引自:https://blog.csdn.net/God_68/article/details/81747297?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
四、SVM算法
1、SVM基本原理
SVM是一种有监督的统计学习方法,能够最小化经验误差和最大化几何边缘,被称为最大间隔分类器,可用于分类和回归分析。
SVM理论提供了一种避开高维空间的复杂性,直接使用此空间上的内积函数(核函数),再利用在线性可分的情况下的求解方法直接求解对应的高维空间的决策问题。当核函数已知时,可以简化高维空间问题的求解难度。
SVM是个机器学习过程,在高维空间中寻找一个分类超*面,将不同类别的数据样本点分开,使不同类别的点之间的间隔最大,该分类超*面即为最大间隔超*面,对应分类器称为最大间隔分类器。针对二分类问题,下图可以直观地描述SVM的空间特征。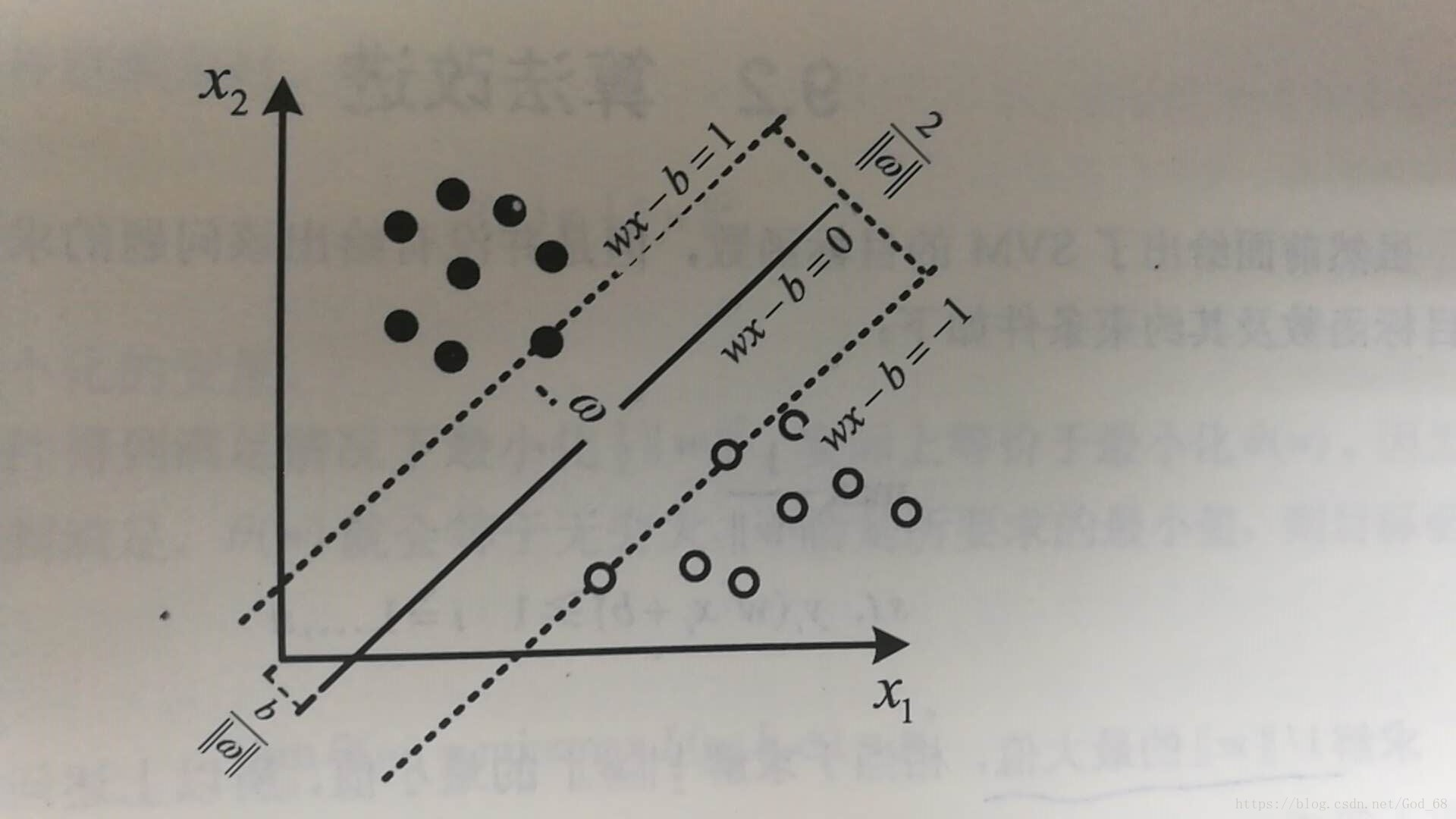
假设数据样本为 ,分类超*面可以表达为:
其中,x 为分类超*面上的点;w 为垂直于分类超*面的向量;b 为位移量,用于改善分类超*面的灵活性,超*面不用必须通过原点。
两个分类超*面之间具有最大间隔,需要知道训练样本中的支持向量、距离支持向量最*的*行超*面,这些*行超*面可以表示为:
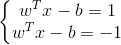
其中,w 为分类超*面的法向量,长度未定;1 和 -1 只是为了计算方便而取的常量,其他常量只要互为相反数即可。
如果给定的训练样本是线性可分的,那么就可以找到两个间距最大的*行超*面,并且这两个超*面之间没有任何训练样本,它们之间的距离为。所以最小化,就可以使这两个超*面之间的间隔最大化。
为了使所有训练样本点在上述两个*行超*面间隔区域之外,我们需要确保所有的训练数据样本点 ,都满足以下条件之一,即
最后总结一下SVM算法的优缺点:
1、SVM算法的优点
可以解决小样本情况下的机器学习问题;
可以提高泛化性能;
可以处理高维空间数据;
可以解决非线性问题。
2、SVM算法的缺点
对于线性问题没有通用的解决方案,必须谨慎选择核函数;
在选择合适的核函数之后,在处理分类问题时,要求解函数的二次规划,而在这过程中,需要大量的存储空间。