ElasticSearch入门
一、ElasticSearch介绍
1、概述
ElasticSearch是基于Apache组织的Lucene开源搜索引擎开发的一个搜索引擎。
ElasticSearch编写的目的是使用简单的RESTfulAPI来实现全文搜索并摒弃Lucene的复杂操作。
除此之外,ElasticSearch还提供了:
(1)分布式的文件存储,存入的数据中每个字段都经过索引并可以通过API来搜索。
(2)实时分析的分布式搜索引擎。
(3)可以扩展到上百台的服务器上,处理海量级别的结构化或非结构化数据。
2、重要概念
(1)接近实时(NRT)
ElasticSearch得于Lucene的支持,它是一个趋近于实时的搜索引擎。它从索引一个文档到能通过搜索API搜索到这个文档,仅仅有一个忽略不计的延迟(1秒左右)。
(2)集群(Cluster)
由于ElasticSearch能支持海量数据搜索,所以集群是必要的。用户可以通过配置一个集群标识(默认是ElasticSearch),让其他节点加入这个集群,实现比如数据的分离和搜索的引导。
(3)节点(Node)
节点就是集群中的一个服务器,它作为集群的一部分,可以通过主备来实现主节点和备用节点,并存储用户的数据。如果在所有ElasticSearch服务器中没有运行任何一个节点,那么它会默认创建并加入一个ElasticSearch集群。
(4)索引(Index)
一个索引就是一个文档的集合,可以理解成关系型数据库中Database的概念,一个索引由它的名字(必须是小写字母)来作为标识,后续可以通过这个索引对文档进行增删改查的操作。
倒排索引:通过关键字来查找,这是ElasticSearch中全文检索速度快的原因。
正排(正向)索引:在关系型数据库中使用id等字段作为索引。
(5)类型(Type)
一个类型是一个索引的子类,多个类型组成了一个索引。类型主要存有一些拥有共同字段的文档。可以理解成关系型数据库中Table的概念。
(6)文档(Document)
一个文档是ElasticSearch中可以被搜索到的基础信息。在ElasticSearch中主要是使用JSON的格式来表示,你可以存有一个用户的文档,他的订单文档等。文档中除了这些数据外,还包括有_index、_type和_id字段。
(7)分片(Shards)
一个索引中能够存储超过某个节点硬件限制的数据,前提是对其进行了分片操作。比如一个索引占用了超过1TB的空间,但是在集群中没有任何一个节点有1TB的容量,此时就会对这个索引进行分片操作。当然,这也是为了能够将搜索的速度进行最优操作。
在创建一个索引的时候,可以指定分片的数量,此时由于定义了分片操作,这个索引可以在集群中的任何节点上找到。
在分片中,能够实现这两个重要的功能:
·可以通过分片来扩展某个索引的容量,以及实现数据的分割。
·实现分片后可以在集群中进行分布式/并行的操作,进而提高集群的处理能力。
(8)复制(Replicas)
在任何一个系统中,出现宕机等问题的可能性随时都会发生,ElasticSearch也不例外。
