TensorBoard可视化
0. 写在前面
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
工具
python3.5.1,pycharm
1. TensorBoard简介
一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出的功能。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test1.py
@time: 2019/5/10 9:27
@desc: TensorBoard简介。一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出的功能。
"""
import tensorflow as tf
# 定义一个简单的计算图,实现向量加法的操作。
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
input2 = tf.Variable(tf.random_uniform([3], name="input2"))
output = tf.add_n([input1, input2], name="add")
# 生成一个写日志的writer,并将当前的TensorFlow计算图写入日志。TensorFlow提供了
# 多种写日志文件的API,在后面详细介绍。
writer = tf.summary.FileWriter('./log/', tf.get_default_graph())
writer.close()
运行之后输入:tensorboard --logdir=./log查看TensorBoard。
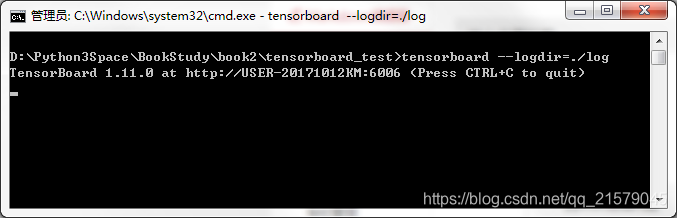
然后在浏览器中输入下面的网址。
2. TensorFlow计算图可视化
2.1 命名空间与TensorBoard图上节点
tf.variable_scope与tf.name_scope函数的区别
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test2.py
@time: 2019/5/10 10:26
@desc: tf.variable_scope与tf.name_scope函数的区别
"""
import tensorflow as tf
with tf.variable_scope("foo"):
# 在命名空间foo下获取变量"bar",于是得到的变量名称为“foo/bar”。
a = tf.get_variable("bar", [1])
# 输出:foo/bar: 0
print(a.name)
with tf.variable_scope("bar"):
# 在命名空间bar下获取变量“bar”,于是得到的变量名称为“bar/bar”。此时变量
# “bar/bar”和变量“foo/bar”并不冲突,于是可以正常运行。
b = tf.get_variable("bar", [1])
# 输出:bar/bar:0
with tf.name_scope("a"):
# 使用tf.Variable函数生成变量会受到tf.name_scope影响,于是这个变量的名称为“a/Variable”。
a = tf.Variable([1])
# 输出:a/Variable:0
print(a.name)
# tf.get_variable函数不受tf.name_scope函数的影响。
# 于是变量并不在a这个命名空间中。
a = tf.get_variable("b", [1])
# 输出:b:0
print(a.name)
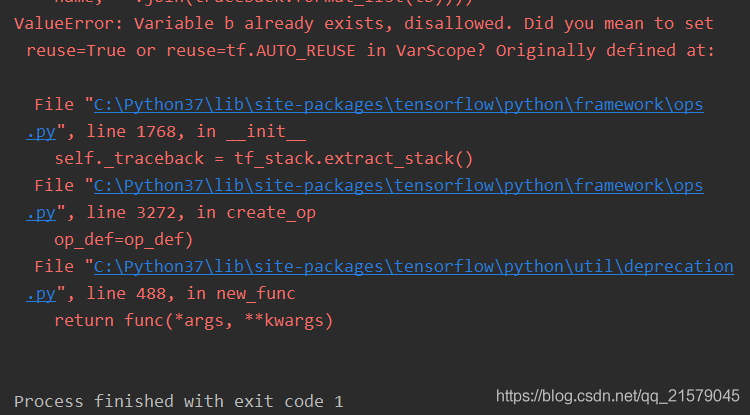
with tf.name_scope("b"):
# 因为tf.get_variable不受tf.name_scope影响,所以这里试图获取名称为
# “a”的变量。然而这个变量已经被声明了,于是这里会报重复声明的错误
tf.get_variable("b", [1])
对不起,这一段代码,我知道作者想要表达什么意思。。。但我实在是觉得不知所云。
