昨日回顾
1. 初识python
python是一门弱类型的解释型高级编程语言
解释器:
CPython 官方提供的默认解释器. c语言实现的
PyPy 把python程序一次性进行编译.
IPython
2. python的版本
2.x
3.x
3. 变量
概念: 程序运行过程中产生的中间值. 暂时存储在内存, 方便后面的程序使用它
就是一个符号.
x = 10
郝建 -> 沈腾
白云 -> 宋丹丹
命名规范:
1. 数字, 字母, 下划线组成
2. 不能是数字开头, 更不能是纯数字
3. 不能用python的关键字
4. 不要用中文
5. 不要太长
6. 有意义
7. 区分大小写
8. 用驼峰或者下划线
数据类型:
1. int 整数 +-*/% // **
2. str 字符串,
把字符连城串
字符:单一的文字符号
'', "", ''', """
+ 拼接. 要求两端都得是字符串
* 重复 必须乘以一个数字
3. bool 布尔值
True
False
用来判断
用户交互
变量 = input(提示语)
条件判断:
if 条件:
if-语句块
if 条件:
if-语句块
else:
else-语句块
if 条件1:
if-1
elif 条件2:
if-2
......
else:
今日内容
1. while循环 (难点)
while 条件:
循环体(break, continue)
2. 格式化输出
%s 万能
%d
f"{变量}"
3. 运算符 and or not (难点)
运算顺序: ()=> not => and =>or
4. 初识编码 gbk unicode utf-8
1. ascii 8bit 1byte(字节) 256个码位 只用到了7bit, 用到了前128个 最前面的一位是0
2. 中国人自己对计算机编码进行统计. 自己设计. 对ascii进行扩展 ANSI 16bit -> 清华同方 -> gbk
GBK 放的是中文编码. 16bit 2byte 兼容ascii
3. 对所有编码进行统一. unicode. 万国码. 32bit. 4byte. 够用了但是很浪费
4. utf-8 可变长度的unicode
英文: 1byte
欧洲文字: 2byte
中文: 3byte
字节(byte)
1byte = 8bit
1kb = 1024byte
1mb = 1024kb
1gb = 1024mb
1tb = 1024gb
1pb = 1024tb
预习:
字符串(记的东西)
for循环
while循环
# 语法: while 条件: 结果
如果条件是真, 则直接执⾏结果. 然后再次判断条件. 直到条件是假,停⽌循环
那我们怎么终⽌循环呢? 结束循环:
1,改变条件. 2,break
流程控制-break和continue
1, break: 立刻跳出循环. 打断的意思
2, continue: 停⽌本次循环, 继续执⾏下⼀次循环.
while True: content = input("请输入你要喷的内容, 输入Q退出") if content == "Q": # 退出程序 打断循环 break # 直接跳出循环 print("你对打野说:", content) if True: print("娃哈哈") # 最多喷三次 count = 1 while count <= 3: # count = 1 # 次数, 死循环 content = input("请输入你要喷的内容") print("你要对上单说:", content) # 改变count count = count + 1 # continue while True: content = input("请输入你要喷的内容, 输入Q退出") if content == "": continue # 停止当前本次循环. 继续执行下一次循环 不会彻底终止循环,只是中断不会终止. if content == "Q": # 退出程序 打断循环 break # 直接跳出循环 print("你对打野说:", content) # 能够让循环退出: 1. break 2. 改变条件 # continue 停止当前本次循环. 继续执行下一次循环 # break 彻底的干掉一个循环 # 让程序从1数数, 数到100 count = 1 while count <= 100: print(count) # 1 count = count + 1 # 计算 1-100之间所有的数的和 sum = 0 # sum: 0 + 1 + 2 + 3 + 4....99 + 100 count = 1 # count: 1, 2, 3, 4, 99,100, 101 while count <= 100: sum = sum + count # 累加运算 count = count + 1 print(sum) # 数数. 1-100奇数 # 方法1 count = 1 while count <= 100: print(count) count = count + 2 # 方法2 count = 1 while count <= 100: if count % 2 == 1: print(count) else: print("偶数....") count = count + 1
补充1: while循环.
while 条件: 循环体 else: 循环在正常情况跳出之后会执⾏这⾥
# 栗子 index = 1 while index < 11: if index == 8: # break pass else: print(index) index = index+1 else:print("你好")
注意:
如果循环是通过break退出的,那么while后⾯的else将不会被执⾏, 只有在while条件判断是假的时候才会执⾏这个 else.
pass: 不表⽰任何内容,为了代码的完整性,占位⽽已 .