ElasticSearch提供了一种索引备份的机制,它允许用户创建分片的复制分片。
复制分片不会和原分片在同一个节点上,因为如果在集群中,某个节点发生宕机,如果同时存在于同一个节点上的话,此时这个索引备份机制是没有意义的。
在索引创建后,用户可以随时改变复制数量,但不能改变分片的数量,因为改变分片的数量时是会进行数据的重新切割,而复制则不会对分片造成任何影响。
默认情况下,ElasticSearch的每个索引会被设置成5个分片和1个复制索引,当然这是在有至少两个节点的前提下,如果只有一个节点,那么分片没有任何意义。
二、下载与启动
1、前置条件
环境说明:
服务器:阿里云轻量应用服务器
操作系统:CentOS8.2
内存:2G
ElasticSearch版本:7.15.1
运行ElasticSearch需要在服务器上安装jdk
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
2、下载tar.gz文件
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.1-linux-x86_64.tar.gz
3、解压
tar -vxf elasticsearch-7.15.1-linux-x86_64.tar.gz
4、ElasticSearch目录说明
| 目录 | 配置文件 | 描述 |
|---|---|---|
| bin | 放置脚本文件,如启动脚本 ElasticSearch, 插件安装脚本等。 | |
| config | elasticserch.yml | ElasticSearch配置文件,如集群配置、jvm 配置等。 |
| jdk | java 运行环境 | |
| data | path.data | 数据持久化文件 |
| lib | 依赖的相关类库 | |
| logs | path.log | 日志文件 |
| modulElasticSearch | 包含的所有 ElasticSearch 模块 | |
| plugins | 包含的所有已安装的插件 |
5、新用户配置
由于ElasticSearch不能使用root用户启动,所以需要新建一个elastic用户
CentOS8的添加用户命令
adduser elastic
给elastic用户赋予权限(使用root账号)
chown -R elastic:elastic /software/elasticsearch-7.15.1
6、启动
使用elastic用户,进入对应文件夹的bin目录下
使用命令启动,-d是在后台运行
./elasticsearch -d
7、验证
使用命令
curl localhost:9200
最终控制台显示以下内容就成功启动了
{
"name" : "iZax8lw98s1xu9Z",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "D-A_yUfpSrmgxThbKSox6Q",
"version" : {
