一、NumPy简介
Numpy(Numerical Python的简称)高性能科学计算和数据分析的基础包。其部分功能如下:
- ndarray,具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 数组运算,不用编写循环
- 可以读写磁盘数据,操作内存映射
- 线性代数
- 集成c,c++等语言
python能够包装c、c++以numpy数组形式的数据。pandas提供了结构化或表格化数据的处理高级接口,
还提供了numpy不具备的时间序列处理等;
二、ndarray:多维数组对象
ndarray:多维数组对象,快速灵活的大数据集容器,要求所有元素的类型一致,通常说的“数组”、“Numpy数组”、“ndarray”都是指“ndarray”对象。
1、创建ndarray
array():输入数据转换为ndarray对象,可以是python元组、列表或其他序列类型。可以自动识别dtype,或者手动指定类型



示例:
import numpy as np a = np.array([1,2,3,5,6,7]) print(a) #[1 2 3 5 6 7] b = np.arange(10) print(b) #[0 1 2 3 4 5 6 7 8 9] c = np.ones((3,1)) print(c) ''' [[1.] [1.] [1.]] ''' d = np.zeros((2,5)) print(d) ''' [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] ''' e = np.eye(3) print(e) ''' [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] ''' f = np.linspace(1,10,4) print(f) ''' [ 1. 4. 7. 10.] ''' g = np.linspace(1,10,4,endpoint=False) #endpoint=False:不包含最后一个数 print(g) ''' [1. 3.25 5.5 7.75] ''' h = np.concatenate((f,g)) print(h) ''' [ 1. 4. 7. 10. 1. 3.25 5.5 7.75] '''
2、ndarray常用属性:
import numpy as np data=[[1,2,3,4],[5,6,7,8]] arr=np.array(data) print(arr) print(arr.ndim) #数组的维数 2 print(arr.shape) #数组的维度 (2,4) print(arr.size) #数组的元素总个数 8 print(arr.dtype) #数组中元素的类型 int32 print(arr.itemsize) #数组中每个元素的字节大小 4 print(arr.data) #实际数组元素的缓冲区

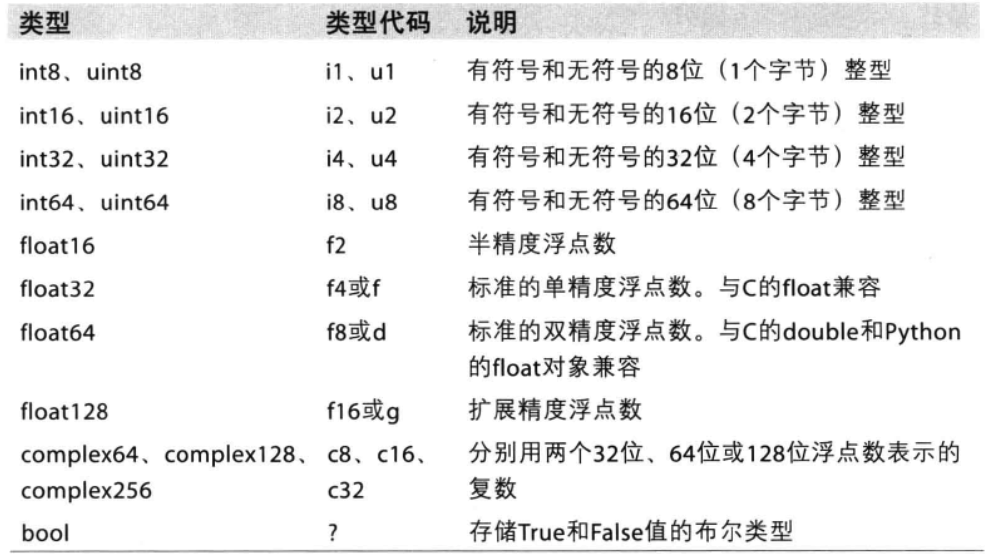
3、ndarray改变元素类型:
可以使用astype修改dtype,接上述代码
astype不会修改原数组,是会创建一个新数组返回
c = a.astype('float64') print(c.dtype) #float64
4、ndarray数组的维度变化

