我希望能够从网页上, 比如气象局数据, 财经数据等等, 我看到官方提供的数据都比较混乱, 有的是一个php文件, 有的是一个文本, 有的干脆不提供数据, 我想问, Mac上, 用什么工具去抓数据, 以及处理这些数据大神们一般用很么方法?
1、http://Import.io
import.io用法非常简单,注册后输入网址链接,就可以在可视化界面对数据进行筛选。操作也是超级简单,如下图,唯一缺点就是全英文,不过咱们自己也有,来看看第二个吧。
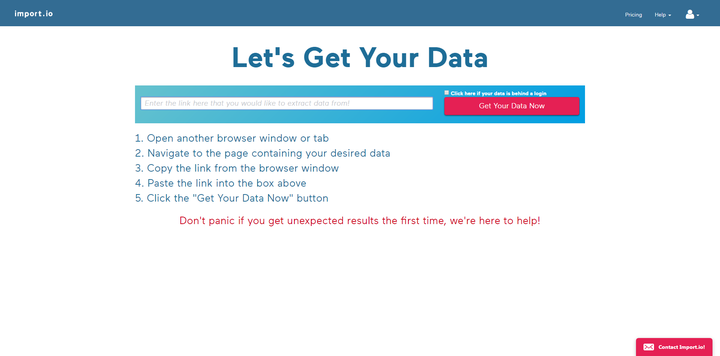
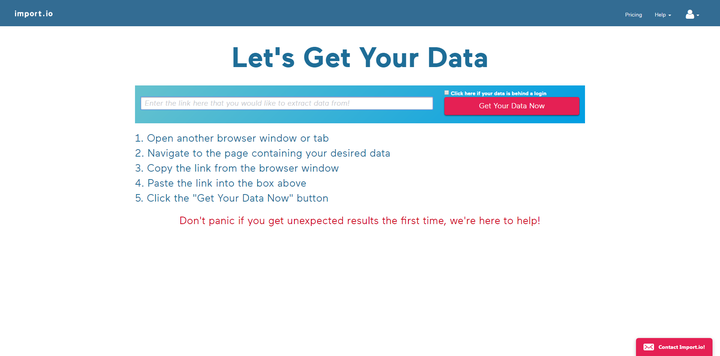
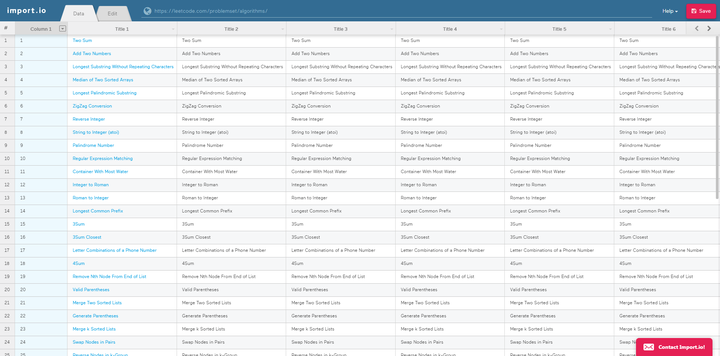
