什么是混淆矩阵:
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总。
这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)
如图:

混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的 预测类别,每一列代表实例的真实类别。
代码详解:
打印混淆矩阵
#鸢尾花跑混淆矩阵
from sklearn.datasets import load_iris
import pydotplus
from IPython.display import Image #直接绘图在jupyter
import graphviz
from sklearn import tree
from sklearn.model_selection import train_test_split
#训练模型 提取鸢尾花数据
iris = load_iris()
# print(iris)
dataset_X = iris.data
dataset_Y = iris.target
train_X,test_X,train_Y,test_Y = train_test_split(dataset_X,dataset_Y,test_size=0.2)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(train_X,train_Y)
# print(train_Y)
predict_test_y=clf.predict(test_X)
press = predict_test_y.reshape(-1,3)
# print(predict_test_y)
将打印的混淆矩阵可视化以及绘图
from matplotlib import pyplot as plt
%matplotlib inline
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix
con_matrix = confusion_matrix(y_pred=predict_test_y,y_true=test_Y)
# print(y_pre.shape)
# print(dataset_y.shape)
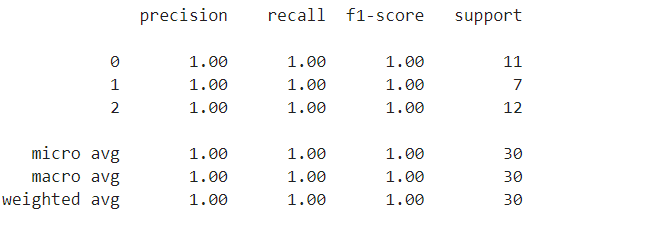
print(con_matrix) #查看混淆矩阵
# 可视化混淆矩阵
def plot_confusion_matrix(confusion_mat):
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
thresh = confusion_mat.max() / 2.
for i, j in itertools.product(range(confusion_mat.shape[0]), range(confusion_mat.shape[1])):
plt.text(j, i, confusion_mat[i, j],
horizontalalignment="center",
color="white" if confusion_mat[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(con_matrix)
计算混淆矩阵的准确率,精确率,召回率,f1
from sklearn.model_selection import cross_val_score
print('准确率:{}'.format(cross_val_score(clf,test_X,test_Y,scoring='accuracy',cv=6).mean()))
print('精确率:{}'.format(cross_val_score(clf,test_X,test_Y,scoring='precision_weighted',cv=6).mean()))
print('召回率:{}'.format(cross_val_score(clf,test_X,test_Y,scoring='recall_weighted',cv=6).mean()))
print('f1:{}'.format(cross_val_score(clf,test_X,test_Y,scoring='f1_weighted',cv=6).mean()))
实现结果

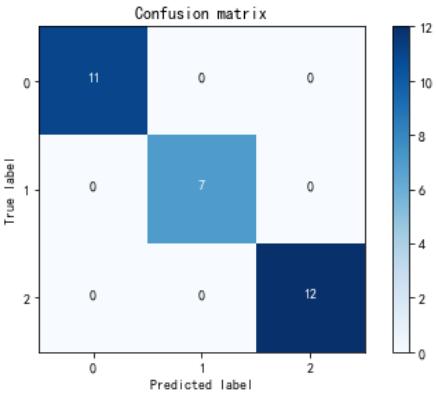
查看分类型报告
from sklearn.metrics import classification_report
print(classification_report(y_pred=predict_test_y,y_true=test_Y))
#support:原数据类别个数
显示效果: