一.本章要点
- 文法定义中的二选一、拼接、选项和重复在Scala组合子解析器中对应|、~、opt和rep
- 对于RegexParsers而言,字符串字面量和正则表达式匹配的是词法单元
- 用^^来处理解析结果
- 在提供给^^的函数中使用模式匹配来将~结果拆开
- 用~>或<~来丢弃那些在匹配后不再需要的词法单元
- repsep组合子处理那些常见的用分割符分割开的条目
- 基于词法单元的解析器对于解析器那种带有保留字和操作符的语言很有用。准备好定义你自己的词法分析器
- 解析器是消费读取器并产出解析结果:成功、失败或错误的函数
- Failure结果提供了用于错误报告的明细信息
- 可能想要添加failure语句到文法当中来改进错误提示的质量
- 凭借操作符号、隐式转换和模式匹配,解析器组合子类库让任何能理解无上下文文法的人都可以很容易地编写解析器
二.文法
一组用于产出所有遵循某个特定结构的字符串的规则。
更高效的方法:在解析开始前收集好数字(词法分析),词法分析器会丢弃掉空白和注释并形成词法单元——标识符、数字和符号。
注:op和expr不是词法单元,它们是结构化的元素,是文法的作者创造出来的,目地是产出正确的词法单元序列(非终结符号)。。。
三.组合解析器操作
为了使用Scala解析库,需要提供一个扩展自Parsers特质的类定义那些有基本操作组合起来的解析操作。。。
四.解析结果变换
将中间输出变换成有用的形式。。。
五.丢弃词法单元
对于解析来说。词法单元是必需的,但在匹配之后可以被丢弃掉。(使用~>和<~匹配丢弃)。。。
六.生成解析树
在构建解释器或者编译器时,会想要构建一棵解析树(通常用样例类来实现)。
七.避免左递归
如果解析器在解析输入之前就调用自己的话,就会一直递归下去。。。
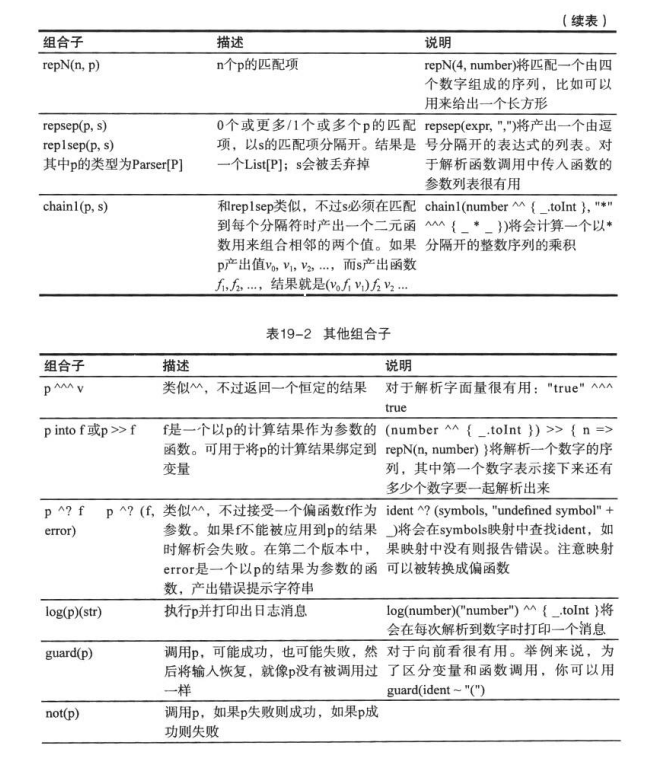
八.更多的组合子
rep方法匹配零个或多个重复项。。。


九.避免回溯
p|q被解析而p失败时,解析器会用同样的输入尝试q,这样的回溯效果很低效,使用~!表示不需要回溯(p~!q)
十.记忆式解析器
使用一个高效的解析算法,该算法会捕获到之前的结果,好处:解析时间可以确保与输入长度成比例的关系解析器可以接受左递归语法。。。
使用解析器:

十一.解析器到底是什么
Parser[T]是一个带有单个参数的函数,参数类型为Reader[Elem],而返回值的类型为ParseResult[T]。解析器都扩展自RegexParsers,该特质有一个从Regex到Parser[String]的隐式转换。。。
十二.正则解析器
RegexParsers特质在我们到目前为止的所有解析器示例中都用到了,提供了两个用于定义解析器的隐式转换:
Literal从一个字符串字面量(比如”+“)做出一个Parser[String];
regex从一个正则表达式(比如”[0-9]“.r)做出一个Parser

十三.基于词法单元的解析器
基于词法单元的解析器使用Reader[Token]而不是Reader[Char]。Token类型定义在特质scala.util.parsing.token.Token特质中。StdToken子特质中定义了四种解析编程语言时遇到的词法单元:Identifier(标识符),Keyword(关键字),NumbericLit(数值字面量),StringLit(字符串字面量)。。。
十四.错误处理
当解析器不能呢个接受某个输入时,解析器会生成一个错误的提示,描述解析器在某个位置无法继续了。。。
十五.练习

