插入排序:
1).直接插入排序:
假设当前排序到了第i个元素arr[i],则此时i左侧[0,i-1]已经有序,对于arr[i]来说,如果arr[i]>=arr[i-1],则不用排序,直接进入[i+1];否则要在左侧有序表中找到一个合适的位置j令arr[j]<=arr[i]<arr[j+1]。
每一趟插入排序,令当前有序表的长度增加1,直至有序长度等于数组长度。
class Solution {
public:
void InsertSort(vector<int>& arr){
if(arr.empty())
return;
for(int i=1;i<arr.size();i++)
{
if(arr[i]<arr[i-1])
{
int tmp=arr[i];
arr[i]=arr[i-1];
int j=i-2;
for(;j>=0&&arr[j]>tmp;j--)
arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
return;
}
};
2).折半插入排序:
和普通的直接插入排序相比,折半插入排序利用了左侧有序表的特性,利用折半查找减少了查询次数,但移动次数仍然未改变。
class Solution {
public:
void BInsertSort(vector<int>& arr){
if(arr.empty())
return;
for(int i=1;i<arr.size();i++)
{
int low=0,high=i-1;
while(low<=high)
{
int mid=(low+high)/2;
if(arr[mid]>arr[i])
high=mid-1;
else
low=mid+1;
}
int tmp=arr[i];
for(int j=i-1;j>=high+1;j--)
arr[j+1]=arr[j];
arr[high+1]=tmp;
}
}
};
3).希尔排序:
直接插入排序与折半排序都没有实际上减少移动次数,折半排序优化的是比较次数。
希尔排序的思想在于:
如果一个序列是正序的,则对它进行排序只用比较n-1次,而不用移动。因此,如果对于某个待排点i来说,如果i左侧的数组能够基本有序(不是完全有序),则它移动的次数将减少。
希尔排序每一趟排序中,根据增量将序列分为若干组,每一组进行一个直接插入排序,这样每一组都是有序的,再将他们组合起来,也就是说,每一组都将这组的数据小的往前置顶,大的往后置后,则合并起来时相对整个数组来说,它的小数据集中到了前段,大数据集中到了后端,尽管不同的子组间的大小没有确定,但对于数组整体来说,它比这一趟希尔排序前变得更有序了。
等到下一趟排序时,减小增量。减小增量代表在上一趟希尔排序的相对有序的基础上重整上一趟排序时子组间的相对大小。
这样,每进行一趟希尔排序,数组的有序情况得到一定改善,直到最后增量为1时,相对来说比最初的数组的有序性更强了,在进行一次完整的直接插入排序,这样减少了插入过程中的移动次数。
class Solution {
public:
void ShellSort(vector<int>& arr)
{
vector<int> dk;
dk.push_back(5);
dk.push_back(3);
dk.push_back(1);
for(int i=0;i<dk.size();i++)
SortCore(arr,dk[i]);
}
void SortCore(vector<int>&arr,int dk)
{
for(int i=dk;i<arr.size();i++)
{
if(arr[i]<arr[i-dk])
{
int tmp=arr[i];
int j=i-dk;
for(;j>=0&&arr[j]>tmp;j=j-dk)
arr[j+dk]=arr[j];
arr[j+dk]=tmp;
}
}
}
};
交换排序:
交换排序,藉由交换进行排序的方法。
1).冒泡排序:
class Solution { public: void BubbleSort(vector<int>& arr) { if(arr.empty()) return; for(int i=0;i<arr.size()-1;i++) { for(int j=0;j<arr.size()-i-1;j++) { if(arr[j]>arr[j+1]) swap(arr[j],arr[j+1]); } } } };
2).快速排序:
定义一个操作Partition,对数组的某个位置i进行Partition,将使该数组中所有小于等于arr[i]的元素都在i的左侧,使所有大于arr[i]的元素都在i的右侧。
继续对i的左侧和右侧继续进行Parition,直到最后,数组整体有序。
class Solution {
public:
void QSort(vector<int>& arr)
{
if(arr.empty())
return;
QsortCore(arr,0,arr.size()-1);
return;
}
private:
void QsortCore(vector<int>& arr,int low,int high)
{
if(high<=low)
return;
int mid=Partition(arr,low,high);
QsortCore(arr,low,mid-1);
QsortCore(arr,mid+1,high);
}
int Partition(vector<int>&arr,int low,int high)
{
int tmp=arr[low];
while(low<high)
{
while(low<high&&tmp<=arr[high])
high--;
arr[low]=arr[high];
while(low<high&&tmp>=arr[low])
low++;
arr[high]=arr[low];
}
arr[high]=tmp;
return low;
}
};
快排的退化:
快排用的是分治的思想,拆解开后一般就是一颗二叉树的深度是log n,每一层进行交换的复杂度为n,所以为n log n;最坏的情况就是数组刚好有序,这种情况下树的深度为n,因此整体复杂度将退化为n^2.
也就是说,快排的复杂度与输入序列的顺序有关。
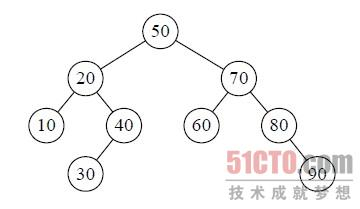
最理想的一种就是下图所示,序列为:{50,10,90,30, 70,40,80,60,20},每次找到的Parition的值刚好是中间值(默认Paritition的位置是数组的第一个元素)。
而如果数组是有序的,则相当于构造了一个{10,20,30,40,50,60,70,80,90},第一次Parition位置在10,从high一直搜索到20位置。第二次在10右侧的20进行Parition,.......,如此下去,复杂度成为n^2。一个有序的输入序列,相当于构造了一个深度为n的单枝树,而每一次Partition都要搜索n,相当于O(n^2)的复杂度。
选择排序:
每一趟选择一个从n-i个元素中选择一个最小的,放置在第i个位置。这样n-1轮后将数组有序。
1).简单选择排序:
class Solution {
public:
void Selectsort(vector<int>& arr)
{
if(arr.empty())
return;
for(int i=0;i<arr.size()-1;i++)
{
int idx=0,min=INT_MAX;
for(int j=i;j<arr.size();j++)
{
if(arr[j]<min)
{
min=arr[j];
idx=j;
}
}
swap(arr[i],arr[idx]);
}
return;
}
};
2).堆排序:
构建一个堆,堆满足每个节点都比他的孩子节点大(大顶堆)或小(小顶堆)。这样每次将根节点的值与数组最后的数交换,新的树中除了根节点外,其他的子树仍满足堆的定义。因此只要对根节点进行调整,即可形成一个新的堆,且最大值已经移动到数组尾,下一次交换新的根节点和n-1处的值。
升序:
class Solution
{
public:
void HeapSort(vector<int>& arr)
{
if(arr.empty())
return;
for(int i=arr.size()/2-1;i>=0;i--)
HeapSortCore(arr,i,arr.size()-1);
for(int i=arr.size()-1;i>0;i--)
{
swap(arr[0],arr[i]);
HeapSortCore(arr,0,i-1);
}
return;
}
private:
void HeapSortCore(vector<int>& arr,int pos,int end)
{
int tmp=arr[pos];
int i=2*pos+1;
for(;i<=end;i=2*i+1)
{
if(i<end&&arr[i]<arr[i+1])
i++;
if(tmp>=arr[i])
break;
arr[pos]=arr[i];
pos=i;
}
arr[pos]=tmp;
}
};
降序:
class Solution
{
public:
void HeapSort(vector<int>& arr)
{
if(arr.empty())
return;
for(int i=arr.size()/2-1;i>=0;i--)
HeapSortCore(arr,i,arr.size()-1);
for(int i=arr.size()-1;i>0;i--)
{
swap(arr[0],arr[i]);
HeapSortCore(arr,0,i-1);
}
return;
}
private:
void HeapSortCore(vector<int>& arr,int pos,int end)
{
int tmp=arr[pos];
int i=2*pos+1;
for(;i<=end;i=2*i+1)
{
if(i<end&&arr[i]>arr[i+1])
i++;
if(tmp<=arr[i])
break;
arr[pos]=arr[i];
pos=i;
}
arr[pos]=tmp;
}
};
堆排的特点在于它形成的结构一定是接近于完全二叉树,而不会像快排一样由于输入的不同而形成单支树,因此堆排在最坏情况下也依然为nlogn的时间复杂度。堆排由于第一次需要进行堆的初始化来建设初始堆,因此比其他排序多了初始堆建设的复杂度,因此不提倡应用于记录数较小的情况。
归并排序:
采用分治的思想,将整个数组分为两个数组,两个数组排序后在整合为一个有序数组。
严蔚敏的写法真的实属睿智
class Solution
{
public:
void MSort(vector<int>& arr)
{
if(arr.empty())
return;
MSortCore(arr,0,arr.size()-1);
}
private:
void MSortCore(vector<int>& arr,int start,int end)
{
if(start>=end)
return;
int mid=(start+end)/2;
MSortCore(arr,start,mid);
MSortCore(arr,mid+1,end);
int p1=start,p2=mid+1;
vector<int> tmp;
while(p1<=mid&&p2<=end)
{
if(arr[p1]<=arr[p2])
{
tmp.push_back(arr[p1]);
p1++;
}
else
{
tmp.push_back(arr[p2]);
p2++;
}
}
if(p1<=mid)
{
for(int i=p1;i<=mid;i++)
tmp.push_back(arr[i]);
}
if(p2<=end)
{
for(int i=p2;i<=end;i++)
tmp.push_back(arr[i]);
}
for(int i=start;i<=end;i++)
{
arr[i]=tmp[i-start];
}
return;
}
};