示例:
import numpy as np a = np.ones((2,3,4),dtype=np.int32) print(a) ''' [[[1 1 1 1] [1 1 1 1] [1 1 1 1]] [[1 1 1 1] [1 1 1 1] [1 1 1 1]]] ''' b = a.reshape((3,8)) #reshape不改变原数组 print(b) ''' [[1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1]] ''' c = np.ones((2,3,4),dtype=np.int32) c.resize((3,8)) #resize会改变原数组 print(c) ''' [[1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1]] ''' d = np.ones((2,2,3),dtype=np.int32) e = d.flatten() #进行降维,不会改变原数组 print(e)
5、ndarray数组转为python的中的列表
tolist()方法:
import numpy as np a = np.ones((2,2,3),dtype=np.int32) print(a) ''' [[[1 1 1] [1 1 1]] [[1 1 1] [1 1 1]]] ''' b = a.tolist() print(b) #[[[1, 1, 1], [1, 1, 1]], [[1, 1, 1], [1, 1, 1]]]
6、Numpy索引和切片
Numpy切片功能与python的列用法是相同的,但是在是否复制切片数据是有区别的。
- python列表切片的时候复制数据
- Numpy数组切片直接操作原数组
①python 列表切片操作
# In [24]: list1 = list(range(10)) In [25]: list1 Out[25]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [26]: id(list1) Out[26]: 104821896 In [27]: list1_slice = list1[2:5] In [28]: id(list1_slice) Out[28]: 104992840 In [29]: list1_slice Out[29]: [2, 3, 4] In [30]: list1_slice[0] = 100 In [31]: list1_slice Out[31]: [100, 3, 4] In [32]: list1 # 注意2号位置没有变化 Out[32]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
②、Numpy 数组切片操作