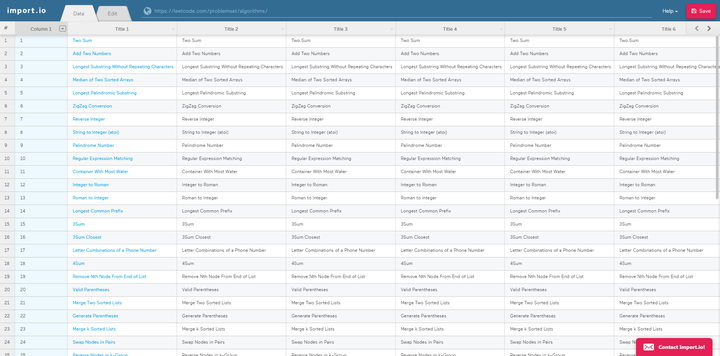
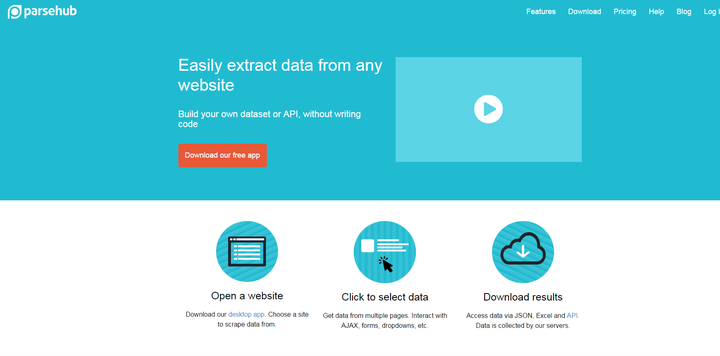
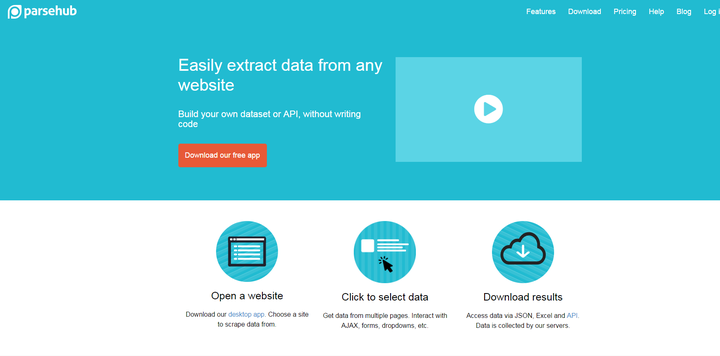
2、parsehub
parsehub与以上两种网页抓取不同的是,parsehub需要用户下载客户端之后再使用,打开就像一个浏览器,输入网址后在网页提取出需要的信息。
https://ma.taobao.com/ZTg4et (二维码自动识别)
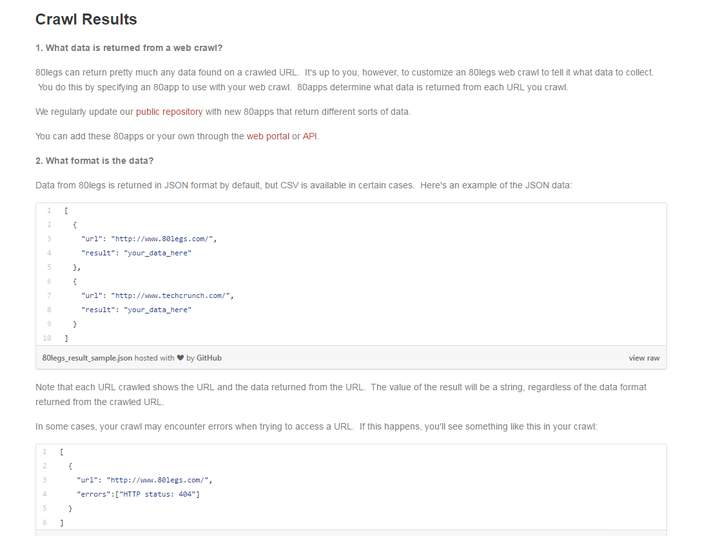
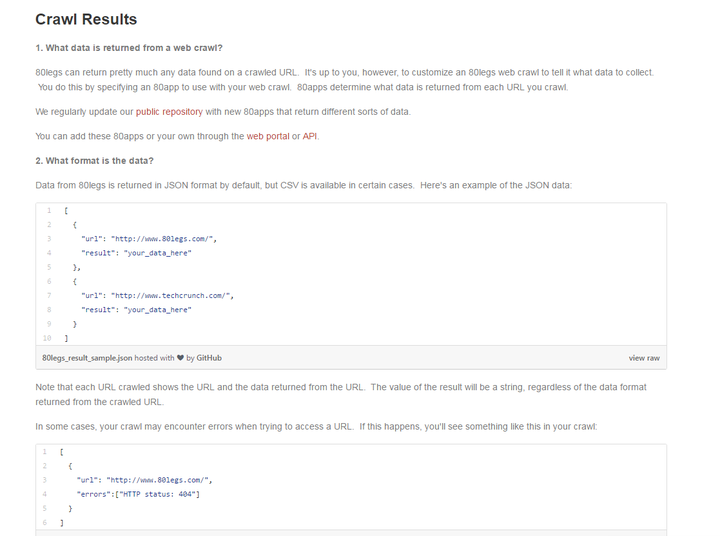
3、80legs
80legs80legs在由5万台计算机构成的Plura网格 上每天抓取200万网页。 但是在使用上可能并没有前几个那么好用。


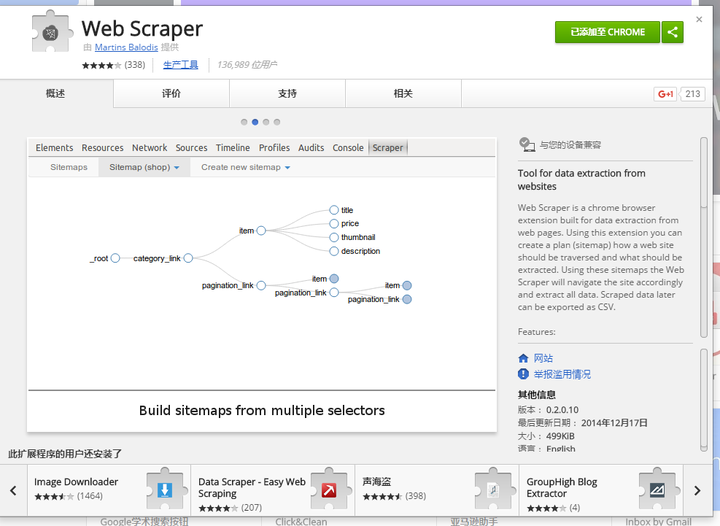
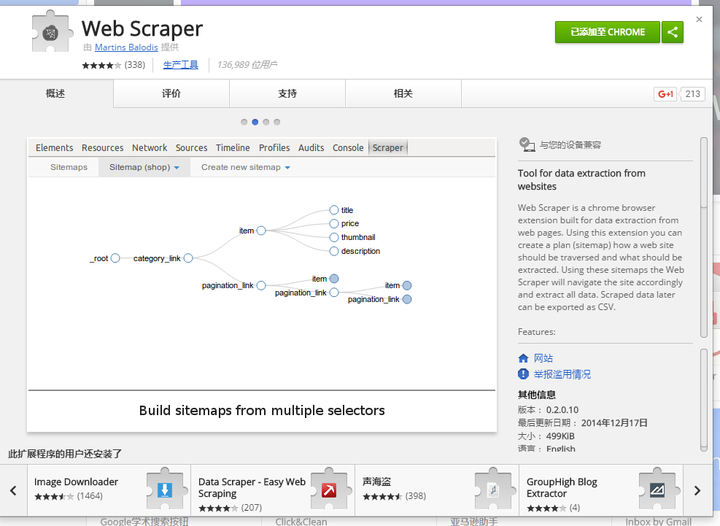
4、Web Scraper
Web ScraperWeb Scraper是需要在谷歌应用商店安装的一个插件,基本步骤就是点点点
详细的教程可以看这里http://www.w 2bc.com/article/241334
https://ma.taobao.com/ZTg4et (二维码自动识别)
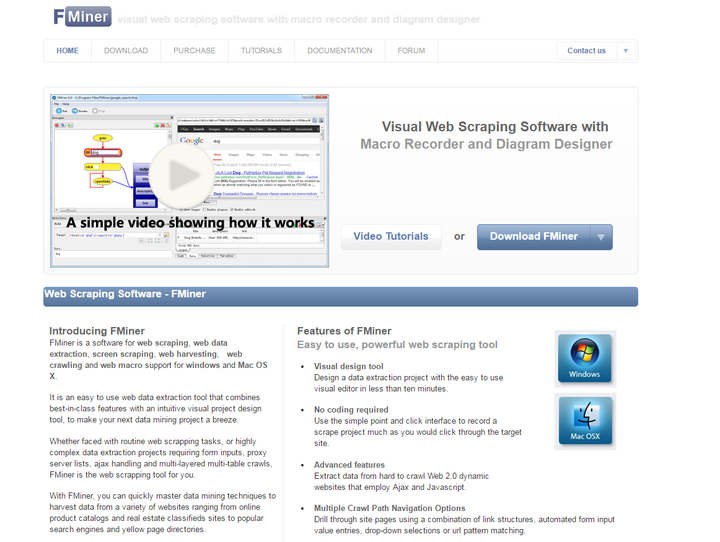
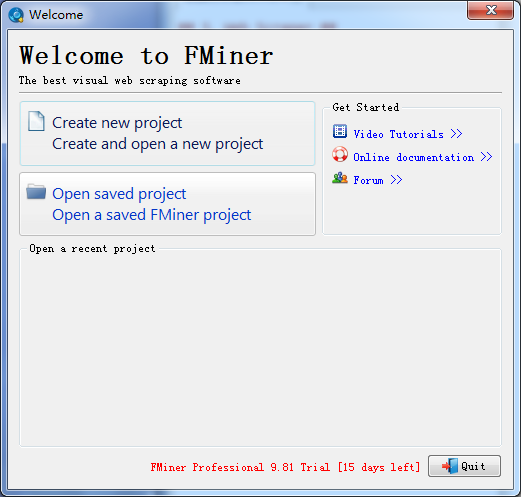
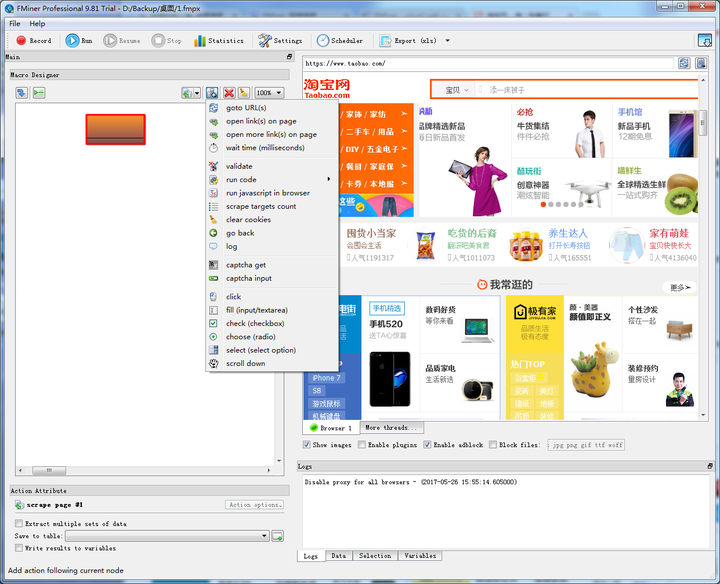
