一:枚举enumerate
定义:对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
代码:
li = ['alex','银角','女神','egon','太白']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1):
print(index,name)
for index, name in enumerate(li, 100): # 起始位置默认是0,可更改
print(index, name)
结果:
(0, 'alex')
(1, '银角')
(2, '女神')
(3, 'egon')
(4, '太白')
1 alex
2 银角
3 女神
4 egon
5 太白
100 alex
101 银角
102 女神
103 egon
104 太白
Process finished with exit code 0
二:range
定义:指定范围生成指定数字。
代码:
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
结果:
1
2
3
4
5
6
7
8
9
1
3
5
7
9
10
8
6
4
2
Process finished with exit code 0
三:id,is,==
3.1: id
定义:只要创建一个数据(对象)那么都会在内存中开辟一个空间,将这个数据临时加在到内存中,那么这个空间是有一个唯一标识的,就好比是身份证号,标识这个空间的叫做内存地址,也就是这个数据(对象)的id
3.2:is
定义:is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。
3.3:==
定义:== 是比较的两边的数值是否相等
四:代码块
定义:Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
4.1:代码块的缓存机制***
前提条件:在同一个代码块内
机制内容:Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
适用对象: int(float),str,bool。
五:小数据池***
定义:小数据池,不同代码块的缓存机制,也称为小整数缓存机制,或者称为驻留机制
前提条件:在不同一个代码块内。
不同代码块下的小数据池驻留机制 数字的范围只是-5~256.***
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
总结:
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
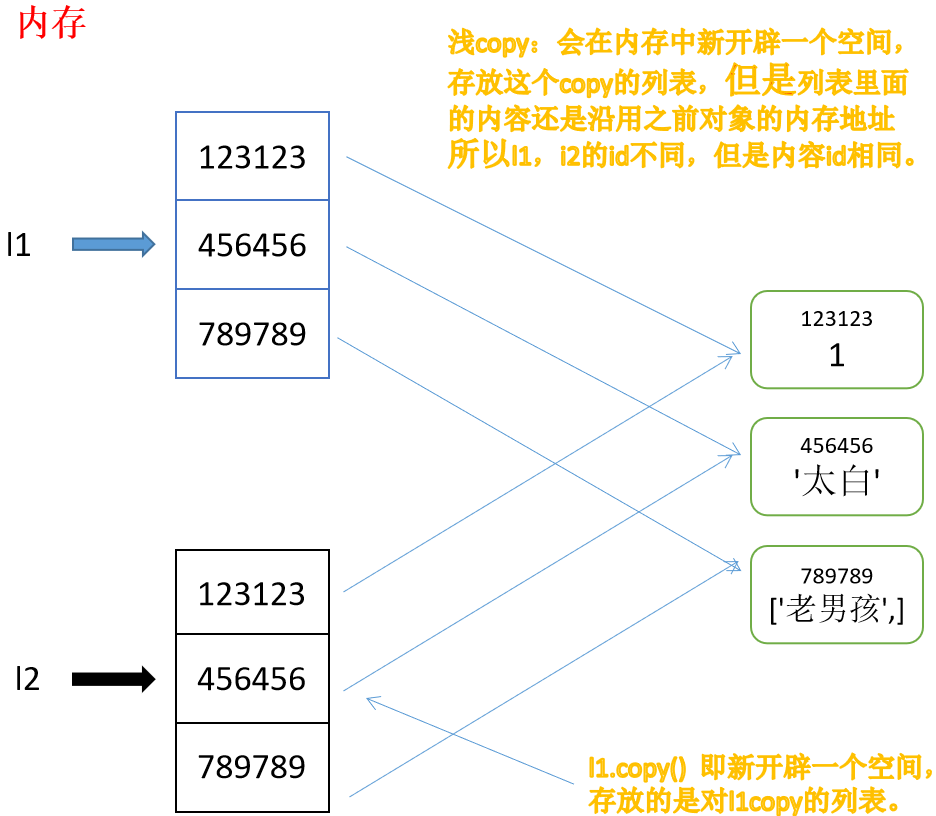
六:copy
深浅cope就是完全复制和部分复制的意思。
代码:
1 = [1,2,3,['barry','alex']]
l2 = l1
l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']]
浅拷贝代码:
同一代码块下:
l1 = [1, '太白', True, (1,2,3), [22, 33]]
l2 = l1.copy()