"number" : "7.15.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "83c34f456ae29d60e94d886e455e6a3409bba9ed",
"build_date" : "2021-10-07T21:56:19.031608185Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
8、注意事项
(1)远程访问需要修改elasticsearch.yml中的network.host属性,将其改成0.0.0.0
(2)报错提示
bootstrap check failure [1] of [3]: max file dElasticSearchcriptors [4096] for elasticsearch procElasticSearchs is too low, increase to at least [65535]
需要打开/etc/security/limits.conf文件
在结尾增加以下内容,其中elastic为创建的新用户
elastic soft nofile 65536
elastic hard nofile 65536
(3)报错提示
bootstrap check failure [2] of [3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
需要打开/etc/sysctl.conf文件
在结尾增加以下内容
vm.max_map_count=262144
(4)报错提示
bootstrap check failure [3] of [3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodElasticSearch] must be configured
需要进行对discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodElasticSearch其中一个的配置
配置内容如下
# 启动地址,如果不配置,只能本地访问
network.host: 0.0.0.0
# 节点名称
node.name: node1
# 初始化时master节点的选举列表
cluster.initial_master_nodElasticSearch: [ "node1" ]
# 集群名称
cluster.name: elasticsearch
# 对外提供服务的端口
http.port: 9200
# 内部服务端口
transport.port: 9300
# 跨域支持
http.cors.enabled: true
# 跨域访问允许的域名地址(正则)
http.cors.allow-origin: /.*/
三、ElasticSearch RESTful API的使用
ElasticSearch提供了非常多的基于HTTP协议的RESTful API,只需要向ElasticSearch发送RESR请求,就可以实现它提供的一系列功能。