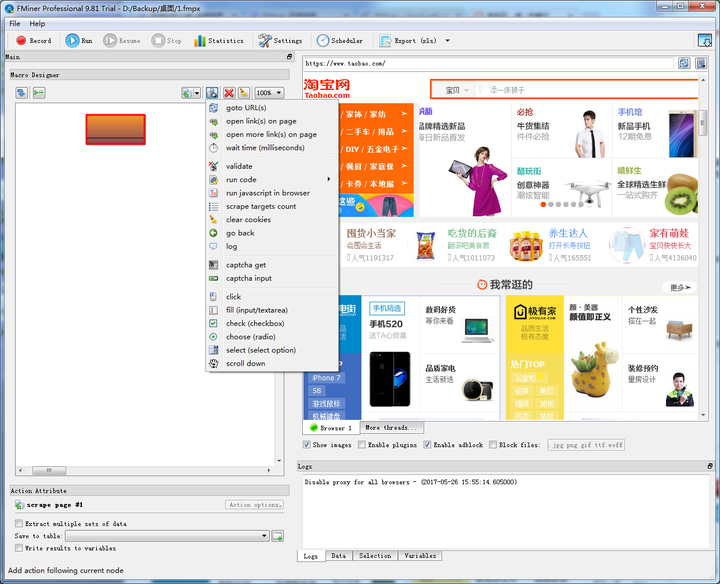
5、FMiner
FMinerFMiner同样也需要下载客户端进行使用,但它是一款付费产品,有15天的免费使用期。
总结
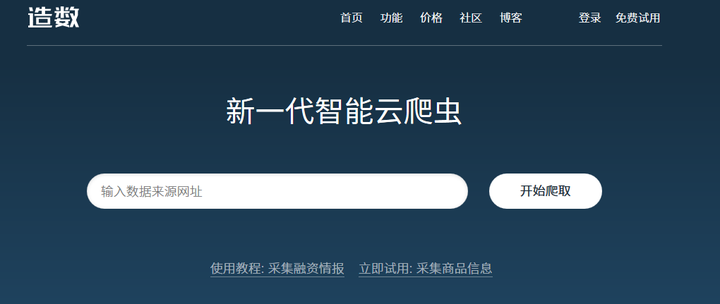
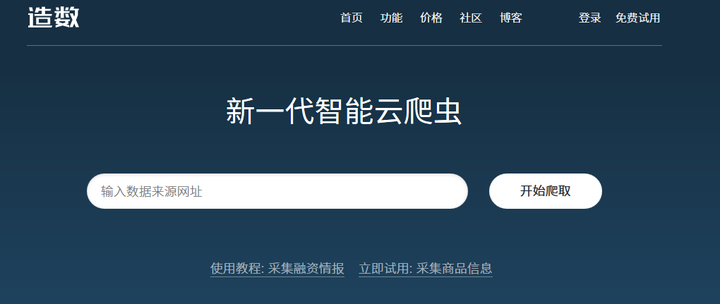
以上介绍的都是国外的工具,如果更喜欢中文界面,可以来试试我们的产品造数造数 -深受广大爬虫爱好者喜欢的云爬虫
造数比http://import.io更适合国人使用。直接在原网页基础上操作,还可以分布式爬取、深度爬取等,对数据有需求的可以尝试下。
其实网页爬取工具很多,大可不必全部掌握,把它当作工具来方便自己的工作才是本文的目标。
