1. 二叉树
1.1 概念
二叉树是n个有限元素(结点)的集合,由根结点及两个互不相交的左、右子二叉树组成,且左节点中的数据始终小于右节点。
1.2 形态
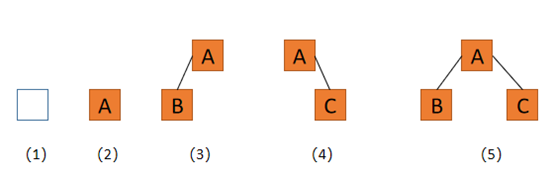
二叉树是递归形成的,它的形态可以概括为五种基本形态:
(1)空二叉树;
(2)只有一个根节点的二叉树;
(3)只有左结点的二叉树;
(4)只有右结点的二叉树;
(5)完全二叉树。
1.3 性质
性质1:二叉树的第i层上至多有(i≥1)个节点。
性质2:深度为h的二叉树中至多含有-1个节点。
性质3:若在任意一棵二叉树中,有n个叶子节点,有n2个度为2的节点,则必有n0=n2+1 。
1.4 二叉树的构建
1.4.1 结点
二叉树中每个结点需要包含数据域、左子结点指针域、右子结点指针域。
class Node
{
private:
int data;
Node* leftNode;
Node* rightNode;
public:
Node(int data)
{
this->data=data;
this->leftNode=NULL;
this->rightNode=NULL;
}
}
1.4.2 二叉树类
实际上结点类就是二叉树,而接下来要编写的二叉树类是为了方便使用二叉树设计的,可以理解为二叉树使用类。
二叉树类的基本成员:根节点。//root
基本方法:插入数据。//按左存小右存大的原则
class BinaryTree
{
private:
Node* root;
public:
//构造
BinaryTree()
{
root=NULL;
}
//插入数据
void insert(int data)
{
//step1:建立新的结点
Node* newNode=new Node(data);
//step2:判断根节点是否为空
if(root==NULL)
{
root=newNode;
return;
}
else
{
//current用于指向当前结点,parent用于指向当前结点的父节点
Node* current=root;
Node* parent;
while(true)
{
parent=current;
if(date<current->data)
{
//current指向左孩子结点
current=current->leftNode;
if(current!=NULL)
{
parent->left=newNode;
//找到叶子结点后,终止循环
return;
}
}
else
{
current=current->rightNode;
if(current!=NULL)
{
parent->right=newNode;
return;
}
}
}
}
}
}
1.5 遍历
1.5.1 递归遍历
二叉树的遍历方式有很多,根据双亲结点、左子结点、右子节点的访问顺序可以归结为:
(1)前序遍历
void serch_tree(Node* root)
{
if(!root)
return;
cout<<root->data<<endl;//先读取双亲结点的数据
serch_tree(root->left);//打印左子树
serch_tree(root->right);//打印右子树
}
(2)中序遍历
void serch_tree(Node* root)
{
if(!root)
return;
serch_tree(root->left);
cout<<root->data<<endl;//中读取双亲结点的数据
serch_tree(root->right);
}
(3)后序遍历
void serch_tree(Node* root)
{
if(!root)
return;
serch_tree(root->left);
serch_tree(root->right);
cout<<root->data<<endl;//后读取双亲结点的数据
}
递归遍历二叉树的优点是编码简单,但是当树的深度较大时,由于不断的数据压栈,造成空间开销大的问题。
1.5.2 非递归遍历
非递归遍历需要用到栈,首先将树中的左节点全部压栈,然后进入右子树,继续循环,直至栈及节点均为NULL。
BTNode* p = root;
stack<BTNode*> s;
while (!s.empty() || p)
{
//代码段(i)一直遍历到左子树最下边,边遍历边保存根节点到栈中
while (p)
{
s.push(p);
p = p->lchild;
}
//代码段(ii)当p为空时,说明已经到达左子树最下边,这时需要出栈了
if (!s.empty())
{
p = s.top();
s.pop();
cout << p->data;
//进入右子树,开始新的一轮左子树遍历(这是递归的自我实现)
p = p->rchild;
}
}