In [33]: arr = np.arange(10) In [34]: arr Out[34]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [35]: id(arr) Out[35]: 105028784 In [36]: arr_slice = arr[2:5] In [37]: arr_slice Out[37]: array([2, 3, 4]) In [38]: arr_slice[0] = 100 In [39]: arr_slice Out[39]: array([100, 3, 4]) In [40]: id(arr_slice) Out[40]: 105029024 In [41]: arr #2号位置被赋值了。 Out[41]: array([ 0, 1, 100, 3, 4, 5, 6, 7, 8, 9])
这样做的原因是Numpy为了能够更好的处理大数据集。如果每次复制将会大大的消耗内存。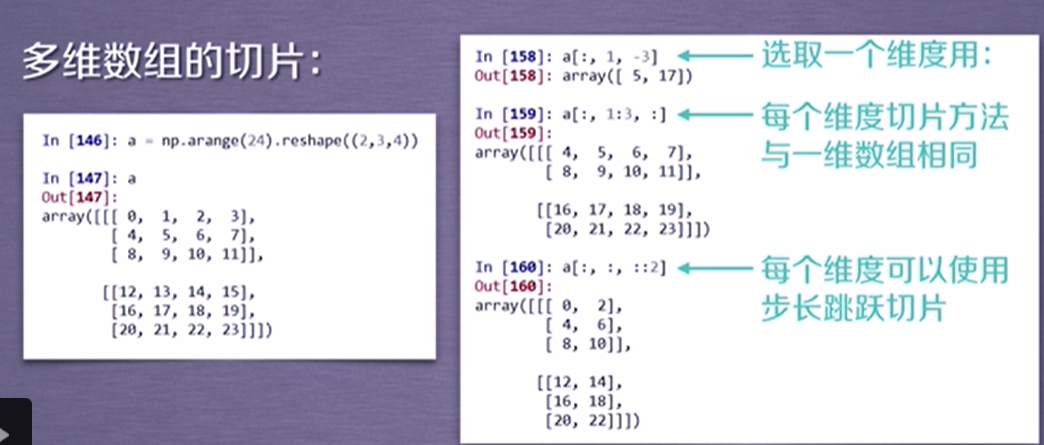
7、NumPy数组的运算
c=a-b#加减乘除都可,将元素分别对应加减乘除,shape必须对应,除的话注意除数为0的情况print(a**2)#会对数组每个元素进行处理,也可进行一下方法遍历 print(a.sum())#总和 print(a.min())#最小的数 print(a.max())#最大的数 print(a.cumsum())#获取每个数的前n的和,比如前1个位0,前2个位0+1,前3个位0+1+2以此类推 d=np.arange(12).reshape(3,4) print(d.sum(axis=-2))#总和 print(d.min(axis=0))#最小的数 print(d.max(axis=-1))#最大的数 print(d.mean())#算术平均数 print(d.std())#标准差 print(d.var())#方差 print(d.argmin())#最小索引 print(d.argmax())#最大索引 print(d.repeat(5))#重复 print(np.power(b,3))#b的3次方 print(np.repeat(3, 4))#创建一个一维数组,元素为3,重复4次 print(d.cumsum(axis=1))#获取每个数的前n的和,比如前1个位0,前2个位0+1,前3个位0+1+2以此类推 print(d.cumprod())#所有元素的累积积 #总结:当没有axis参数的时候,默认为全部元素,当值为0或-2时,表示每个列中的第一个数,当值为1或-1时,表示以列做运算,其他值则报错 s=np.array([4,3,1,45,2,1,23]) s.sort()#排序 print(np.unique(s))#找出唯一值并排序
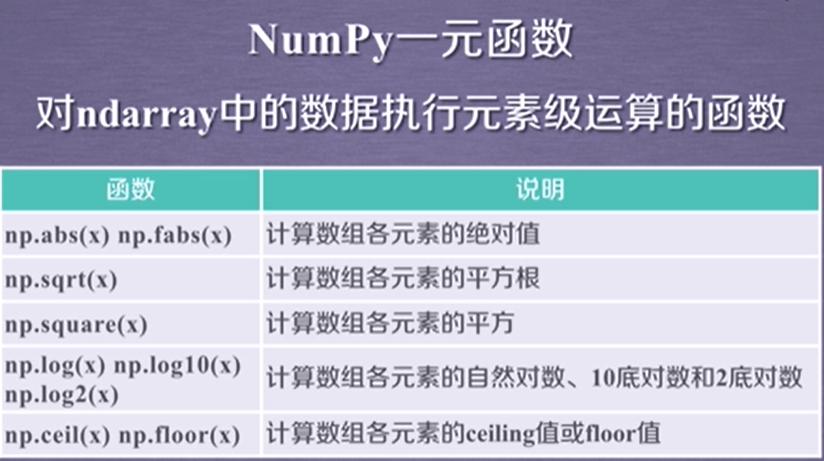
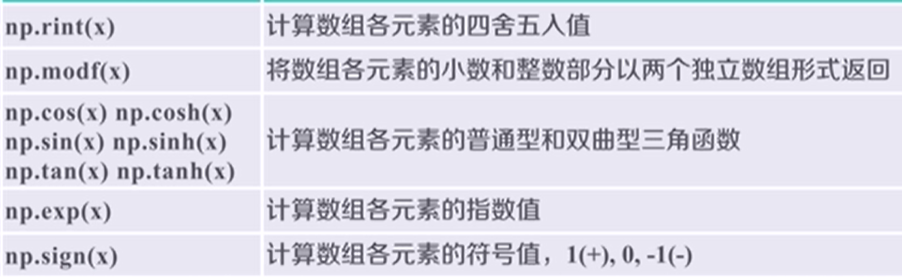
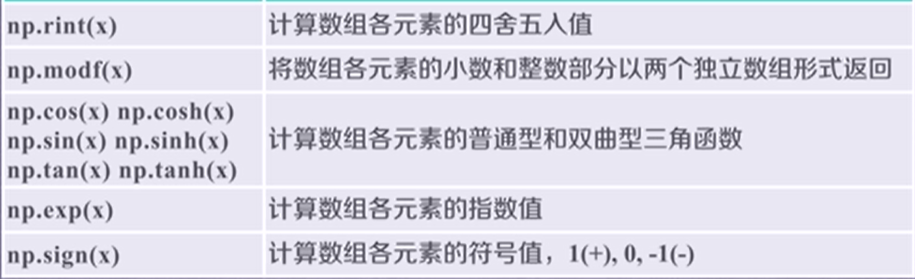
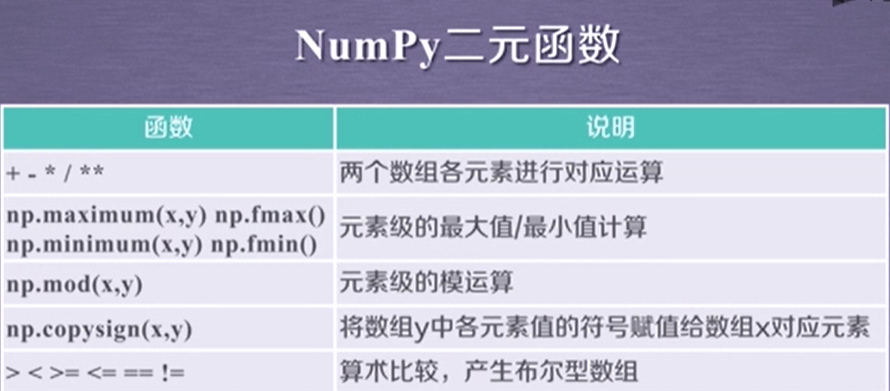
三、ndarray数组的存储和读取
1、一维和二维的存储和读取
①、存储文件