目前的资料中大部分是使用的Linux的curl命令来发送请求,我使用Postman来发送,因为它图形化,并且相对于命令也更容易操作
1、健康检查
健康检查主要用来查看集群的运行情况,由于只有一个节点,所以暂时不用了解太多。
URL格式(GET)
/_cat/health?v
其中?v主要用来显示字段
最终效果如图所示

其中,status为green表示正常,其他的还有yellow(所有数据都可用但复制分片不可用)、red(部分数据不可用)。
2、获取集群中节点列表
URL格式(GET)
/_cat/nodes?v
从下图可以看到集群中只有一个名为node1的节点。

3、创建索引
URL格式(PUT)
/索引名
acknowledged为true表示索引创建成功,由于默认是进行了分片操作的,所以shards_acknowledged也为true,index则表示索引名称。

4、列出索引
URL格式(GET)
/_cat/indices?v
节点中有一个默认的索引,另外有一个index1的索引,index1索引的health为yellow,是因为现在节点只有一个,不能对分片进行复制,等到添加第二个节点的时候就会恢复成green。

5、创建文档
创建了索引之后就可以把文档存入到ElasticSearch中了。
URL格式(PUT/POST)
/索引名/_doc/文档id
/索引名/_create/文档id
ps:由于ElasticSearch在6.X版本之后就要逐步移除类型(Type)的概念,所以类型就不写上去了,直接用_doc代替。
需要向这个URL发送一个PUT请求,并在请求中带入一个JSON字符串,此时ElasticSearch会返回一个存入的状态,其中各个字段表示如表格所示
| 字段 | 含义 |
|---|---|
| _index | 索引,用于表示当前文档是在哪个索引中 |
| _type | 类型,用于表示当前文档是在哪个类型中 |
| _id | id,文档的id |
| _version | 版本,文档的版本,如果对其进行了操作,那么这个值会增加 |
| result | 结果,有created,updated,deleted等情况,表示新增,更新,删除 |
| _shards | 分片情况 |
| _seq_no | 索引的序列号 |
| _primary_term | 和_seq_no组合使用 |
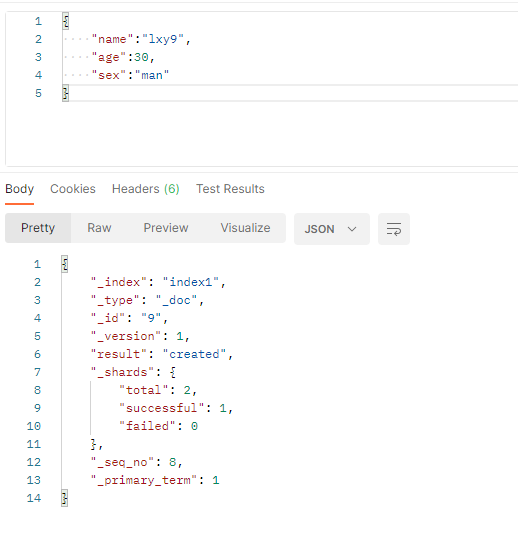
当索引不存在时也能存入文档,当索引不存在时,会自动创建索引
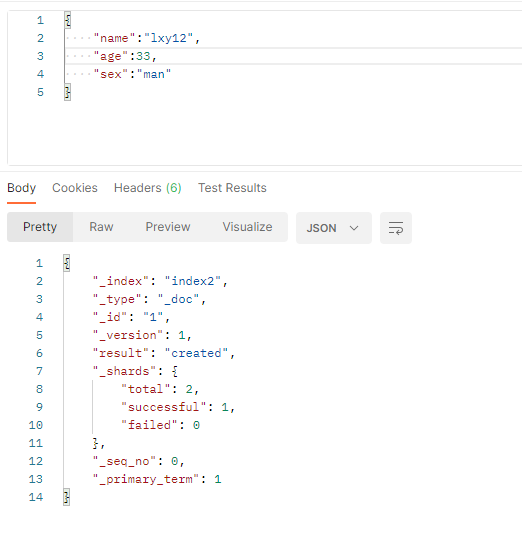
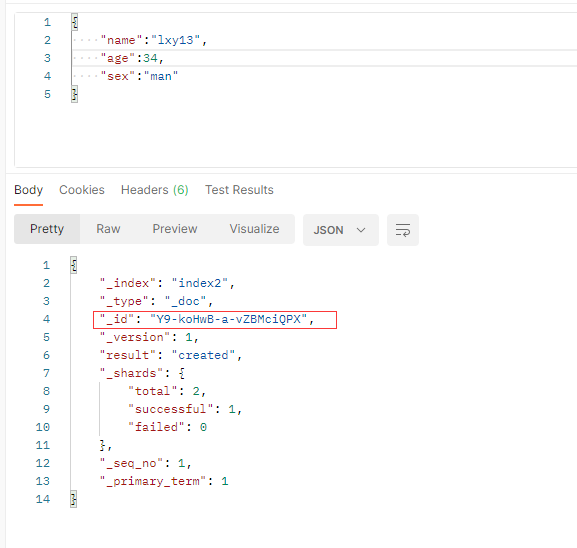
当文档id不存在时也能创建文档,此时id会由系统自动生成,但需要发送POST请求而不是PUT
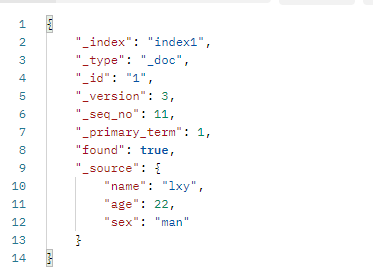
6、查询文档
URL格式(GET)
/索引名/_doc/文档id
