引自:https://zhuanlan.zhihu.com/p/147204568
方法主要有模型结构优化、模型剪枝、模型量化、知识蒸馏。
1、模型结构优化
总览各种深度学习模型,可以发现它们都是由一个个小组件组装而成,只是初期先把模型做大做强,后期落地遇到问题时,再瘦身优化。具体的优化方法依赖于具体的模型和业务,需要研究员因地制宜。上述这些优化操作都依赖于人工经验,费时费力,组合优化这种事情更适合让机器来做,于是神经网络结构搜索(NAS)技术就应运而生。
2、模型剪枝
模型剪枝的初衷就是深度学习模型的过度参数化,说白了就是你的模型太胖了,跑不动,需要减肥。根据模型剪枝的方法可以分为两大类:一类是结构化剪枝,另一类是非结构化剪枝。
所谓结构化剪枝是对参数矩阵做有规律的裁剪,比如按行或列裁剪,使得裁剪后的参数矩阵仍然是一个规则的的矩阵。结构化裁剪主流的方法有Channel-level、Vector-level、Group-level、Filter-level级别的裁剪。
非结构化剪枝是将原本稠密的参数矩阵裁剪为稀疏的参数矩阵,一般矩阵大小不变,其效果类似于参数正则化。因为目前大部分计算平台不支持稀疏矩阵的计算,只有结构化剪枝才能真正减少计算量。
模型剪枝的难点在于对“不重要”参数的定义和最优剪枝结构的搜索方法。目前主流的做法是训练一个大模型,然后根据参数权重的大小对大模型进行剪枝,去除不重要的参数,最后再对剪枝后的模型fine-tune一下。但是这种方法收敛比较慢,而且最终得到的模型不一定是最优的。
为了解决这个问题,同时避免每次剪枝后重新训练模型带来的大量计算开销,Metapruning方法设计了一个权重学习模型来学习不同网络结构对应的权重矩阵,用于评估模型搜索过程中产生的模型的好坏,从而解决了模型评估过程中模型参数训练的问题。Metapruning算法最大的创新点在于告诉我们模型参数可以直接“生成”,而不需要训练。不过比较遗憾的时,“生成”的模型参数不能直接应用于模型推理,仅供对比评估。
小结:根据业界的实践经验,非结构化模型剪枝的模型精度损失较小,但受限于底层计算框架,计算加速效果有限。而结构化模型剪枝可以较大幅度地减少模型参数,实现可观的计算加速,但容易造成明显的性能损失
3、模型量化
模型量化是通过减少表示每个权重参数所需的比特数来压缩原始网络,从而实现计算加速。
半浮点精度(FP16)和混合精度是一种常见的做法,不过需要底层计算框架支持,否则无法实现计算加速。另一种是INT8量化,即将模型的权重参数从 FP32 转换为 INT8,以及使用 INT8 进行推理。量化的加速主要得益于定点运算比浮点运算快,但从FP32量化为INT8会损失模型精度。
在我们的直观印象中,神经网络模型的权重参数一般都是位于0附近的很小的数值,权重参数的分布大概如下图所示。而量化不会改变权重参数的分布,只是将权重参数从一个值域映射到另一个值域,过程类似于数值的归一化。整个量化的思想很简单,后续的研究都是围绕如何提高量化后的模型的准确度。
 图2:深度神经网络权重参数分布示例图
图2:深度神经网络权重参数分布示例图
采用普通量化方法时,靠近零的浮点值在量化时没有精确地用定点值表示。因此,量化后的模型预测准确度会显著下降,如均一量化,会将具有动态值密度的浮点映射成具有恒定值密度的定点。其中一种的做法是在量化过程中做值域调整。
值域调整的目标是学习能在量化后更准确地运行网络的超参数 min/max,即归一化参数。根据调整的时机,可以进一步划分为训练后量化和训练时量化,代表分别为 Nvidia Calibration 和 TensorFlow Quantization-aware Training。
除了上述常规量化操作,还有一些比较特殊的量化网络,如二进制神经网络、三元权重网络、XNOR网络。这些神经网络以更少的位数来表示权重参数,比如二进制神经网络是具有二进制权重和激活的神经网络,即网络权重只有1和-1,和量化不一样的地方在于这二值权重参数是通过训练时候的梯度优化得到,而不是从FP32量化得到。
小结:量化技术适用场景较广,加速效果明显。此外,对于精度敏感的模型,还可以通过精度补偿的操作来进一步优化量化模型的效果。
3、知识蒸馏
模型蒸馏本质上和迁移学习类似,只是它还多了一个模型压缩的目的,即通过模型蒸馏,将大模型压缩为小模型,使小模型可以跑得又快又好。所以,最基本的想法就是将大模型学习得到的知识作为先验,将先验知识传递到小规模的神经网络中,并在实际应用中部署小规模的神经网络。在实际研究中,我们将大模型称为Teacher,小模型称为Student,模型蒸馏的过程就是让Student去学习Teacher的知识。目前大部分模型蒸馏框架都是基于Teacher-Student的模式,只是有些方法会请多几个Teacher或者配个Assistant。模型蒸馏的依据主要有三点:
- Teacher可以从大量数据中学习数据结构间的相似性
- Student可以利用Teacher学习到的知识作为先验,加速模型的收敛
- Softmax函数随着温度变量(temperature)的升高分布更均匀
数据结构的结构间相似是指相似样本之间的预测值接近,所以大部分模型蒸馏方法都会让Student去学习Teacher的logit输出,而不是实际的预测值(实际预测值不能度量样本间的相似性)。Teacher的先验知识直观上理解就是模型中间层的输出,即Teacher处理数据的方式。这一点跟迁移学习很像,差异点在于模型蒸馏是要让Student模型也学会处理类似的数据,并得到类似的输出,而迁移学习一般是直接利用Teacher模型提供的参数或中间输出。正所谓授人以鱼不如授人以渔。
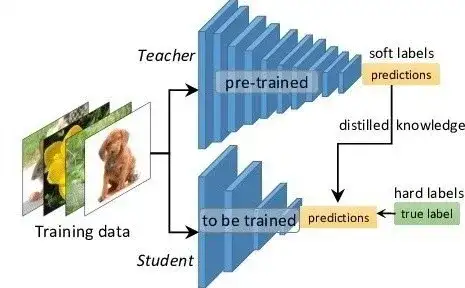
图3:Teacher-Student模型蒸馏基础框架
基于Teacher-Student蒸馏框架,不同蒸馏方法的差异主要体现在让Student模型学什么,如何学。
对比表征蒸馏让Student模型学习一个表征(representation),这个表征在某些度量空间下正样本对紧密靠近,同时负样本对尽量分离,解决跨模态蒸馏的问题。
多步蒸馏则认为Teacher模型和Student模型差异比较大时,Student模型学不好,因此需要引入一个助教传递知识。
多任务蒸馏利用多个BERT模型担任Teacher,教Student模型处理多任务问题。这时,Student模型的目标函数就变为多个任务的loss求和,每个训练batch数据也会从多个任务中随机采样得到。
TinyBERT利用Two-stage方法,分别对预训练阶段和精调阶段的BERT进行蒸馏,并且不同层都设计了损失函数,是目前为止效果最好的模型。
小结:模型蒸馏技术是通过用小模型替代大模型来实现推理阶段的加速,适用于推理阶段的加速。而在训练阶段,由于需要预训练大模型,还需要付出额外的计算开销。
加速深度学习模型训练速度最有效的方法便是增加计算资源,将单机训练的模型扩展为多机训练。目前各大主流框架的多GPU分布式训练一般存在两种模式:模型并行和数据并行。