格式化输出
%s 字符串占位符(但是所有的数据类型都可以使用)
%d 数字占位符(只能int类型使用)
f"{变量}"
name = input("请输入你的名字:") address = input("请输入你来自哪里:") wife = input("请输入你的老婆:") notlike = input("请输入你不喜欢的明星:") print("我叫"+name+", 我来自"+address+", 我老婆是"+wife+", 我不喜欢"+notlike) # 需要掌握的内容=============== # 格式化输出 %s print("我叫%s, 我来自%s, 我老婆是%s, 我不喜欢%s" % (name, address, wife, notlike)) # 新版本的格式化输出 print(f"我叫{name}, 我来自{address}, 我老婆是{wife}, 我不喜欢{notlike}") # 需要掌握的内容=============== hobby = "踢球" print("我喜欢%s, 我老婆更喜欢%s" % (hobby, hobby)) # %s 表示字符串的占位 . 全能的占位. print("周杰伦今年%s岁了" % 18) # %d 占位数字. 只能放数字 print("周杰伦去年%d岁了" % 16) print("周杰伦去年%d岁了" % "16") # 报错 # 坑, 如果这句话使用了格式化输出. % 就是占位, 如果想显示正常的% %% 转义 print("我叫%s, 我已经度过了30%的人生了" % "俞洪敏") # 报错 not enough arguments for format string print("我叫%s, 我已经度过了30%%的人生了" % "俞洪敏")
注意:
在字符串中如果使⽤了%s这样的占位符,那么所有的%都将变成占位符,我们需要使用%%来表示字符串中的%.
如果你的字符串中没有使用过%s,%d占位.,那么不需要考虑这么多, 该%就%.没毛病老铁.
print("我叫%s, 今年22岁了, 学习python2%%了" % '王尼玛') # 有%占位符 print("我叫王尼玛, 今年22岁, 已经凉了100%了") # 没有占位符
运算符
什么是运算符?举个简单的例子 4 +5 = 9 。 例子中,4 和 5 被称为操作数,"+" 称为运算符。
计算机可以进⾏的运算有很多种,可不只加减乘除这么简单,运算按种类可分为:
算数运算、 比较运算、逻辑运算、 赋值运算、
成员运算、 身份运算、 位运算.
算数运算
以下假设变量:a=10,b=20
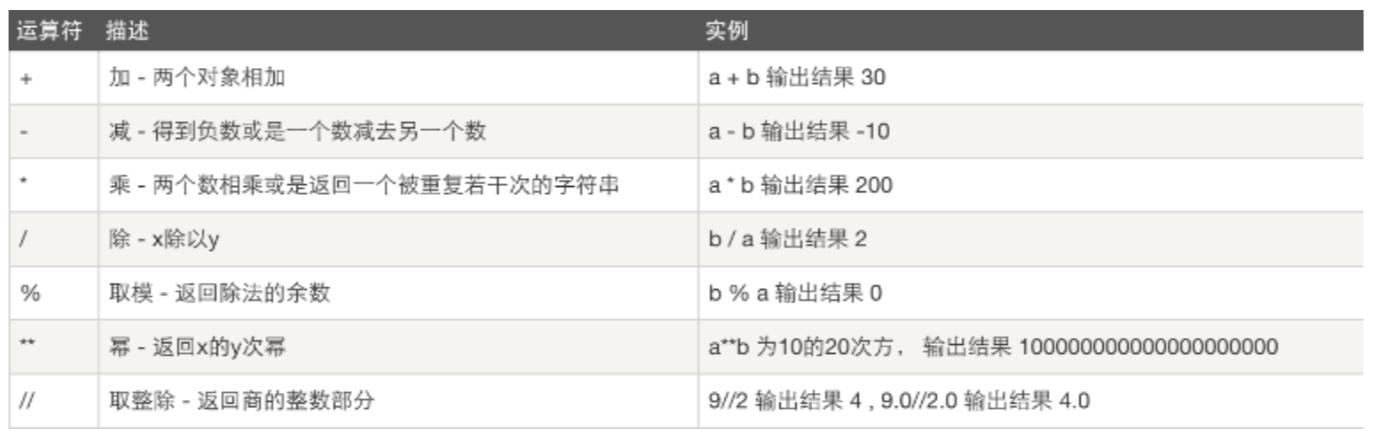
注意:
| // | 取整除 - 向下取接近除数的整数 |
>>> 9//2
4
>>> -9//2
-5
|
比较运算
以下假设变量:a=10,b=2

# 注意: print(3 <> 3) 2.x可以使用, 3.x 不能 print(3 > = 3) # 报错,>= 是个整体,不能分开
赋值运算
以下假设变量:a=10,b=20

逻辑运算(重点难点)

1, 优先级关系为 () > not > and > or
2, x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y, x为假,值是x。