改进向量相加的样例代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test3.py
@time: 2019/5/10 10:41
@desc: 改进向量相加的样例代码
"""
import tensorflow as tf
# 将输入定义放入各自的命名空间中,从而使得TensorBoard可以根据命名空间来整理可视化效果图上的节点。
with tf.name_scope("input1"):
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
with tf.name_scope("input2"):
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("./log", tf.get_default_graph())
writer.close()
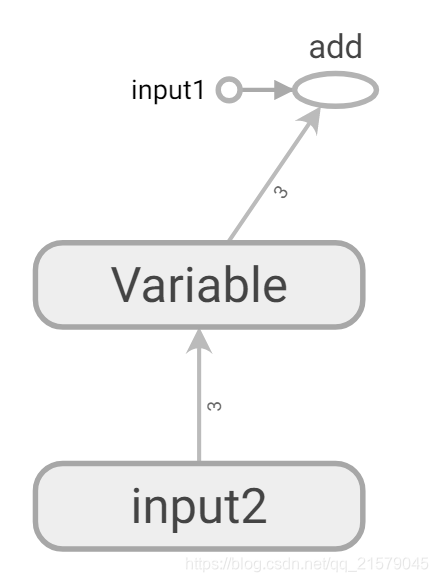
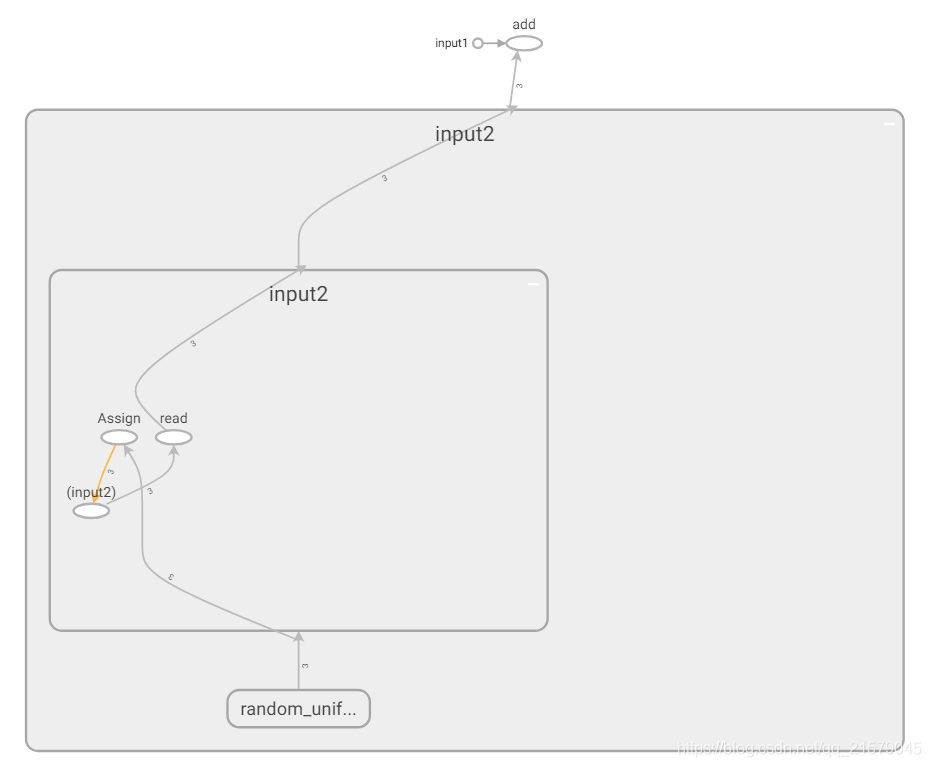
得到改进后的图:
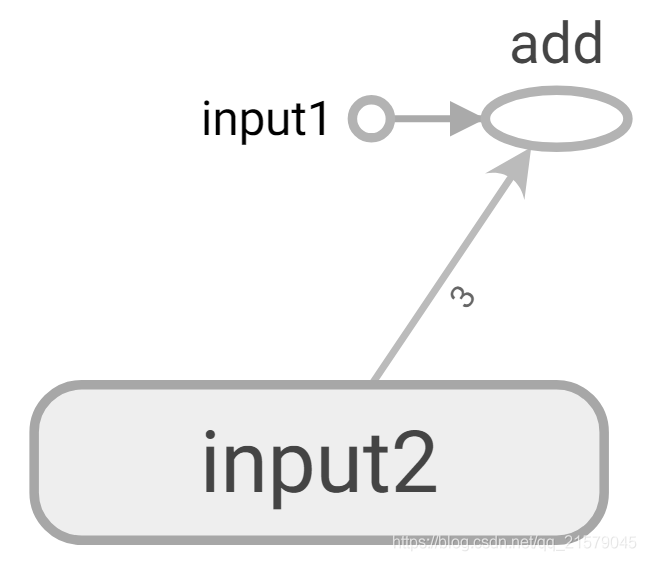
展开input2节点的可视化效果图:
可视化一个真实的神经网络结构图
我是真的佛了。。。这里原谅我真的又要喷。。。首先是用之前的mnist_inference文件就已经炸了,然后下面还有一句跟前面一样的方式训练神经网络。。。我特么。。。。你你听,这说的是人话吗?我已经无力吐槽了。。。这本书用来作为我的TensorFlow启蒙书,真的是后悔死了。。。
下面的代码,依然是我自己凭借自己的理解,改后的,这本书是真的垃圾。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test4.py
@time: 2019/5/10 11:06
@desc: 可视化一个真实的神经网络结构图。
"""
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
# mnist_inference中定义的常量和前向传播的函数不需要改变,因为前向传播已经通过
# tf.variable_scope实现了计算节点按照网络结构的划分。
import BookStudy.book2.mnist_inference as mnist_inference
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名。
MODEL_SAVE_PATH = './model/'
MODEL_NAME = 'model.ckpt'
def train(mnist):
# 将处理输入数据的计算都放在名字为“input”的命名空间下。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name="y-input")
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 将处理滑动平均相关的计算都放在名为moving_average的命名空间下。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 将计算损失函数相关的计算都放在名为loss_function的命名空间下。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 将定义学习率、优化方法以及每一轮训练需要训练的操作都放在名字为“train_step”的命名空间下。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化Tensorflow持久化类。
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
# 每1000轮保存一次模型。
if i % 1000 == 0:
# 输出当前的训练情况。这里只输出了模型在当前训练batch上的损失函数大小。通过损失函数的大小可以大概了解到
# 训练的情况。在验证数据集上的正确率信息会有一个独立的程序来生成。
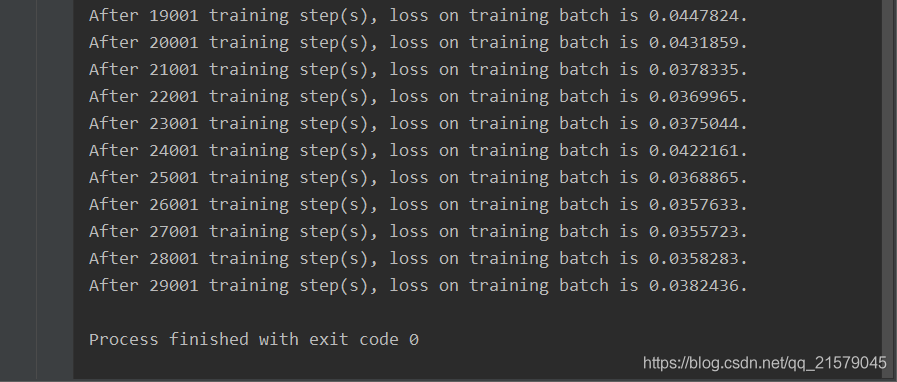