import numpy as np a = np.arange(100).reshape((4,25)) np.savetxt('a.csv',a,fmt='%d',delimiter=',')
②、读取文件

import numpy as np #读取 b = np.loadtxt('a.csv',dtype=np.float,delimiter=',') print(b)
2、多维的存储和读取
①存储

②读取(读取之后没有维度信息,需要自己通过reshape或者其它方式转为想要的维度)

3、便捷存储和读取(读取时转换维度)

四、numpy.random的随机数函数

示例:



五、numpy.random的统计函数
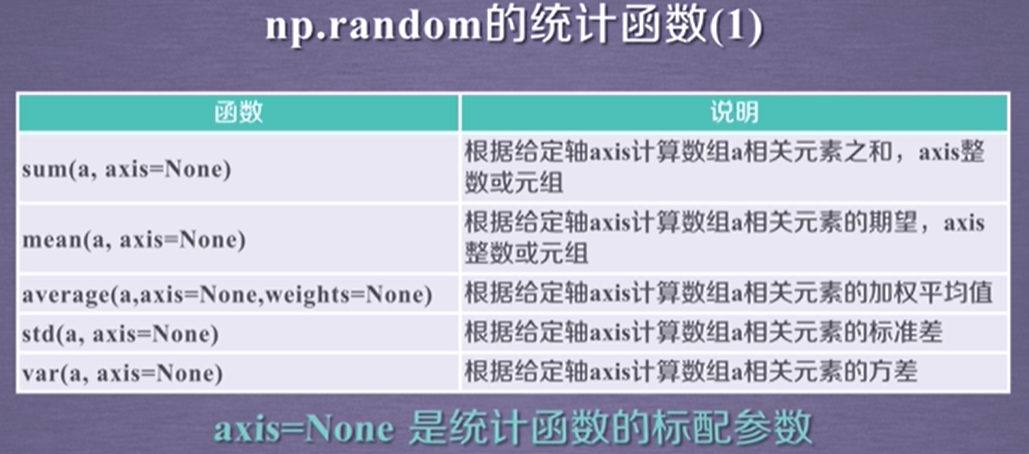
示例:


示例:

六、numpy.random的梯度函数

一维梯度示例:

二维梯度示例:

七、图像的数组表示
通过PIL库转换图像

from PIL import Image import numpy as np im = np.array(Image.open("C:壁纸.jpg")) #图像是一个三维数组,维度分别是高度。宽度和像素RGB值 print(im.shape,im.dtype) #(1080, 1920, 3) uint8
图像的变换测试:
from PIL import Image import numpy as np im = np.array(Image.open("C:壁纸.jpg")) #图像是一个三维数组,维度分别是高度。宽度和像素RGB值 print(im.shape,im.dtype) #(1080, 1920, 3) uint8 b = [255,255,255] - im im2 = Image.fromarray(b.astype('uint8')) im2.save("python测试后的图像.jpg")
原图:

变换后的图像:
