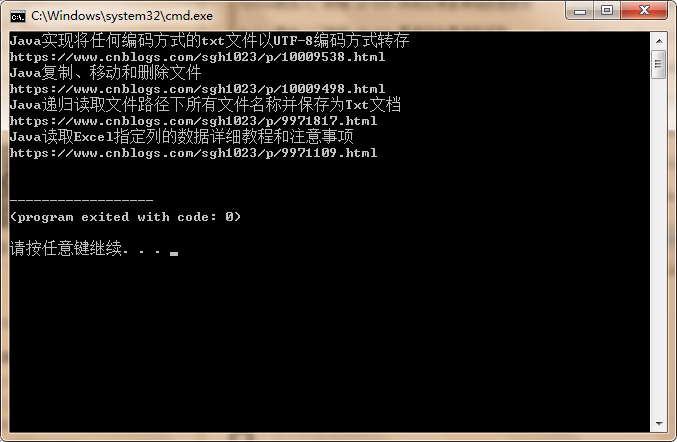
通过昨天对python爬取数据的学习,对自己的博客地址进行了爬取
获取网页使用requests ,提取信息使用Beautiful Soup,存储使用txt就可以了。
# coding: utf-8
import re
import requests
from bs4 import BeautifulSoup
def get_blog_info():
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Ubuntu Chromium/44.0.2403.89 '
'Chrome/44.0.2403.89 '
'Safari/537.36'}
html = get_page(blog_url)
soup = BeautifulSoup(html, 'lxml')
article_list = soup.find('div', attrs={'id': 'mainContent'})
article_item = article_list.find_all('div', attrs={'class': 'postTitle'})
for ai in article_item:
title = ai.a.text
link = ai.a['href']
print(title)
print(link)
write_to_file(title+' ')
write_to_file(link+'
')
def get_page(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Ubuntu Chromium/44.0.2403.89 '
'Chrome/44.0.2403.89 '
'Safari/537.36'}
response = requests.get(blog_url, headers=headers, timeout=10)
return response.text
except:
return ""
def write_to_file(content):
with open('article.txt', 'a', encoding='utf-8') as f:
f.write(content)
if __name__ == '__main__':
blog_url = "https://www.cnblogs.com/sgh1023/"
get_blog_info()