#逻辑运算符 初级 ''' and : 并且. 左右两端同时为真. 结果才能是真 or : 或者. 左右两端有一个是真. 结果就是真 not : 非. 非真即假, 非假即真 不真-> 假 不假 -> 真 混合运算顺序: () => not => and => or 当出现相同的优先级的时候 从左往右算 ''' print(3 > 2 and 4 < 6 and 5 > 7) # False print(5 < 6 or 7 > 8 or 9 < 6 or 3 > 2) # True print(not 5 < 6) # False print(3 > 2 or 5 < 7 and 6 > 8 or 7 < 5) # True print(3 > 4 or 4 < 3 and 1 == 1) # False print(1 < 2 and 3 < 4 or 1 > 2) # True print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1) # True print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8) # False print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # False print((not 2 > 1 and 3 < 4) or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # False #逻辑运算符 进阶 ''' 优先级依然是:() > not > and > or 当出现 x or y的时候, 判断x是否是0 如果x==0 then y 否则返回x 当出现 x and y 的时候, 和or相反(or 要非0,and要0) 把False 当成0,True 当成1来看 ''' # 当出现 x or y的时候, 判断x是否是0 如果x==0 then y 否则返回x print(1 or 2) # 1 print(0 or 2) # 2 print(3 or 0) # 3 print(4 or 0) # 4 print(0 or 3 or 0 or 2 or 0 or 5 or 0 or 188) # 3 # 当出现 x and y 的时候, 和or相反 print(1 and 2) # 2 print(0 and 3) # 0 print(3 and 0) # 0 print(4 and 0) # 0 print(9 and 3 and 4 and 1 and 4 and 8) # 8 print(1 and 2 or 3) # 应付面试 2 print(1 and 2 > 4) # False # False 当成0来看 print(False and 1) # False print(3 > 5 or 5 < 6 and 7) # 7 print(4 > 5 or 7 and 8 < 6 or 3 and 4) # 4 print(4>5 or (7 and 8<6) or (3 and 4)) #优先级顺序依旧存在 4
成员运算

# 成员运算 in # 栗子1 content = input("请输入你的评论:") if "马化腾" in content: # content中是否包含了xxx print("你的评论不合法") else: print("你的评论是合法的") # 栗子2 ad = input("请输入你的广告:") if "最" in ad or "第一" in ad or "全球" in ad: print("不合法的") else: print("合法的")
补充2:
in和not in 可以判断xxx字符串是否出现在xxxxx字符串中
content = input("请输⼊你的评论") if "苍⽼师" in content or '邱⽼师' in content: print('你输⼊的内容不合法') else: print("评论成功")
身份运算
身份运算符用于比较两个对象的存储单元
注: id() 函数用于获取对象内存地址。

is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
>>>a = [1, 2, 3] >>> b = a >>> b is a True >>> b == a True >>> b = a[:] >>> b is a False >>> b == a True
位运算
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13二进制格式如下:
a = 0011 1100 b = 0000 1101 ----------------- a&b = 0000 1100 a|b = 0011 1101 a^b = 0011 0001 ~a = 1100 0011
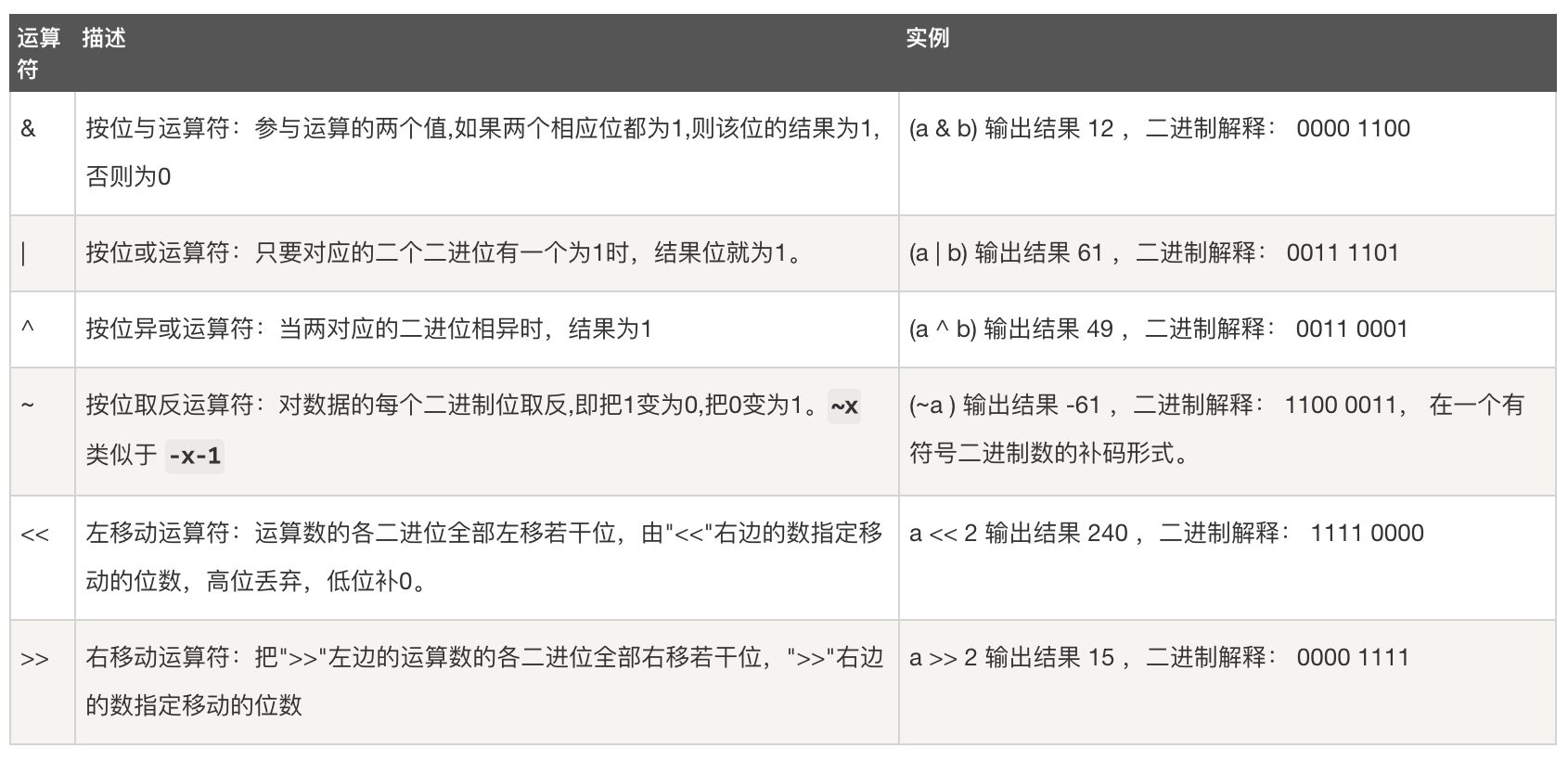
a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = 0 c = a & b; # 12 = 0000 1100 print ("1 - c 的值为:", c) c = a | b; # 61 = 0011 1101 print ("2 - c 的值为:", c) c = a ^ b; # 49 = 0011 0001 print ("3 - c 的值为:", c) c = ~a; # -61 = 1100 0011 print ("4 - c 的值为:", c) c = a << 2; # 240 = 1111 0000 print ("5 - c 的值为:", c) c = a >> 2; # 15 = 0000 1111 print ("6 - c 的值为:", c) # 以上实例输出结果: 1 - c 的值为: 12 2 - c 的值为: 61 3 - c 的值为: 49 4 - c 的值为: -61 5 - c 的值为: 240 6 - c 的值为: 15
结果小技巧:
取反: ~ ==> ~n ==> -(n+1) 左移:<< ==> a<<b ==> a * 2b 右移:>> ==> a>>b ==> a // 2b
初识编码
python2解释器在加载 .py ⽂件中的代码时,会对内容进⾏编码(默认ascill),⽽python3对内容进⾏编码的默认为utf- 8。
计算机:
早期. 计算机是美国发明的. 普及率不不高, ⼀般只是在美国使用. 所以. 最早的编码结构就是按照美国人的习惯来编码 的. 对应数字+字母+特殊字符⼀共也没多少. 所以就形成了了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们.