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
# 保存当前的模型。注意这里给出了global_step参数,这样可以让每个被保存的模型的文件名末尾加上训练的轮数,
# 比如“model.ckpt-1000” 表示训练1000轮之后得到的模型。
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 将当前的计算图输出到TensorBoard日志文件。
writer = tf.summary.FileWriter("./log", tf.get_default_graph())
writer.close()
def main(argv = None):
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
运行之后:
召唤tensorboard:
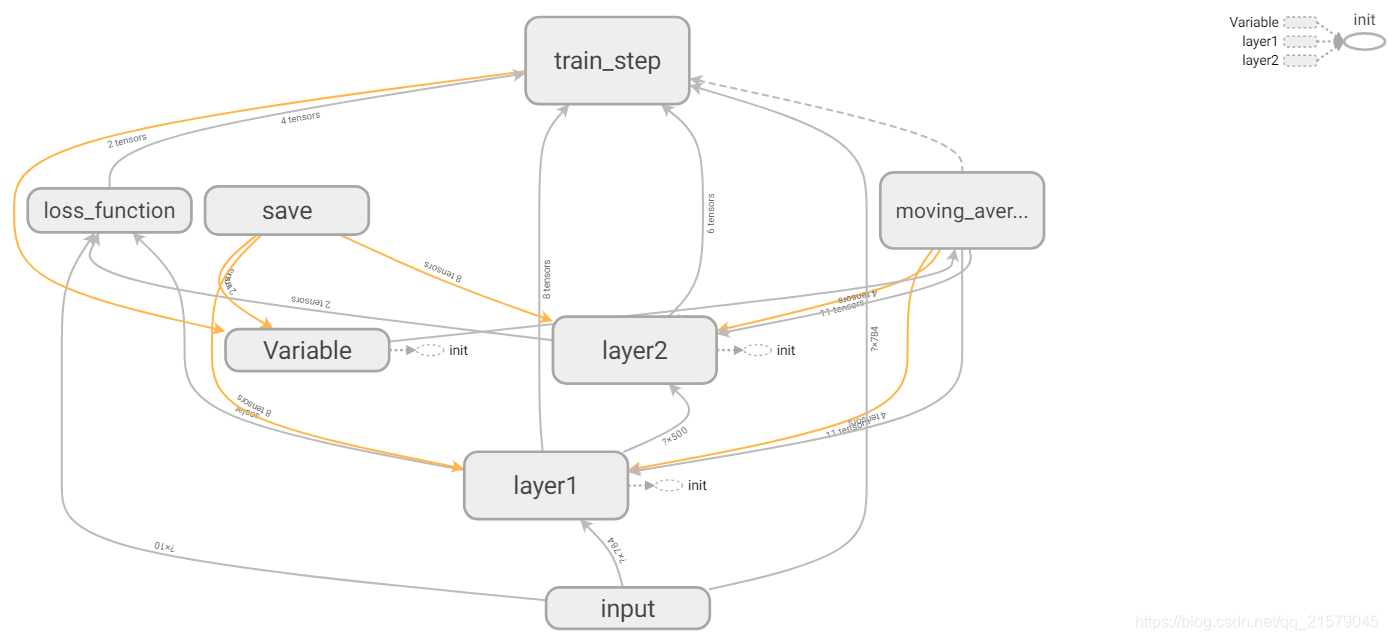
改进后的MNIST样例程序TensorFlow计算图可视化效果图:
2.2 节点信息
修改前面的代码,将不同迭代轮数的每个TensorFlow计算节点的运行时间和消耗的内存写入TensorBoard的日志文件中。
果然。。。这次又是只给出一部分代码。。。并且这个train_writer是什么啊,在哪里定义也没看到,拿来就用,真的是服了。。。(写的也太烂了,佛了,刷完这本书我就烧了。。。)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test5.py
@time: 2019/5/10 21:13
@desc: 修改前面的代码,将不同迭代轮数的每个TensorFlow计算节点的运行时间和消耗的内存写入TensorBoard的日志文件中。
"""
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
# mnist_inference中定义的常量和前向传播的函数不需要改变,因为前向传播已经通过
# tf.variable_scope实现了计算节点按照网络结构的划分。
import BookStudy.book2.mnist_inference as mnist_inference
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名。
MODEL_SAVE_PATH = './model/'
MODEL_NAME = 'model.ckpt'
def train(mnist):
# 将处理输入数据的计算都放在名字为“input”的命名空间下。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name="y-input")
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 将处理滑动平均相关的计算都放在名为moving_average的命名空间下。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 将计算损失函数相关的计算都放在名为loss_function的命名空间下。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 将定义学习率、优化方法以及每一轮训练需要训练的操作都放在名字为“train_step”的命名空间下。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化Tensorflow持久化类。
saver = tf.train.Saver()
# 将当前的计算图输出到TensorBoard日志文件。
train_writer = tf.summary.FileWriter("./log", tf.get_default_graph())
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 每1000轮保存一次模型。