其中found字段为true表示找到了id为1的文档,_source是文档的具体内容。
7、查询索引下的所有文档
URL格式(GET)
/索引名/_search
ps:这种方式只能查询到10条,如果要查询到所有的数据,可以使用分页的查询条件。
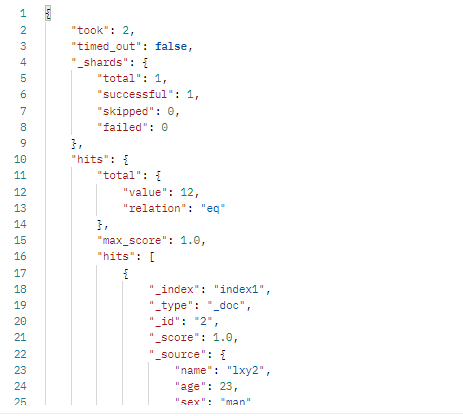
其中各个字段的说明:
| 字段 | 含义 |
|---|---|
| took | ElasticSearch搜索所使用的时间(毫秒) |
| timed_out | 是否超时 |
| _shards | 搜索的分片信息 |
| hits | 搜索结果 |
| hits.total | 搜索命中信息 |
| hits.hits | 搜索结果 |
| hits._score/max_score | score是判断搜索条件匹配程度的指标,分数越高文档和搜索条件越相关 |
8、更新文档
URL格式(POST/PUT)
1、/索引名/_update/更新的文档id(POST)
2、/索引名/_doc/更新的文档id(PUT)
参数格式
1、
{
"doc":{
//更新的内容
}
}
2、
{
//更新的内容
}
更新文档和创建文档的方式是一样的,如果创建的文档已存在,那么就会自动更新它。
如果文档不存在则自动创建。(仅限_doc的方式)
此时result的值是updated,_version的值也增加。

9、删除文档
URL格式(DELETE)
/索引名/_doc/删除的文档id
此时result的值是deleted,_version也变成了3.
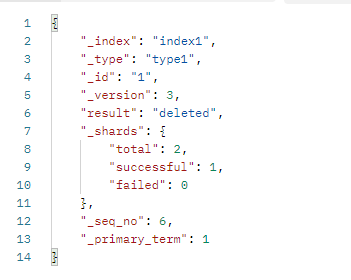
10、删除索引
URL格式(DELETE)
/索引名
执行后会返回true,表示已经删除成功。

这时再查询索引,已经没有了。

11、搜索文档
(1)按条件搜索文档
URL格式(GET)
/索引名/_search
参数格式
{
"query":{
"match":{
//搜索条件:key:value
//match表示匹配,可以替换成match_all,表示查询所有
}
}
}
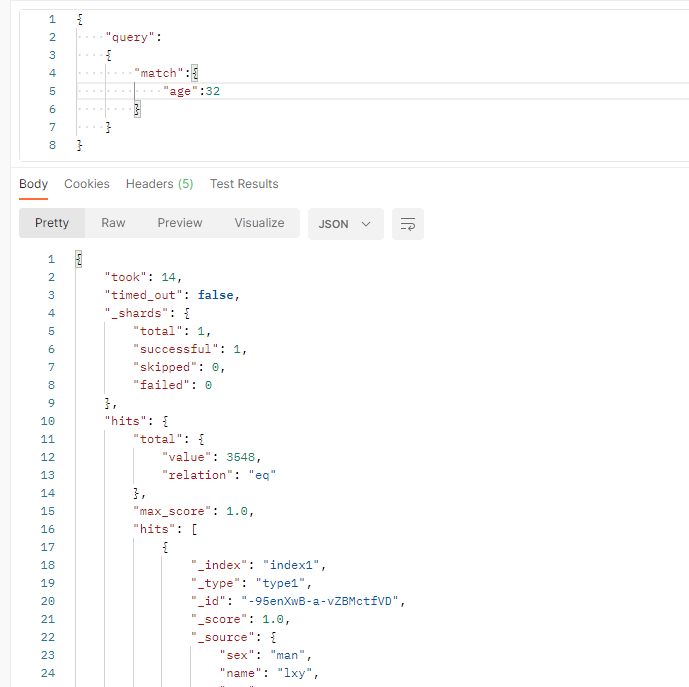
(2)分页查询
参数格式
{
"query":{
"match":{
//搜索条件
}
},
"from":0,
"size":20
//表示从0开始搜索,返回20条数据
}
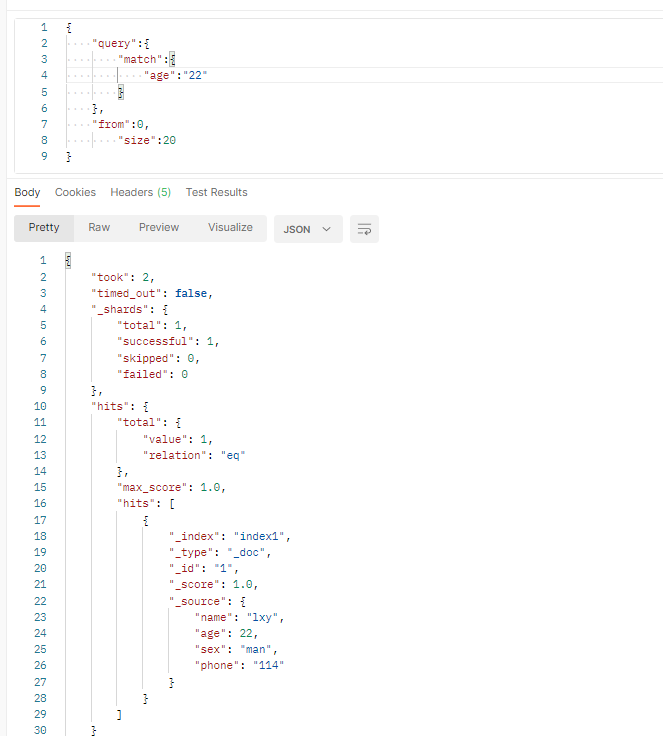
(3)排序
参数格式
{
"query":{
"match_all":{//查询所有
}
},
"sort":{
"age":{//表示按年龄排序
"order":"asc"//表示排序方式是升序
}
}
}
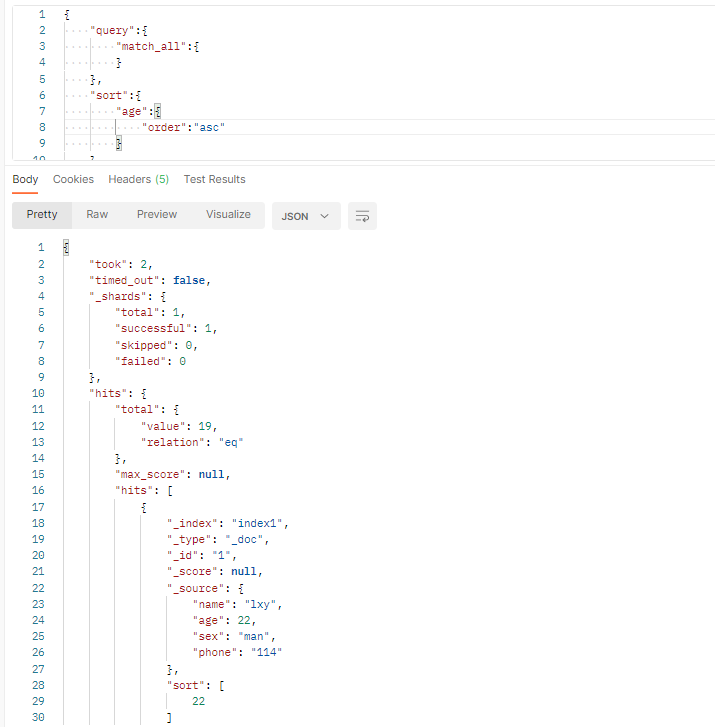
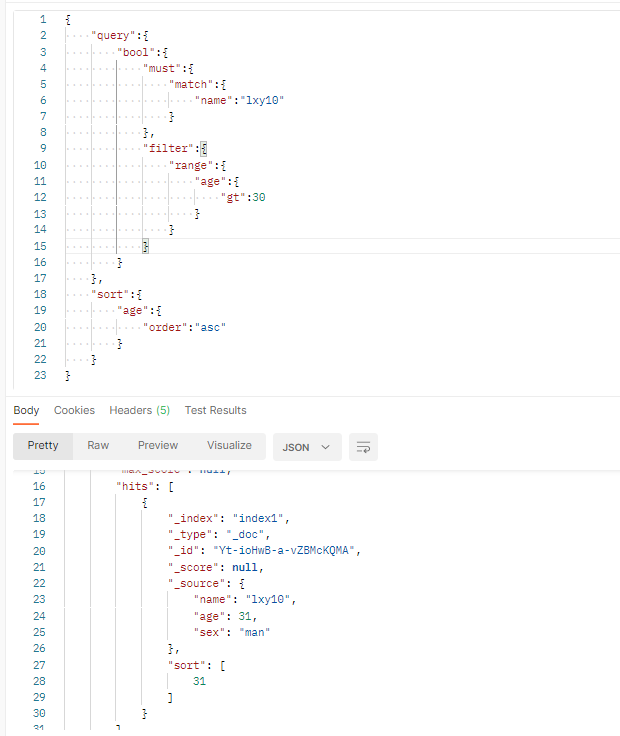
(4)数据过滤
参数格式
{
"query":{
"bool":{