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的⼀套电 脑编码系统,主要⽤于显示现代英语和其他⻄欧语言,其最多只能用 8 位来表示(⼀个字节),即:2**8 = 256,所 以,ASCII码最多只能表示 256 个符号。 ASCII码对照表
随着计算机的发展. 以及普及率的提高. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了. ⽐如: 中⽂汉字有⼏万个. ⽽ASCII 最多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语⾔环境. ⽐如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使⽤计算机了.
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不⽀持英文肯定不行. ⽽英文已经使用了了ASCII码. 所以GBK要兼容ASCII.
这⾥GBK国标码. 前⾯的ASCII码部分. 由于使用两个字节. 所以对于ASCII码而言. 前9位都是0 (因为原来8位的ASCII 码中的最高位是0,留作扩展使用的)
字母A:0100 0001 # ASCII 字母A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国用. ⽇本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode. unicode一 开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码. 只能进行扩充. 扩充成32位也就是4个字 节. 这回够了. 但是. 问题来了. 中国字9万多. 而unicode可以表示40多亿. 根本用不了. 太浪费了. 于是乎, 就提出了了新的 UTF编码.可变⻓度编码
UTF-8: 每个字符最少占8位. 每个字符占用的字节数不定.根据⽂字内容进行具体编码. 比如. 英文. 就一个字节就够了. 汉 字占3个字节. 这时即满足了中文. 也满⾜了节约. 也是目前使用频率最高的一种编码
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位.
小结:(上面是发展历史,我们记住结论就行啦)
# 初识编码 ascii ==> gbk ==> unicode ==> utf-8 1. ascii 8bit 1byte(字节) 256个码位 只用到了7bit, 用到了前128个 最前面的一位是0 2. 中国人自己对计算机编码进行统计. 自己设计. 对ascii进行扩展 ANSI 16bit -> 清华同方 -> gbk GBK 放的是中文编码. 16bit 2byte 兼容ascii 3. 对所有编码进行统一. unicode. 万国码. 32bit. 4byte. 够用了但是很浪费 4. utf-8 可变长度的unicode 英文: 1byte 欧洲文字: 2byte 中文: 3byte
单位转换
8bit = 1byte 1024byte = 1KB 1024KB = 1MB 1024MB = 1GB 1024GB = 1TB 1024TB = 1PB 1024PB = 1EB 1024EB = 1ZB 1024ZB = 1YB 1024YB = 1NB 1024NB = 1DB 常用到TB就够了