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
# 将配置信息和记录运行信息的proto传入运行的过程,从而记录运行时每一个节点的时间、空间开销信息。
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys}, options=run_options, run_metadata=run_metadata)
# 将节点在运行时的信息写入日志文件。
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
# 输出当前的训练情况。这里只输出了模型在当前训练batch上的损失函数大小。通过损失函数的大小可以大概了解到
# 训练的情况。在验证数据集上的正确率信息会有一个独立的程序来生成。
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
# 保存当前的模型。注意这里给出了global_step参数,这样可以让每个被保存的模型的文件名末尾加上训练的轮数,
# 比如“model.ckpt-1000” 表示训练1000轮之后得到的模型。
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
train_writer.close()
def main(argv = None):
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
运行后:

启动TensorBoard,这样就可以可视化每个TensorFlow计算节点在某一次运行时所消耗的时间和空间。
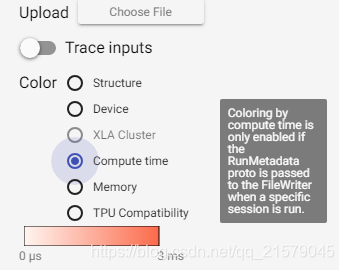

TensorBoard左侧的Color栏中Compute和Memory这两个选项将可以被选择。
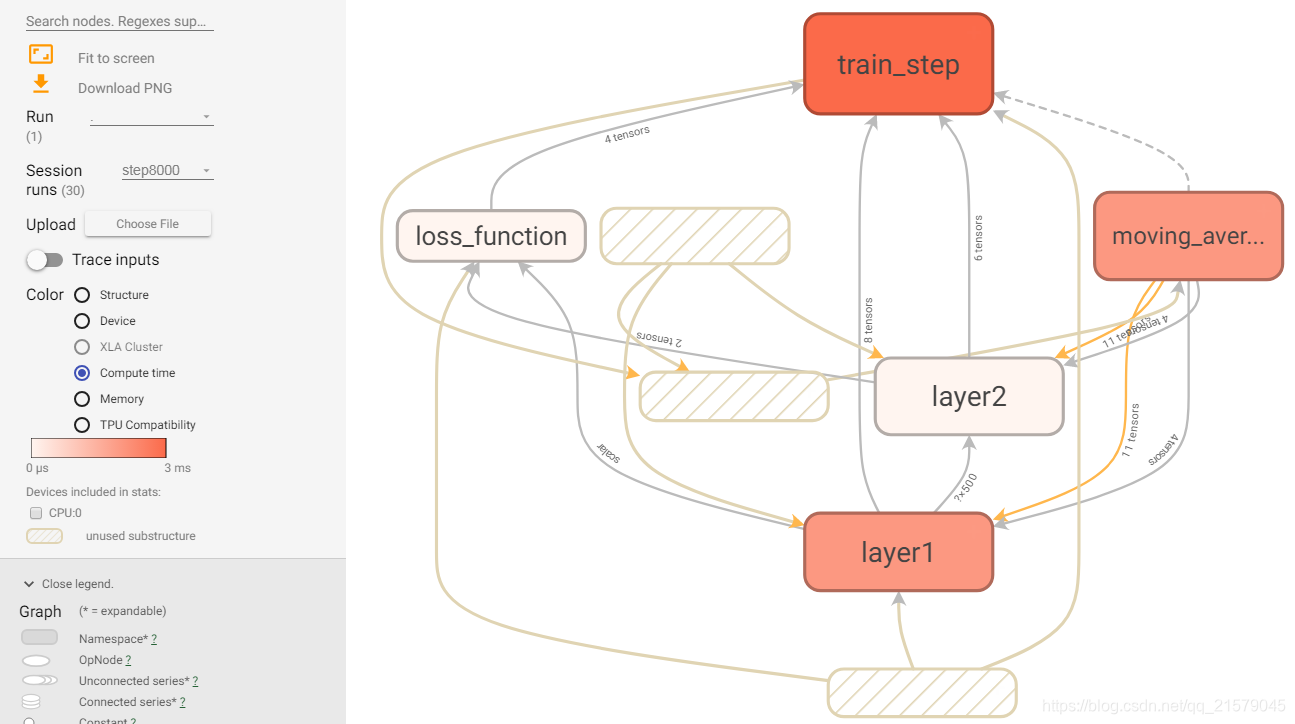
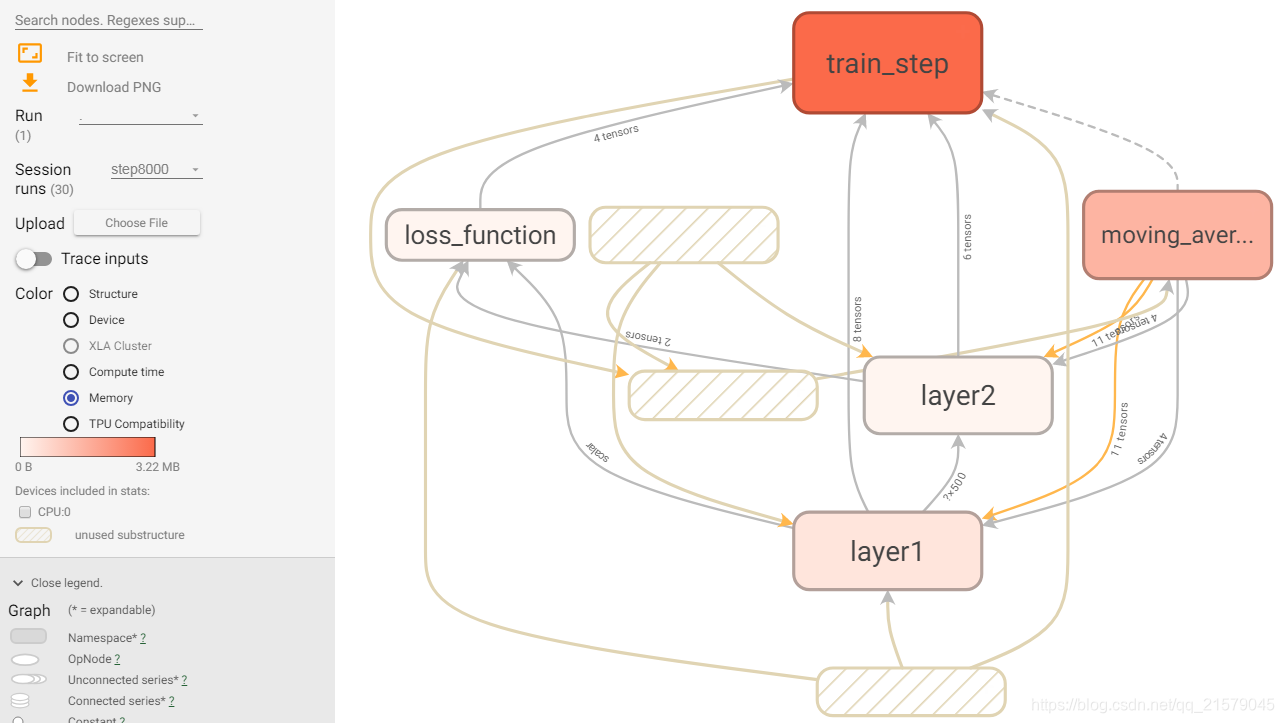
颜色越深的节点,时间和空间的消耗越大。
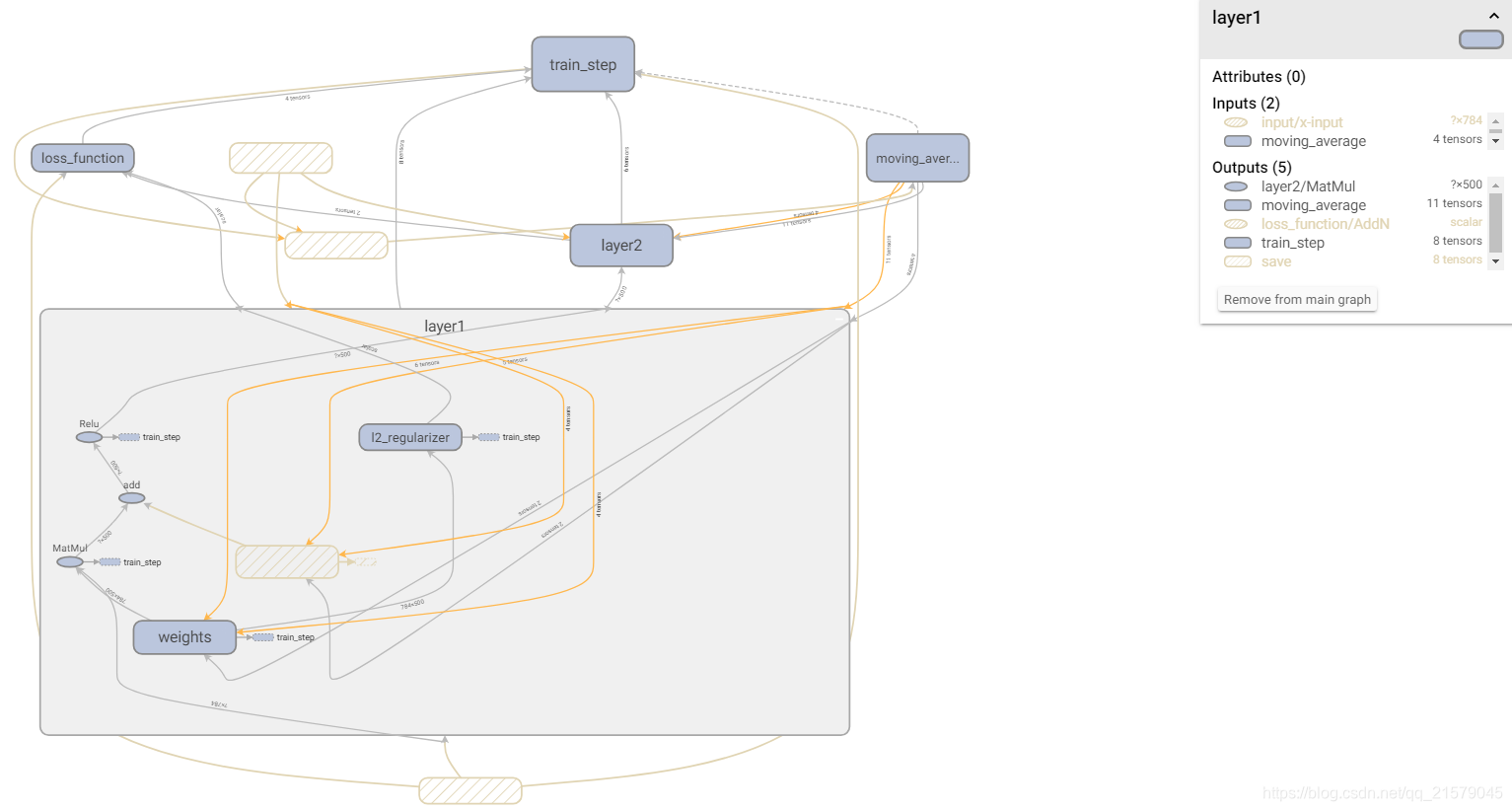
- 空心的小椭圆对应了TensorFlow计算图上的一个计算节点。
- 一个矩形对应了计算图上的一个命名空间。
3. 监控指标可视化
将TensorFlow程序运行时的信息输出到TensorBoard日志文件中。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test6.py
@time: 2019/5/11 15:27
@desc: 将TensorFlow程序运行时的信息输出到TensorBoard日志文件中。
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
SUMMARY_DIR = './log'
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# 生成变量监控信息并定义生成监控信息日志的操作。其中var给出了需要记录的张量,name给出了
# 在可视化结果中显示的图标名称,这个名称一般与变量名一致。
def variable_summaries(var, name):
# 将生成监控信息的操作放到同一个命名空间下。
with tf.name_scope('summaries'):
# 通过tf.summary.histogram函数记录张量中元素的取值分布。对于给出的图表
# 名称和张量,tf.summary.histogram函数会生成一个Summary protocol buffer。
# 将Summary写入TensorBoard日志文件后,在HISTOGRAMS栏和DISTRIBUTION栏
# 下都会出现对应名称的图标。和TensorFlow中其他操作类似。tf.summary.histogram
# 函数不会立刻被执行,只有当sess.run函数明确调用这个操作时,TensorFlow才会真正
# 生成并输出Summary protocol buffer。下文将更加详细地介绍如何理解HISTOGRAMS栏
# 和DISTRIBUTION栏下的信息。
tf.summary.histogram(name, var)