"must":{
"match":{
"name":"lxy10"
}
},
"filter":{
"range":{
"age":{
"gt":30
}
}
}
}
},
"sort":{
"age":{
"order":"asc"
}
}
}
上面查询条件表示name是"lxy10",并且年龄大于30,最后按照年龄的升序排序。
12、全文检索
(1)全文检索
全文检索时会将用户输入的字符串给拆分出来,然后去倒排索引里面一一匹配,只要能匹配到某一个字或单词,那么就将结果返回。
URL格式(GET)
/索引名/_search
参数格式
{
"query":{
"match":{
//搜索条件,可以是完整的名称,也可以是一个字或单词
}
}
}
(2)短语搜索
和全文检索相反,短语检索是必须要完全匹配才能将结果返回。
参数格式
{
"query":{
"match_phrase":{
//搜索条件,必须和结果中包含了一样的才会返回
}
}
}
(3)高亮搜索结果
高亮搜索结果主要是将查询的条件给高亮出来,效果参考百度搜索。
{
"query":{
"match":{
//搜索条件
}
},
"highlight":{
"fields":{
//高亮字段
}
}
}
13、聚合
使用聚合检索可以对结果进行统计,如求平均或求和等运算。
在进行聚合检索之前,需要对文档的属性进行调整。
(1)文档属性调整
URL格式(POST)
/索引名/_mapping
参数格式
{
"properties":{
"name":{
"type":"text",//text表示这个属性能够被分词
"index":true,//true表示加入索引
"fielddata":true//存储的数据结构是fielddata
},
"category":{
"type":"keyword"
},
"price":{
"type":"long",
"index":true
}
}
}
ps:这个操作比较类似数据表中定义数据表结构。
(2)统计每个name下的数量
参数格式
{
"aggs":{
"phone_count":{
"terms":{
"field":"name"//后面跟文档的属性
}
}
},
"size":0//如果不加这个会把检索的结果也返回
}
(3)统计名称中包含X并计算每个name下的数量
参数格式
{
"aggs":{
"phone_count":{
"terms":{
"field":"name"
}
}
},
"size":0,
"query":{
"match":{
"name":"X"
}
}
}
(4)统计商品的平均价格
参数格式
{
"aggs":{
"phone_avg":{
"avg":{
"field":"price"
}
}
},
"size":0
}
(5)检索某个范围内的商品数量
参数格式
{
"aggs":{
"phone_range":{
"range":{
"field":"price",
"ranges":{
"from":0,
"to":1000
}
}
}
}
}