print(id(l1), id(l2)) # 2713214468360 2713214524680
print(id(l1[-2]), id(l2[-2])) # 2547618888008 2547618888008
print(id(l1[-1]),id(l2[-1])) # 2547620322952 2547620322952
不同代码块下:
>>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]]
>>> l2 = l1.copy()
>>> print(id(l1), id(l2))
1477183162120 1477183162696
>>> print(id(l1[-2]), id(l2[-2]))
1477181814032 1477181814032
>>> print(id(l1[-1]), id(l2[-1]))
1477183162504 1477183162504
注意:对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。
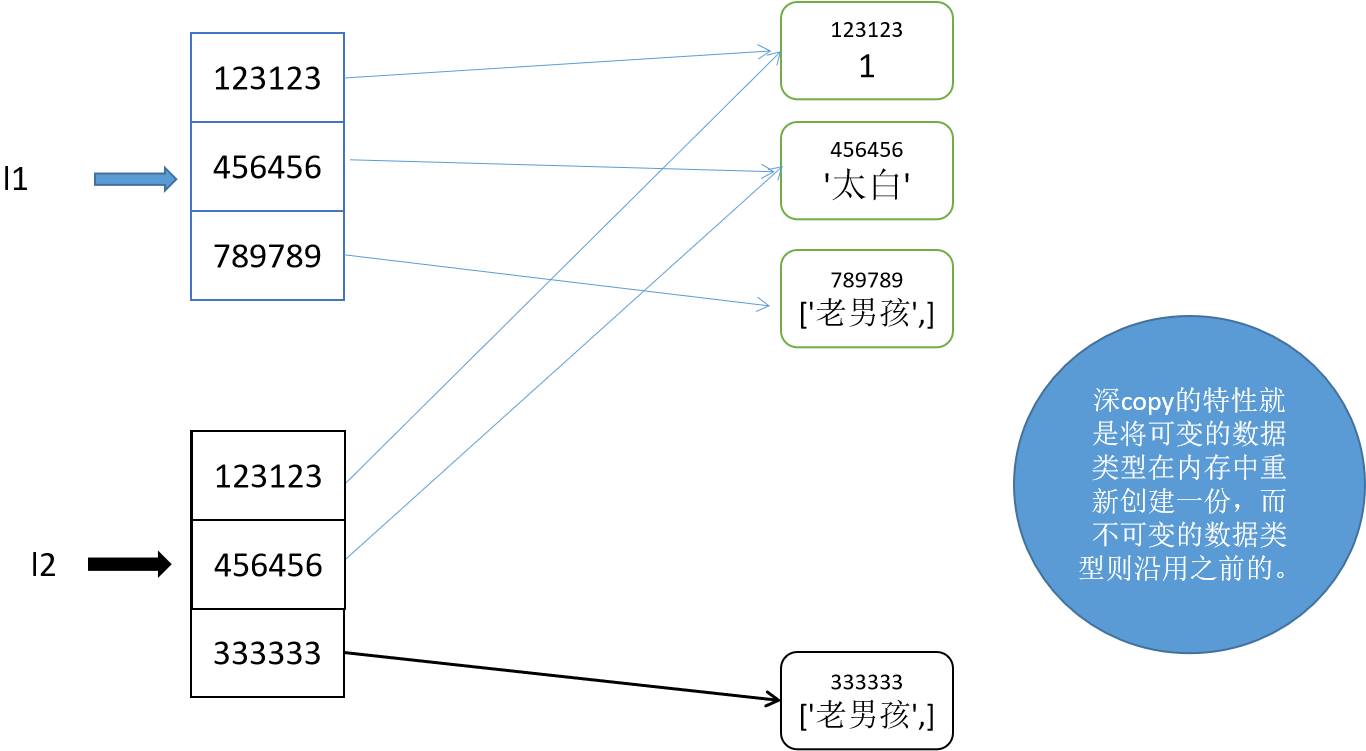
深拷贝代码:
# 同一代码块下
import copy
l1 = [1, 'alex', True, (1,2,3), [22, 33]]
l2 = copy.deepcopy(l1)
print(id(l1), id(l2)) # 2788324482440 2788324483016
print(id(l1[0]),id(l2[0])) # 1470562768 1470562768
print(id(l1[-1]),id(l2[-1])) # 2788324482632 2788324482696
print(id(l1[-2]),id(l2[-2])) # 2788323047752 2788323047752
# 不同代码块下
>>> import copy
>>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]]
>>> l2 = copy.deepcopy(l1)
>>> print(id(l1), id(l2))
1477183162824 1477183162632
>>> print(id(0), id(0))
1470562736 1470562736
>>> print(id(-2), id(-2))
1470562672 1470562672
>>> print(id(l1[-1]), id(l2[-1]))
1477183162120 1477183162312
注意:对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
习题:
l1=[1,2,3,4,['lxx']]
l2=l1[::]
print(l2)
l1[-1].append('khjgy')
print(l2)
结果:
[1, 2, 3, 4, ['lxx']]
[1, 2, 3, 4, ['lxx', 'khjgy']]
***深浅拷贝的区别:
深:import cope ...l2=cope(l1)
浅:直接 l2=cope(l1)