# 计算变量的平均值,并定义间生成平均值信息日志的操作。记录变量平均值信息的日志标签名
# 为'mean/' + name,其中mean为命名空间,/是命名空间的分隔符。从图中可以看出,在相同
# 命名空间中的监控指标会被整合到同一栏中。name则给出了当前监控指标属于哪一个变量。
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
# 计算变量的标准差,并定义生成其日志的操作。
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('stddev/' + name, stddev)
# 生成一层全连接层神经网络。
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在一个统一的命名空间下。
with tf.name_scope(layer_name):
# 声明神经网络边上的权重,并调用生成权重监控信息日志的函数。
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
# 声明神经网络的偏置项,并调用生成偏置项监控信息日志的函数。
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
# 记录神经网络输出节点在经过激活函数之前的分布。
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
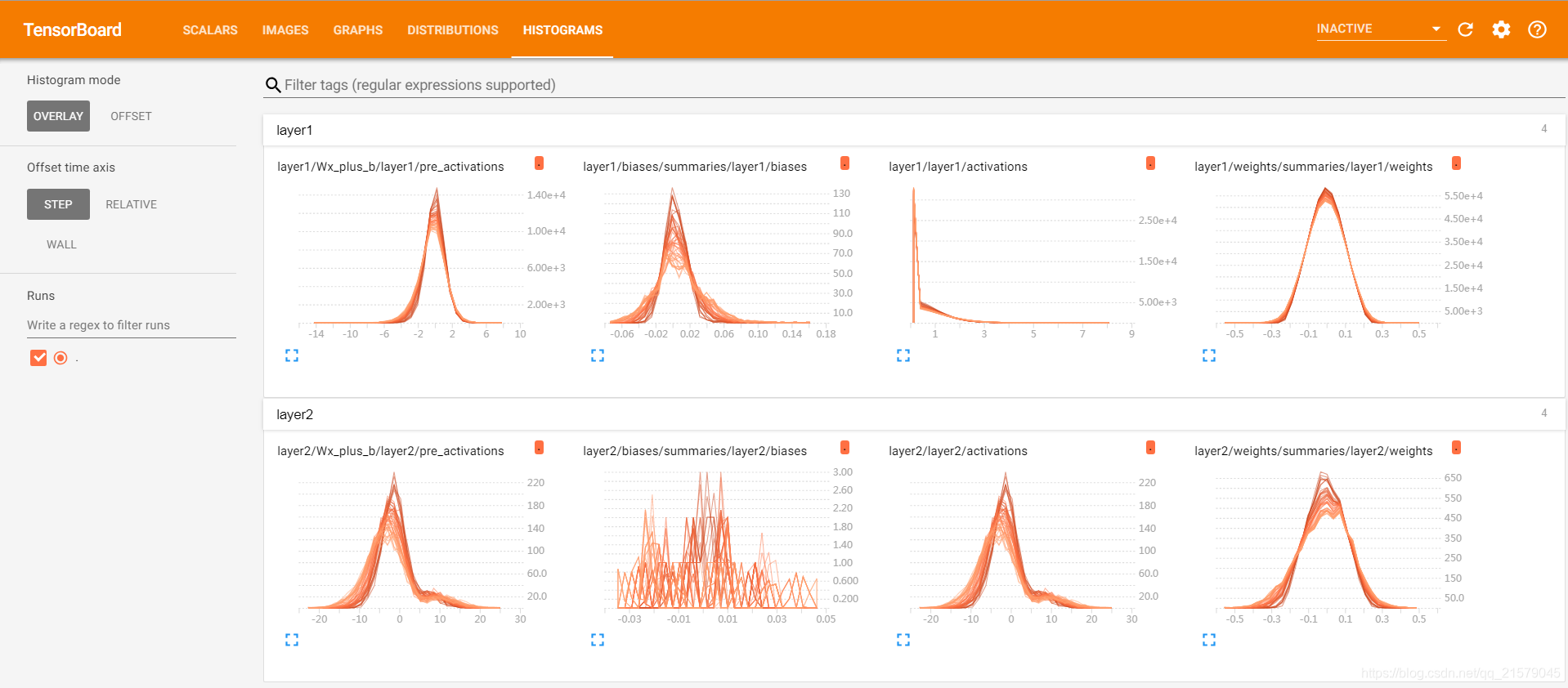
# 记录神经网络输出节点在经过激活函数之后的分布。在图中,对于layer1,因为
# 使用了ReLU函数作为激活函数,所以所有小于0的值都被设为了0。于是在激活后的
# layer1/activations图上所有的值都是大于0的。而对于layer2,因为没有使用
# 激活函数,所以layer2/activations和layer2/pre_activations一样。
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main(_):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 定义输出
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 将输入向量还原成图片的像素矩阵,并通过tf.summary.image函数定义将当前的图片信息写入日志的操作。
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
# 计算交叉熵并定义生成交叉熵监控日志的操作。
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 计算模型在当前给定数据上的正确率,并定义生成正确率监控日志的操作。如果在sess.run时
# 给定的数据是训练batch,那么得到的正确率就是在这个训练batch上的正确率;如果给定的
# 数据为验证或者测试数据,那么得到的正确率就是在当前模型在验证或者测试数据上的正确率。
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 和其他TensorFlow中其他操作类似,tf.summary.scalar、tf.summary.histogram和