链接:https://www.zhihu.com/question/27736988/answer/497899625
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我在mac上用的是下图这个,日常基本数据的爬取足够了。
1)日常临时性的,或者快速的数据爬取,就用这个
2)其他的还是会写写python爬取,毕竟开发需要时间和成本,要考虑投入产出比
 应用信息
应用信息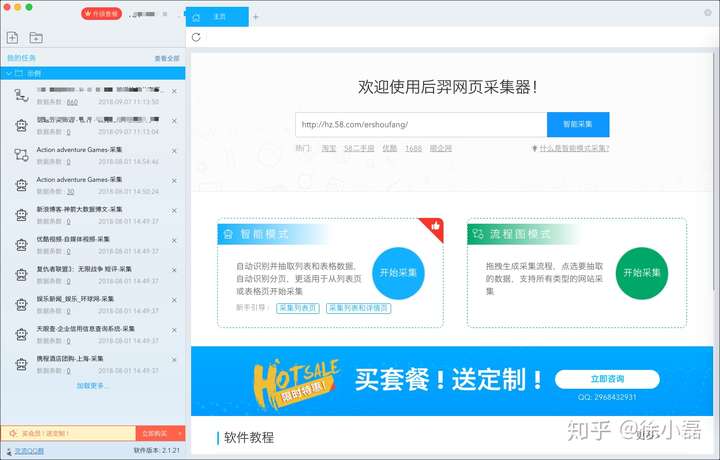 主界面,和八抓鱼差不多
主界面,和八抓鱼差不多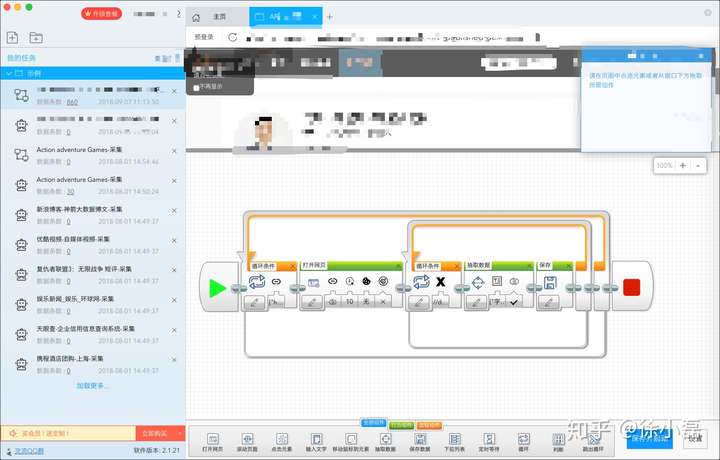 爬取规则页面,也和八抓鱼差不多,不过更好看和方便
爬取规则页面,也和八抓鱼差不多,不过更好看和方便