一.函数的分类
1.函数:一般是在数据上执行的,它只是将取出的数据进行处理,不会改变数据库中的值
2.组合函数又称聚合函数:输入多个值,最终只会返回一个值
组函数仅可用于选择列表或查询的having字句
3.单行函数: 输入一个值,输出一个值
二.字符函数
1.concat:表示字符串的连接,等同于||
select concat('my name is ',ename) from emp;
2.将字符串的首字符大写
select initcap(ename) from emp;
3.将字符串全部转换为大写
select upper(ename) from emp;
4.将字符串全部转换为小写
select lower(ename) from emp;
5.填充字符串
select lpad(ename,10,'*') from emp; 若字符串不够10位,从左开始补充*
select rpad(ename,10,'*') from emp; 若字符串不够10位,从左开始补充*
6.去除空格
select trim(ename) from emp; 去除左右两边的空格
select ltrim(ename) from emp; 去除左边的空格
select rtrim(ename) from emp; 去除右边的空格
7.查找指定字符串的位置
select instr('ABABCD','A') from emp;
8.查看字符串的长度
select length(ename) from emp;
9.截取字符串的操作
select substr(ename,0,2) from emp;
10.替换操作
select replace('ababefg','ab','hehe') from emp;
二.数值函数
1.给小数进行四舍五入操作,可以指定小数部分的位数
select round(123.123 , 2) from dual;
2.截断数据,此时按照位数截取,但是不能进行四舍五入的操作
select trunc(123.123 , 2) from dual;
3.取模操作
select mod(10 , 4) from dual;
4.向上取整
select ceil(12.56) from dual;
5.向下取整
select floor(13.99) from dual;
6.取绝对值
select abs(-100) from dual;
7.获取正负值
select sign(-100) from dual;
8.x的y次幂
select power(2,3) from dual;
三.日期函数
1.mysql中时间:
select current_time() from xx;
2.mysql中日期:
select current_date() from xx;
3.mysql中日期加时间:
select current_timestamp() from dual;
4.oracle中日期函数:
select sysdate from dual;
select current_date from dual;
5.在当前时间上添加指定的月份:
select add_months(hiredate,2),hiredate from emp;
6.返回输入日期所在月份的最后一天:
select last_day(sysdate) from dual;
7.两个日期间隔的月份:
select months_between(syadate,hiredate) from emp;
8.返回四舍五入的第一天:

9. 返回下周的星期几:
select next_day(sysdate,'星期一') from dual;
10.提取日期中的时间:
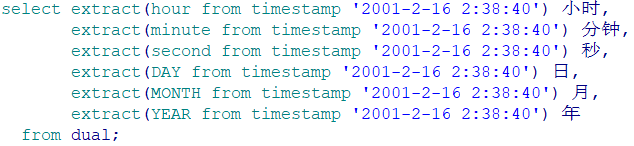
11. 返回日期的时间戳:
select localtimestamp from dual;
select current_date from dual;
select current_timestamp from dual;
12.给指定的时间单位增加数值:

四.转换函数
在oracle中存在数值的隐式转换和显式转换
隐式转换:字符串可以转换为数值或者日期
显式转换(to_char):当由数值或者日期转成字符串的时候,必须要规定格式
转换函数:
to_char、to_number、to_date
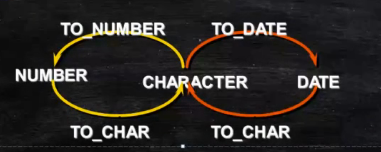
1.to_char:函数操作日期
date-->to_char:select to_char(sysdate,'YYYY-MM-SS HH24:MI:SS') from dual;
2.to_char:函数操作字符
number--> to_char:select to_char(123.456789,'9999') from dual;
select to_char(123.456789,'0000.00') from dual;
select to_char(123.456789,'$0000.00') from dual;
select to_char(123.456789,'L0000.00') from dual;
select to_char(123456789,'999,999,999,999') from dual;
3.to_date:函数操作字符串
to_date:转换之后都是固定的格式
select to_date('2019/10/10 10:10:10','YYYY-MM-DD HH24:MI:SS') from dual; 4.to_number:函数操作数字
select to_number('123,456,789','999,999,999') from dual;
五.条件函数
1.decode
给不同部门的人员涨薪,10部门涨10%,20部门涨20%,30部门涨30%
select ename,deptno,sal,decode(deptno,10,sal*1.1,20,sal*1.2,30,sal*1.3) from emp;
2.case when
给不同部门的人员涨薪,10部门涨10%,20部门涨20%,30部门涨30%
select deptno,case deptno when 10 then sal*1.1 when 20 then sal*1.2 when 30 then sal*1.3 end from emp;
六.组函数
一般情况下组函数都要和group by结合进行使用
1.avg:只用于数值类型的值
select avg(sal) from emp;
2.min:适用于所有类型的值
select min(sal) from emp;
3.max:适用于所有类型的值
select max(sal) from emp;
4.count:处理数值,跳过空值而处理非空值
一般用于获取表中记录条数,使用时可以使用*、某一具体的类或者数字来替代,从运行效率上看,建议使用数字或者某一具体的类,而不要使用*
select count(sal) from emp;
5.sum:只用于数值类型的值
select sun(sal) from emp;
6.group by :按照某些相同的值去进行分组操作
select avg(sal) from emp group by deptno;
注意:
group by进行分组操作的时候,可以指定一个列或者多个列,但是使用group by后选择列表中只能包含组函数值或者group by的普通字段
select deptno,avg(sal),ename from emp group by deptno; 会报错
因为你在进行了group by分组后,每个分组中的ename是不一样的
7.having:进行条件判断时我们通常使用where,但是使用where时仅限表中已有的字段,这时就要使用having
求平均薪水大于2000的部门
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;
8.限制输出
limit:仅在mysql中shiyong(select * from emp order by sal limit 5;)
注意:mysql中limit+数字n表示取前n条,limit +数字n,m表示从n条开始取,取m条
分页rownum:在oracle中不能直接使用rownum,需要嵌套使用
求薪水最高的前5名雇员
select * from (select * from emp e order by e.sal desc) t1 where rownum <= 5;
求薪水最高的6到10名雇员
错误写法:select * from (select * from emp e order by sal desc) where rownum >5 and rownum <=10;
错误原因:rownum会随着查询结果的变化而变化,先执行rownum>5,那么oracle会将前5条数据删除,从第6条数据开始的编号从1开始递增发生改变,即第6条数据编号变为1,第七条变为2。。。。这样数据就被破坏了
正确写法:先取出前10条数据,当取出前10条数据后,默认的rownum会显示,之后再将取出的值作为查询数据进行查询

七.SQL执行顺序
当select、from、where、group by、orger by这吴哥关键字同时存在sql中时
from > where > group by > select > order by
八.关联查询
92语法:多张表进行关联的时候关联条件会写在where条件后,用逗号分隔,这样会导致结构很乱
例如:select a.a1,b.b1,c.c1,d.d1 from a,b,c,d where a.a1=b.b1,b.b1=c.c1 ......;
1.等值连接:两个表中包含相同的列名
2.非等值连接:两个表中没有相同的列名,但是某一个列在另一张表的列的范围之中
3.左外连接:把左表的全部数据显示
右外连接:把右表的全部数据显示
自连接:将一张表当成不同的表来看待,自己关联自己
例如:将雇员和他经理的名称查出来
select e.ename,m.ename from emp e,emp m where e.mgr = m.empno;
笛卡尔积:当关联多张表,但是不指定连接条件的时候,会进行笛卡尔积
关联后的总记录数为m*n
select * from emp e,dept d;
99语法:关联条件写在on后,结构清晰
1.cross join:等同于92语法中的笛卡尔积
select * from emp cross join dept;
2.nature join:自然连接,相当于等值连接,但是不需要写连接条件,会从两张表中找到相同字段进行连接。若两张表中不具有相同的列名的时候会进行笛卡尔积操作。
select * from emp e nature join dept d;
3.on子句:添加连接条件
select * from emp e join dept d on e.deptno = d.deptno;
4.left outer join:左外连接,会将左表中的数据完全显示,右表中没有的会显示空
select * from emp e left outer join dept d on e.deptno = d.deptno;
5.right outer join:右外连接,会将右表中的数据完全显示,左表中没有的会显示空
select * from emp e right outer join dept d on e.deptno = d.deptno;
6.全连接:相当于左外连接和右外连接的合集
select * from emp e full join dept d on e.deptno = d.deptno;
注意:左外连接、右外连接和全连接中的outer可以不写
7.inner join:两张表的连接查询,只会查询出有匹配记录的数据
select * form emp e inner join dept d on e.deptno = d.deptno;
8.using:除了可以使用on表示连接条件之外,也可以使用using作为连接条件,此时连接条件的列不再归属任何一张表
select * from emp e join dept d using(deptno); emp表与dept表中都存在deptno字段,但是当使用using连接时,deptno字段不再属于任何一张表。
select e.deptno from emp e join dept d using(deptno); 不会查询出来结果,因为deptno不属于任何一张表,所以查询不出结果。
九.子查询
sql允许多层嵌套,子查询,即嵌套在其他查询中的查询
例如:查询薪水在整个雇员薪水之上的员工
select * from emp e where e.sal > (select avg(sal) from emp);