# tf.summary.image函数都不会立即执行,需要通过sess.run来明确调用这些函数。
# 因为程序中定义的写日志操作比较多,一一调用非常麻烦,所以TensorFlow提供了
# tf.summary.merge_all函数来整理所有的日志生成操作。在TensorFlow程序执行的
# 过程中只需要运行这个操作就可以将代码中定义的所有日志生成操作执行一次,从而将所有日志写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前TensorFlow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将所有日志写入文件,TensorBoard程序就可以拿到这次运行所对应的运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
tf.app.run()
运行之后打开tensorboard:
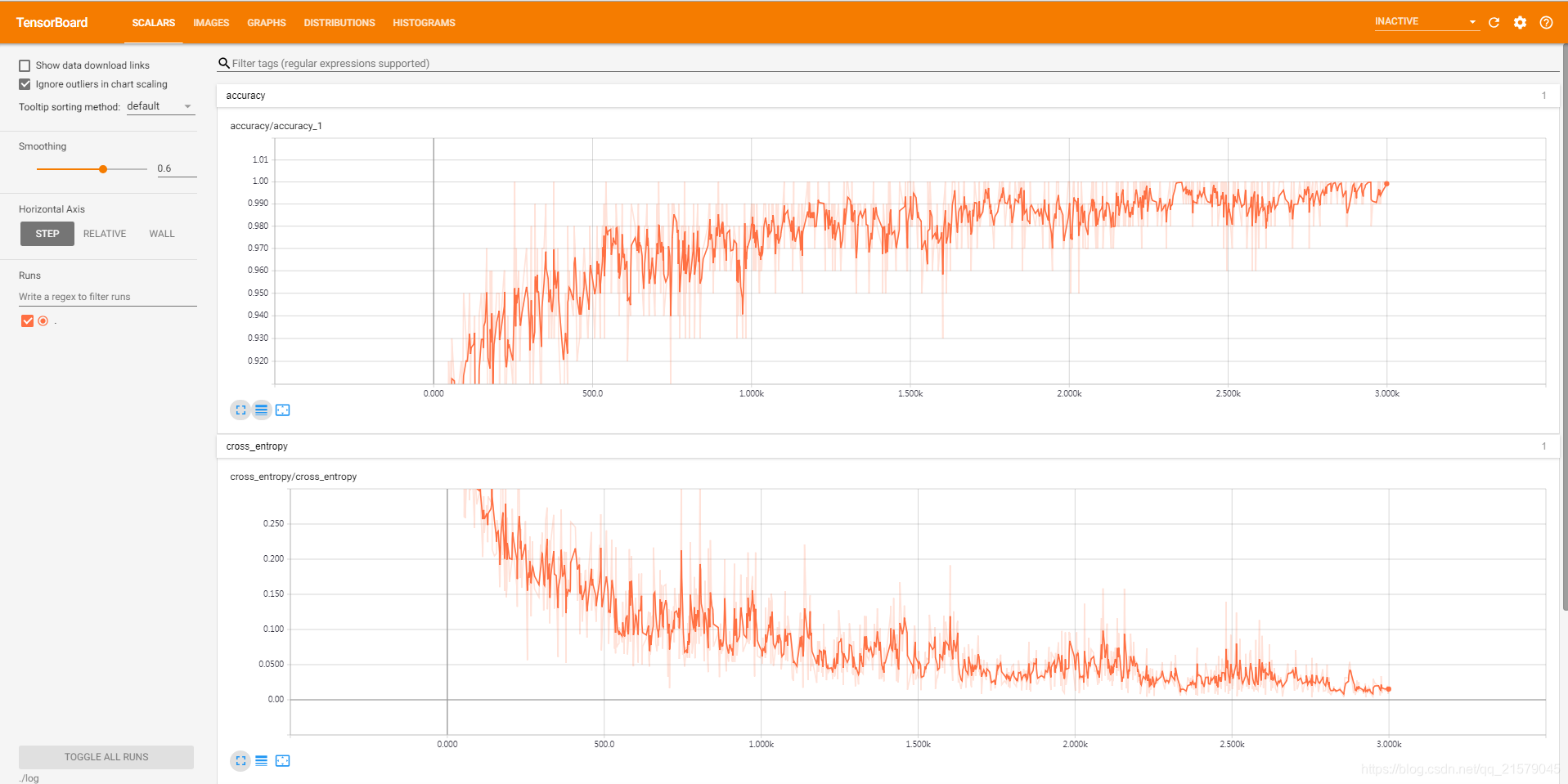
点击IMAGES栏可以可视化当前轮训练使用的图像信息。
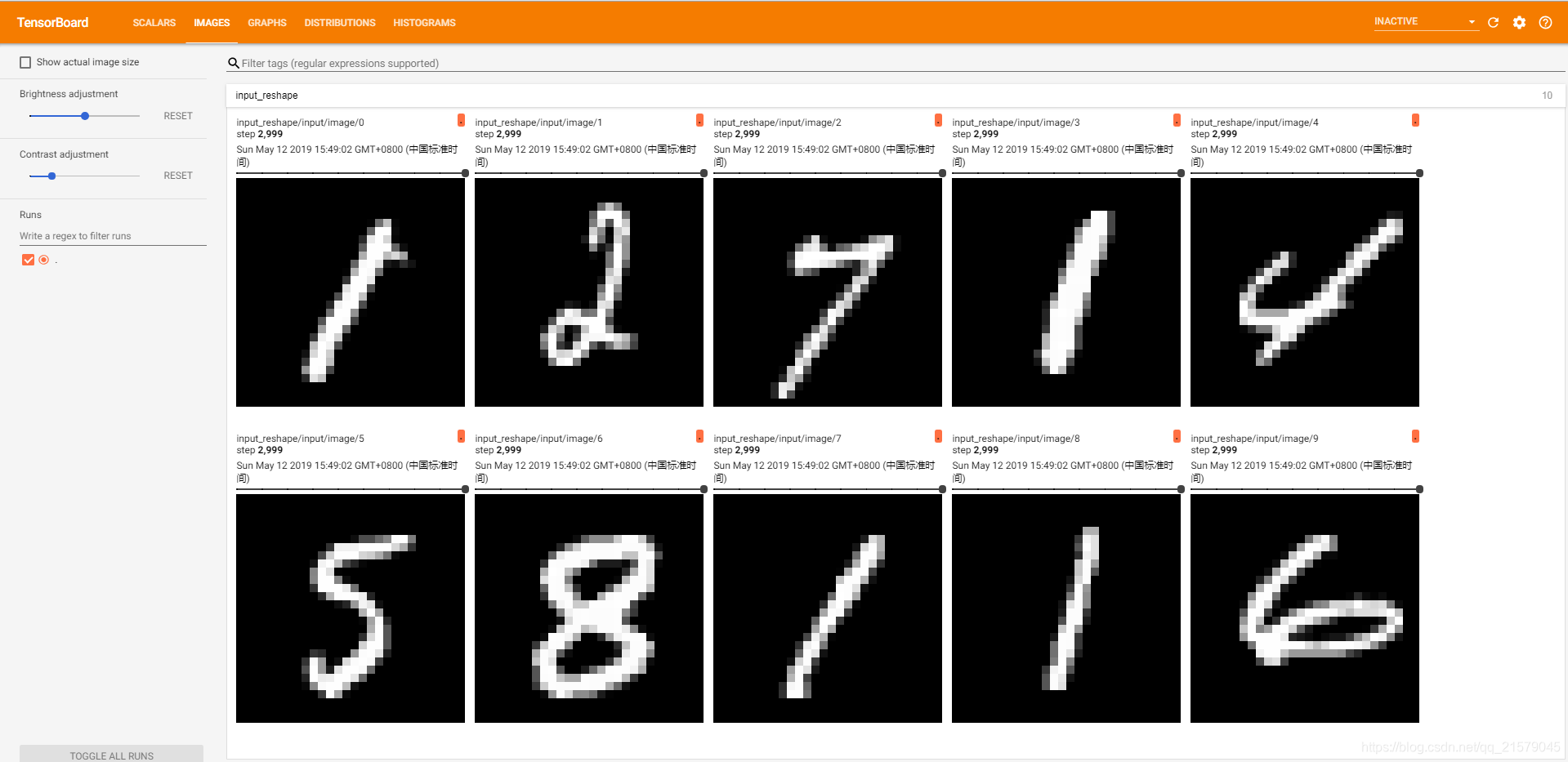
TensorBoard的DISTRIBUTION一栏提供了对张量取值分布的可视化界面,通过这个界面可以直观地观察到不同层神经网络中参数的取值变化。
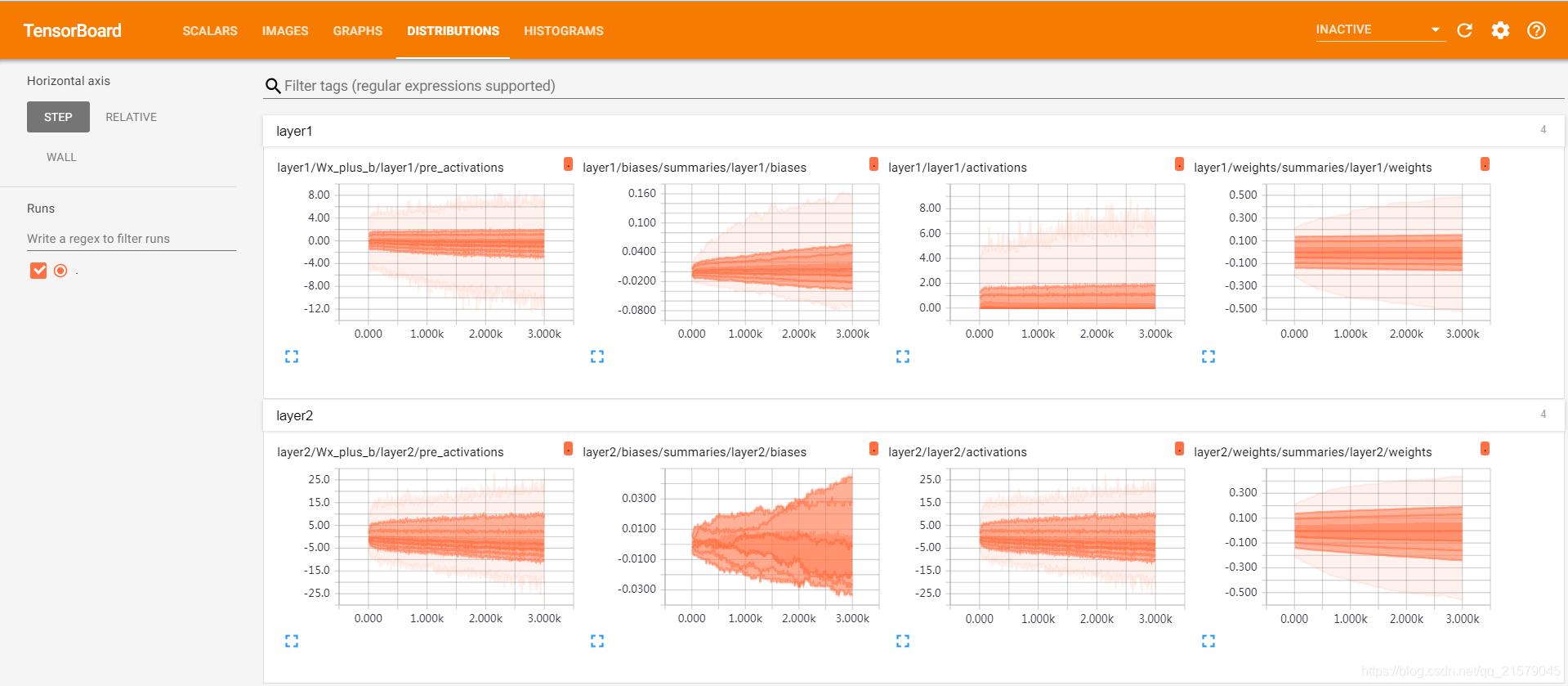
为了更加清晰地展示参数取值分布和训练迭代轮数之间的关系,TensorBoard提供了HISTOGRAMS视图。
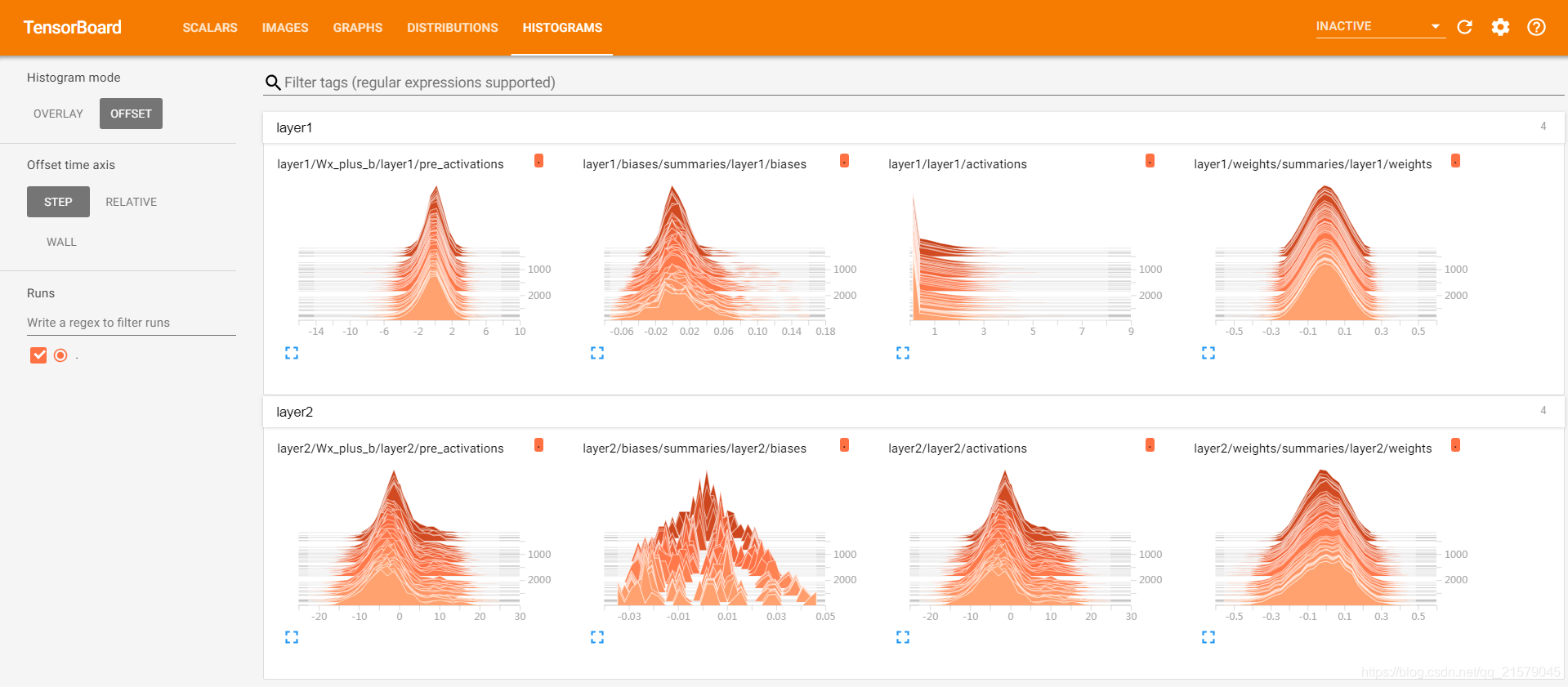
颜色越深的平面代表迭代轮数越小的取值分布。
点击“OVERLAY”后,可以看到如下效果:
4. 高维向量可视化
使用MNIST测试数据生成PROJECTOR所需要的两个文件。(一个sprite图像,一个tsv文件)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test7.py
@time: 2019/5/12 20:45
@desc: 使用MNIST测试数据生成PROJECTOR所需要的两个文件。(一个sprite图像,一个tsv文件)
"""
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import os
from tensorflow.examples.tutorials.mnist import input_data
# PROJECTOR需要的日志文件名和地址相关参数。
LOG_DIR = './log2'
SPRITE_FILE = 'mnist_sprite.jpg'
META_FILE = "mnist_meta.tsv"
# 使用给出的MNIST图片列表生成sprite图像。
def create_sprite_image(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
# sprite图像可以理解成是所有小图片拼成的大正方形矩阵,大正方形矩阵中的每一个
# 元素就是原来的小图片。于是这个正方形的边长就是sqrt(n),其中n为小图片的数量。
# np.ceil向上取整。np.floor向下取整。
m = int(np.ceil(np.sqrt(images.shape[0])))
# 使用全1来初始化最终的大图片。
sprite_image = np.ones((img_h*m, img_w*m))
for i in range(m):
for j in range(m):
# 计算当前图片的编号
cur = i * m + j
if cur < images.shape[0]:
# 将当前小图片的内容复制到最终的sprite图像。
sprite_image[i*img_h: (i+1)*img_h, j*img_w: (j+1)*img_w] = images[cur]
return sprite_image
# 加载MNIST数据。这里指定了one_hot=False,于是得到的labels就是一个数字,表示当前图片所表示的数字。
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=False)
# 生成sprite图像
to_visualise = 1 - np.reshape(mnist.test.images, (-1, 28, 28))
sprite_image = create_sprite_image(to_visualise)
