置无界面,windows环境下不适用 display=Display(visible=0,size=(800,600)) display.start() browser=webdriver.Chrome() browser.get('https://i.cnblogs.com/EditPosts.aspx?postid=9753969&update=1') ...... browser.quit() display.stop()
3.8scrapy-splash,selenium grid,splinter
三.总结:
有很多模拟浏览器操作的插件,而selenium用纯Python写的,效率较慢,但使用方便,是一个很好的测试框架,它的selenium支持分布式。