20191312 2019-2020-2 《Python程序设计》实验三报告
课程:《Python程序设计》
班级: 1913
姓名: 刘新宇
学号:20191312
实验教师:王志强
实验日期:2020年5月31日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
- 实验要求
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
2. 实验过程及结果
创建函数:
需求功能:发送请求获得返回数据、解析获得数据、输出解析后的数据。
需要调用的库:re、requests。
- getHTMLText函数:对服务器发送请求并获得返回数据。
def getHTMLText(url):
try:
header = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'referer': 'https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '********************************', # 这里cookie被去除
}
r = requests.get(url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "F"
- parsePage函数:通过正则表达式对获得的html文本进行解析,获得我们想要得到的内容。
def parsePage(ilt, html):
try:
plt = re.findall(r'"view_price":"[d+.]*"', html)
tlt = re.findall(r'"raw_title":".*?"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("F")
- printGoodsList函数:输出解析过的内容,同时使用正则表达式对输出进行格式化。
def printGoodsList(ilt):
tplt = "{:4} {:8} {:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
- main函数:调用之前编写的函数,实现爬取淘宝商品信息的目标。
def main():
goods = input("输入你要搜索的商品:")
depth = 2
start_url = "https://s.taobao.com/search?q=" + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
运行截图:
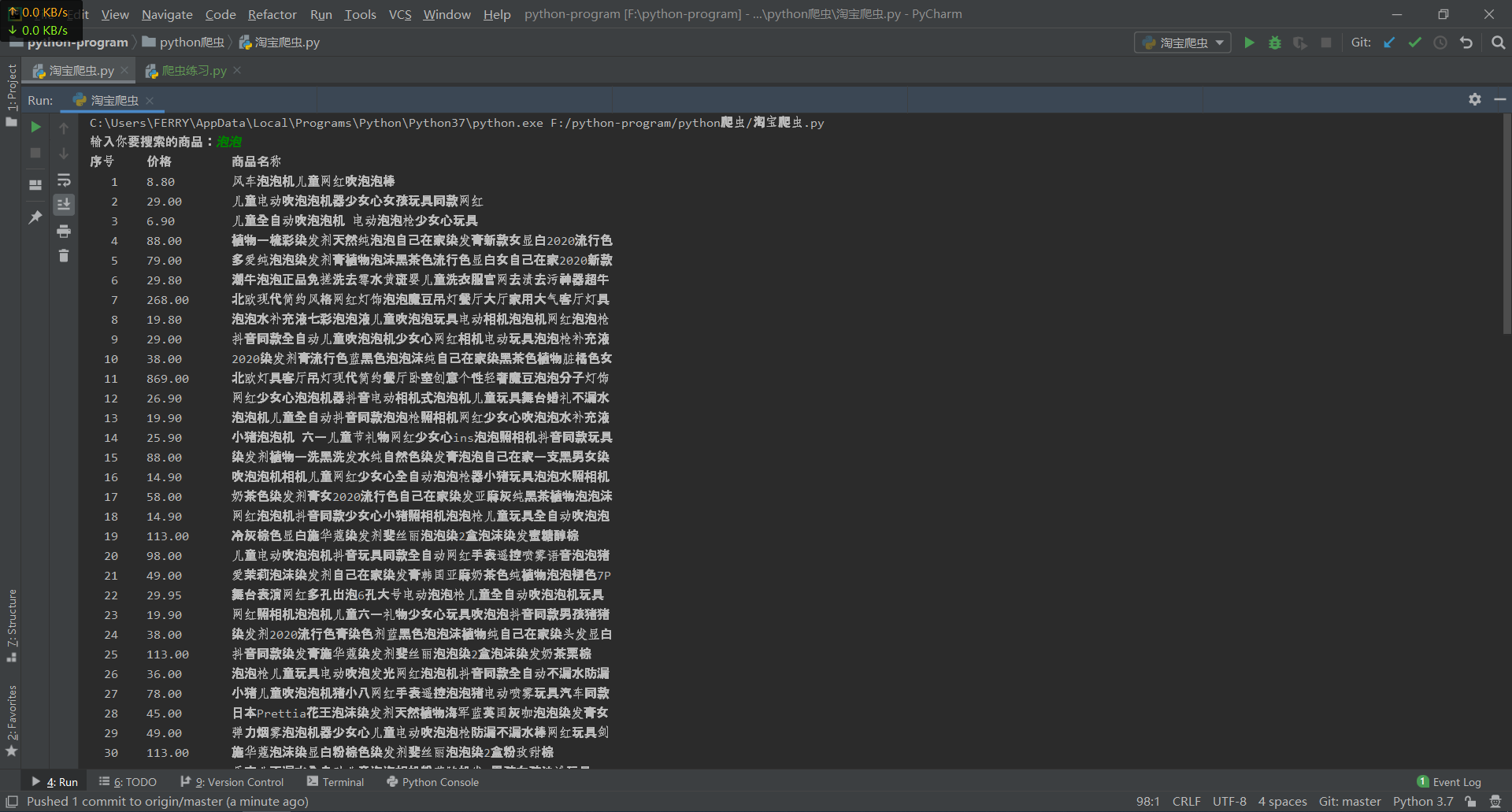
完整代码链接:https://gitee.com/python_programming/lxy20191312/blob/master/python爬虫/淘宝爬虫.py
3. 实验过程中遇到的问题和解决过程
- 问题1:程序运行没有输出。
- 问题1解决方案:检查请求状态码,发现状态码为200,能够正常访问。查找资料后发现,我参考的资料为2018年之前的资料,淘宝后来增设了反爬虫机制。需要通过如下办法绕开反爬虫机制:
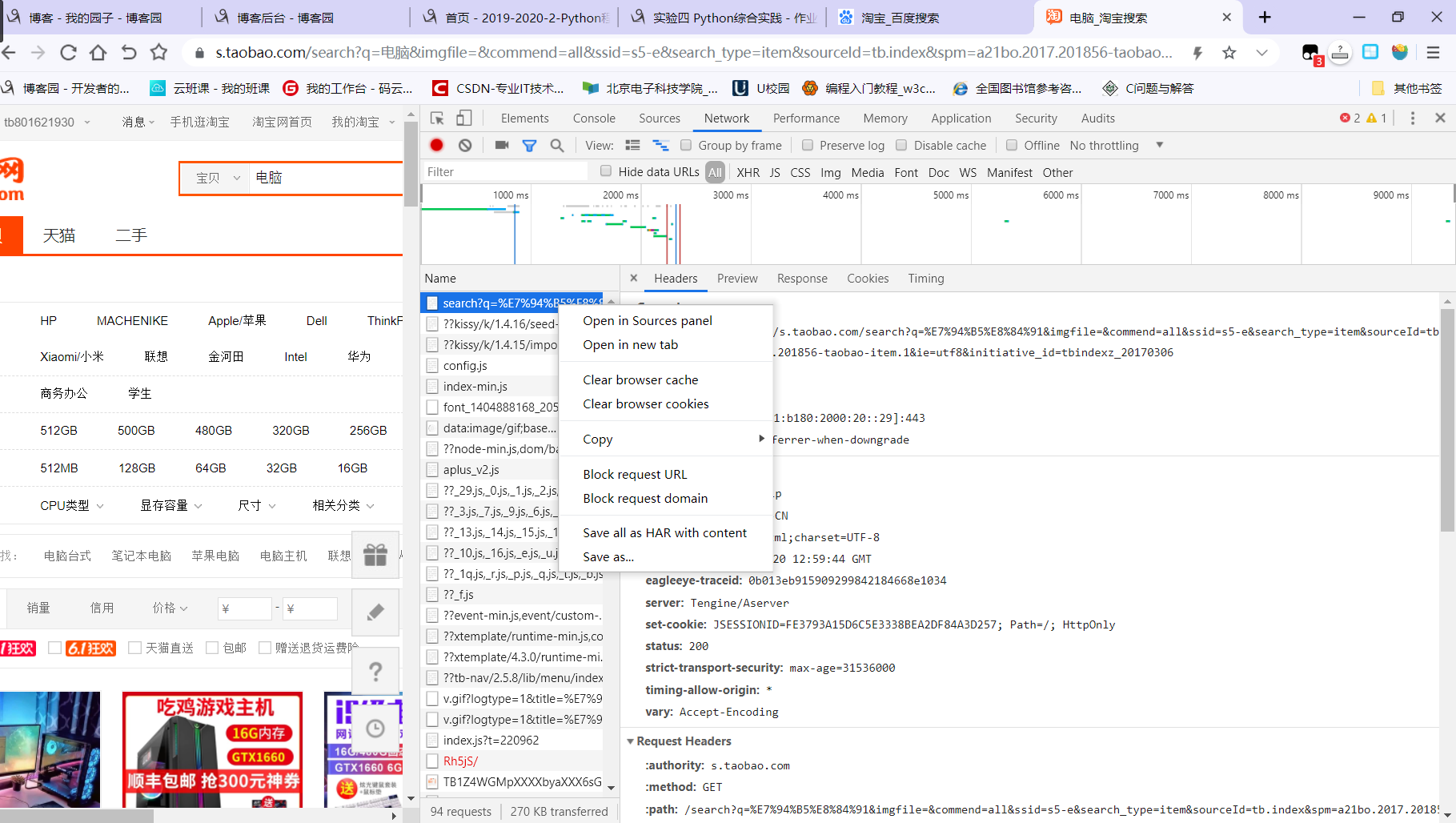

将上面复制的内容粘贴到https://curl.trillworks.com/,就可以得到headers,使用这个headers就能正常爬取商品信息了。
课程感想
通过一学期对python的学习,我对python这门语言有了更加深入的了解。python的库十分丰富,功能强大,品类繁多。通过这么长时间对python这一语言的学习,我深切地感受到了python的优点。在王老师的指导下,我这个学期进行了很多的编程实践,虽然没有很优秀的作品,但是对于我来说,能够亲手实现一些以前从来没有编写过的程序确实是满满的成就感。希望自己在接下来的时间中,继续学习python,亲手写出更多有意思的程序。