# 将生成的sprite图像放到相应的日志目录下。
path_for_mnist_sprites = os.path.join(LOG_DIR, SPRITE_FILE)
plt.imsave(path_for_mnist_sprites, sprite_image, cmap='gray')
plt.imshow(sprite_image, cmap='gray')
# 生成每张图片对应的标签文件并写到相应的日志目录下。
path_for_mnist_metadata = os.path.join(LOG_DIR, META_FILE)
with open(path_for_mnist_metadata, 'w') as f:
f.write('Index Label
')
for index, label in enumerate(mnist.test.labels):
f.write("%d %d
" % (index, label))
这里写点小tips关于np.ceil、np.floor、enumerate:
np.ceil:向上取整。
np.floor:向下取整。
enumerate:该函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。
回到正题,运行代码之后可以得到两个文件,一个是sprite图,一个是mnist_meta.csv文件。
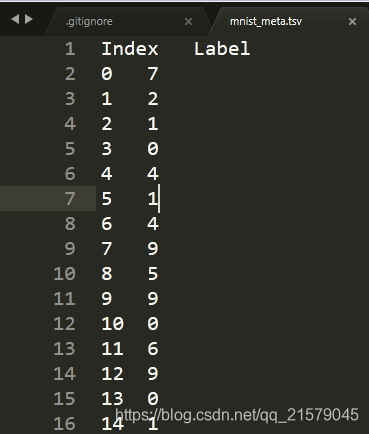
在生成好辅助数据之后,以下代码展示了如何使用TensorFlow代码生成PROJECTOR所需要的日志文件来可视化MNIST测试数据在最后的输出层向量。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test8.py
@time: 2019/5/13 9:34
@desc: 在生成好辅助数据之后,以下代码展示了如何使用TensorFlow代码生成PROJECTOR所需要的日志文件来可视化MNIST测试数据在最后的输出层向量。
"""
import tensorflow as tf
from BookStudy.book2 import mnist_inference
import os
# 加载用于生成PROJECTOR日志的帮助函数。
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data
# 和前面中类似地定义训练模型需要的参数。这里我们同样是复用mnist_inference过程。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
# 可以通过调整这个参数来控制训练迭代轮数。
TRAINING_STEPS = 10000
MOVING_AVERAGE_DECAY = 0.99
# 和日志文件相关的文件名及目录地址。
LOG_DIR = './log3'
SPRITE_FILE = 'D:/Python3Space/BookStudy/book2/tensorboard_test/log2/mnist_sprite.jpg'
META_FILE = 'D:/Python3Space/BookStudy/book2/tensorboard_test/log2/mnist_meta.tsv'
TENSOR_NAME = 'FINAL_LOGITS'
# 训练过程和前面给出的基本一致,唯一不同的是这里还需要返回最后测试数据经过整个
# 神经网络得到的输出矩阵(因为有很多张测试图片,每张图片对应了一个输出层向量,
# 所以返回的结果是这些向量组成的矩阵。
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 训练模型
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
# 计算MNIST测试数据对应的输出层矩阵。
final_result = sess.run(y, feed_dict={x: mnist.test.images})
# 返回输出层矩阵的值。
return final_result
