目的是对所有注释进行爬网。
下面列出了已爬网链接。如果您使用AJAX加载动态网页,则有两种方式对其进行爬网。
分别介绍了两种方法:(如果对代码有任何疑问,请提出改进建议)
解析真实地址爬网
示例是参考链接中提供的URL,网站上评论的链接必须使用
beats进行爬网。如果单击“网络”以刷新网页,则注释数据将位于这些文件中。通常,这些数据以json文件格式提供。然后找到注释数据文件。参见下图。单击预览以查看数据。
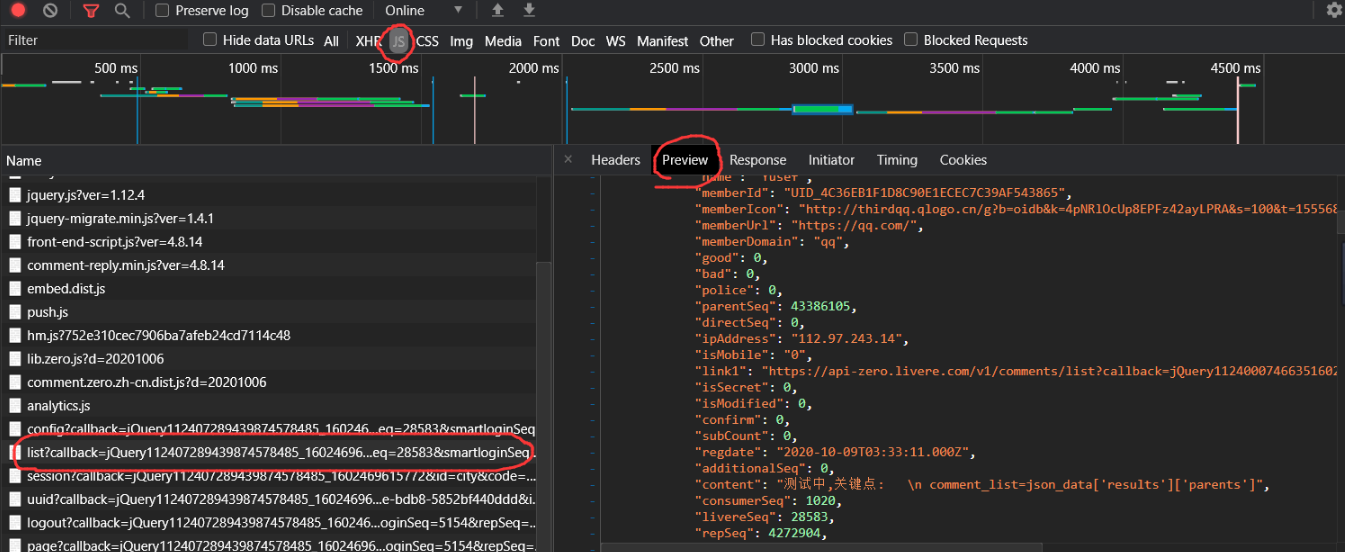
执行后,对数据进行爬取,添加注释并进行描述,并打印测试结果。

改进:仅将第一页上的注释爬到此处。所有评论都应被抓取。单击另一个页码以查找更多json文件:

如果单击这些Json文件并比较URL,则会看到参数存在差异。
此参数代表页数,offset = 1代表第一页。 (注意:第一次输入时,默认情况下,偏移量为1、并且可能没有偏移量参数,因此它不会出现在URL中)
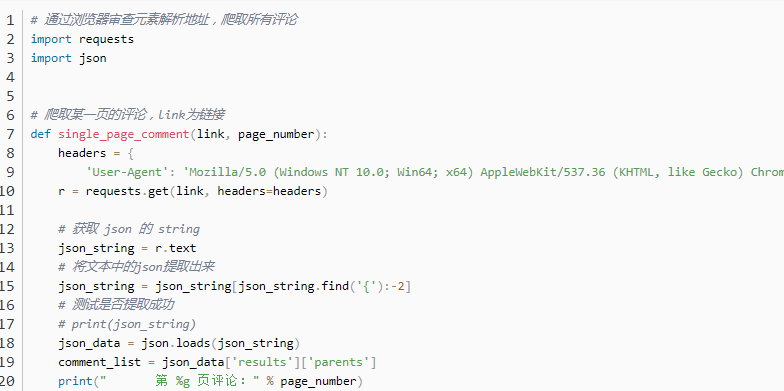
使用selenium模拟浏览器爬网
在以前的方法中,某些网站会加密地址以避免这些爬网,因此第二种方法
seleniuminstallation和测试 您可以使用。
如果您使用的是Firefox,则下载地址为
。其他浏览器可以使用百度
进行测试。代码如下:

使用以下代码抓取数据。请注意,注释位于iframe框架下方,因此您需要先解析iframe。因此,首先使用switch_to转移焦点。
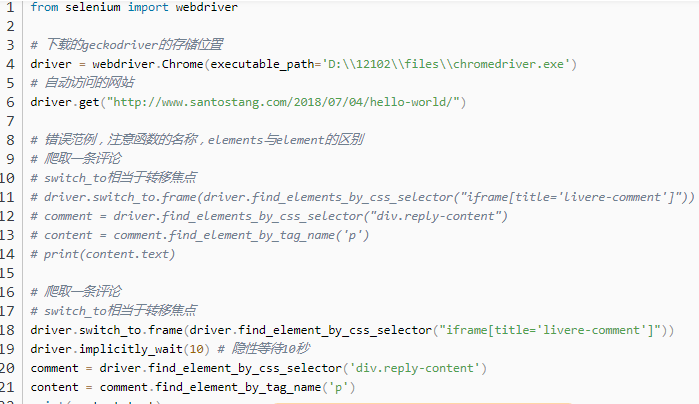
在此处添加了Driver.implicitly_wait(10)以隐式等待10秒。如果未添加此代码行,则iframe框架将花费很长时间加载,并且将报告错误,提示找不到div.reply-content。
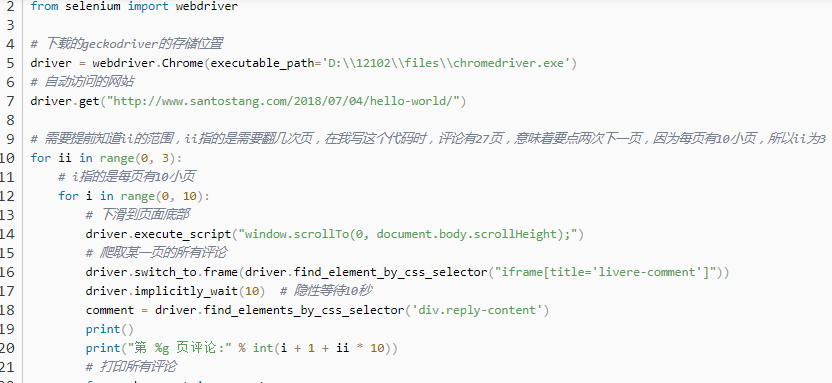
每页有10小页。浏览10页后,单击[下一页]共27页。一切都在嵌套的for循环中完成。外层代表1-10、11-20、21-27页,内层在每页上打印注释。在每页上打印评论的方法与抓取上一个评论的方法相同。参见下面的
代码,并有一个注释:
通常,Selenium趋向于减慢速度,因为它必须在开始抓取内容之前加载整个网页。但是,可以使用以下方法:禁用
图像,CSS和JS后,结果如下所示:

上面的代码使用fp = webdriver.FirefoxProfile()控制CSS的加载。要设置不加载CSS,请使用fp.set_preference(“ permissions.default.stylesheet ”,2)。然后使用webdriver.Firefox(firefox_profile = fp)来控制css不加载。运行上面的代码后,结果页面将显示在下面。