# 生成可视化最终输出层向量所需要的日志文件。
def visualisation(final_result):
# 使用一个新的变量来保存最终输出层向量的结果。因为embedding是通过TensorFlow中
# 变量完成的,所以PROJECTOR可视化的都是TensorFlow中的变量。于是这里需要新定义
# 一个变量来保存输出层向量的取值。
y = tf.Variable(final_result, name=TENSOR_NAME)
summary_writer = tf.summary.FileWriter(LOG_DIR)
# 通过projector.ProjectorConfig类来帮助生成日志文件。
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果。
embedding = config.embeddings.add()
# 指定这个embedding结果对应的TensorFlow变量名称。
embedding.tensor_name = y.name
# 指定embedding结果所对应的原始数据信息。比如这里指定的就是每一张MNIST测试图片
# 对应的真实类别。在单词向量中可以是单词ID对应的单词。这个文件是可选的,如果没有指定
# 那么向量就没有标签。
embedding.metadata_path = META_FILE
# 指定sprite图像。这个也是可选的,如果没有提供sprite图像,那么可视化的结果
# 每一个点就是一个小圆点,而不是具体的图片。
embedding.sprite.image_path = SPRITE_FILE
# 在提供sprite图像时,通过single_image_dim可以指定单张图片的大小。
# 这将用于从sprite图像中截取正确的原始图片。
embedding.sprite.single_image_dim.extend([28, 28])
# 将PROJECTOR所需要的内容写入日志文件。
projector.visualize_embeddings(summary_writer, config)
# 生成会话,初始化新声明的变量并将需要的日志信息写入文件。
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sess, os.path.join(LOG_DIR, "model"), TRAINING_STEPS)
summary_writer.close()
# 主函数先调用模型训练的过程,再使用训练好的模型来处理MNIST测试数据,
# 最后将得到的输出层矩阵输出到PROJECTOR需要的日志文件中。
def main(argc=None):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
final_result = train(mnist)
visualisation(final_result)
if __name__ == '__main__':
main()
运行结果:
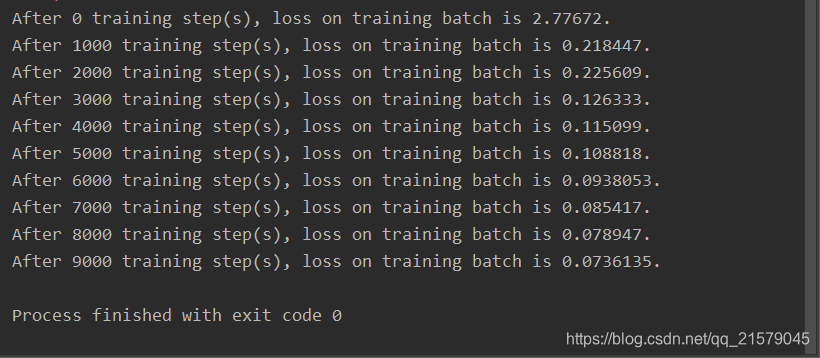
然后打开tensorboard:
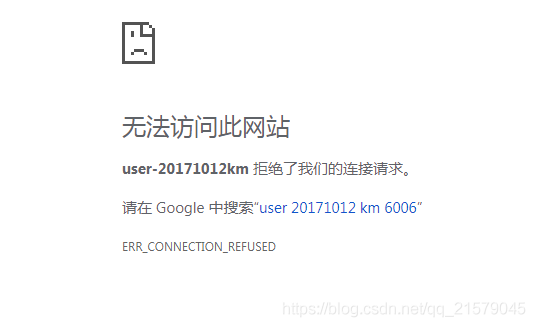
然后就GG了,网上百度了一万种方法。。。
参考链接:https://blog.csdn.net/weixin_42769131/article/details/84870558
tensorboard --logdir=./log3 --host=127.0.0.1
解决!然而!我可以打开前面的log,这次模型的生成的不知道是不是需要太大的内存,界面一致卡在Computing PCA…
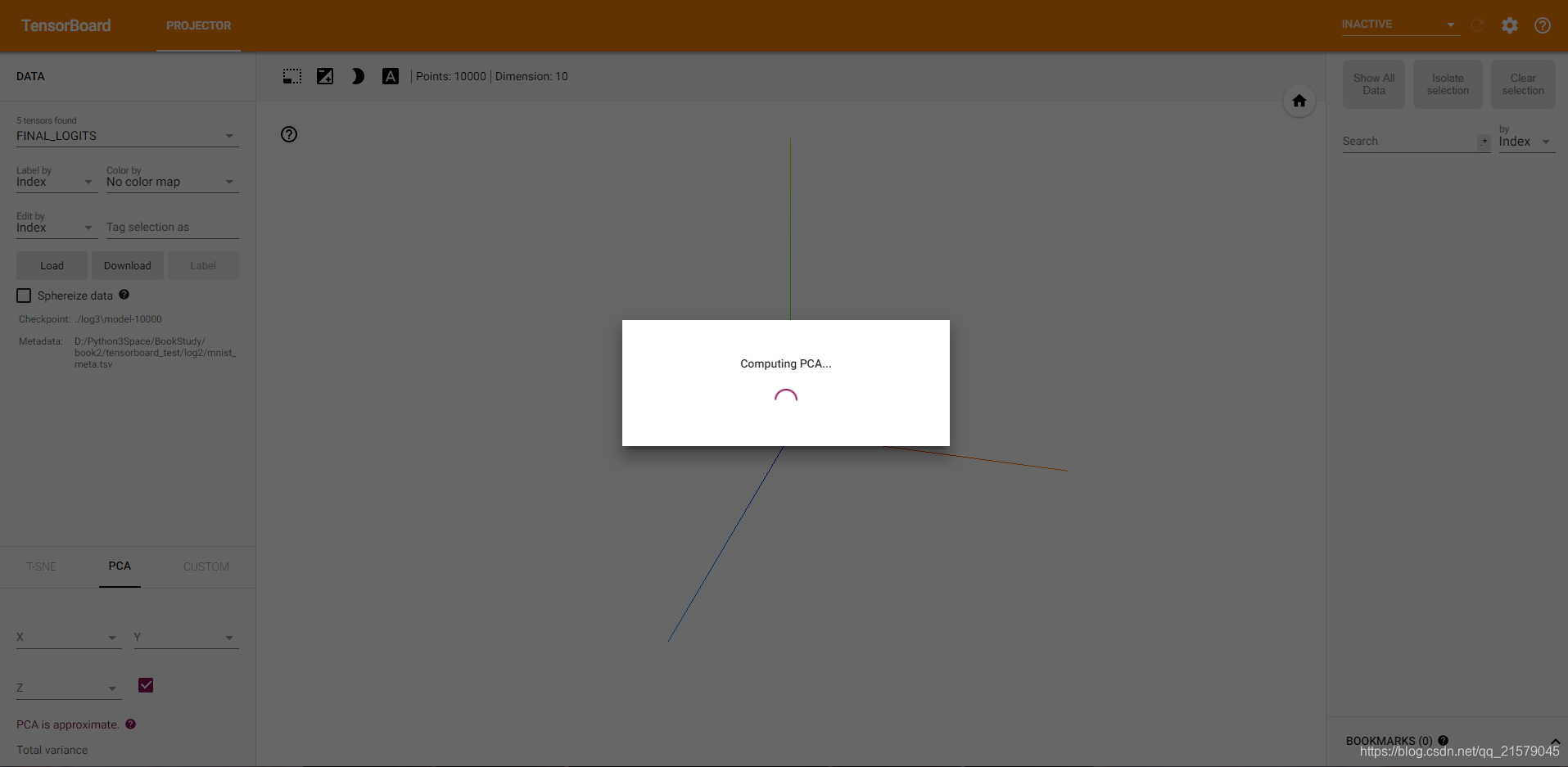
就很头大。。。
然后我换了台电脑(MacBook),就能直接出来。。。
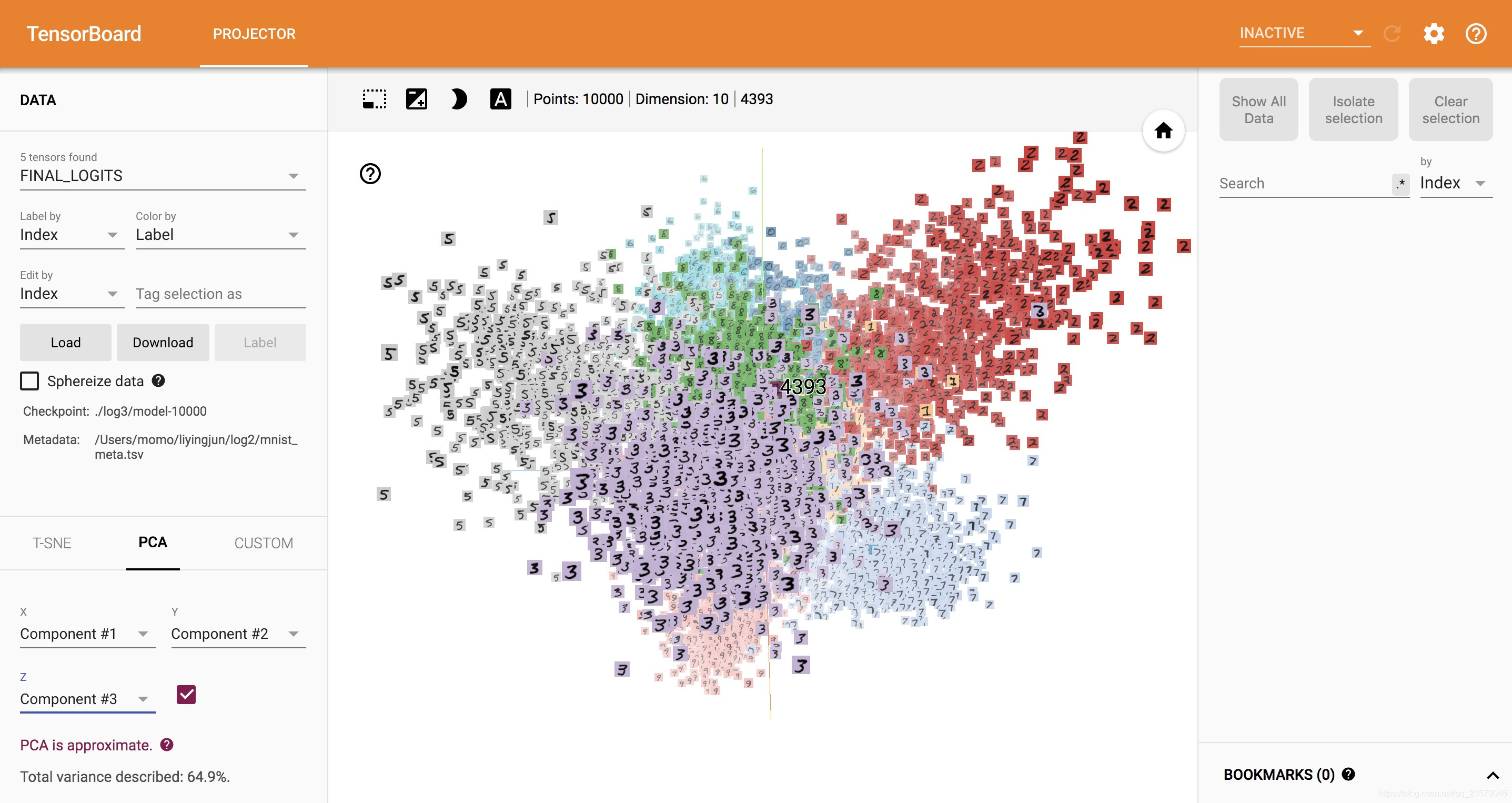
还是三围旋转的。。。旋转~ 跳跃~
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友