本论文是一篇介绍使用CNN对句子进行分类的论文。本文将介绍使用TensorFlow来实现整个论文的实验过程,一方面熟悉使用TensorFlow API,另一方面加深对CNN在NLP上的应用理解。
对于文本分类问题,常规方法就是抽取文本的特征,使用doc2evc或者LDA模型将文本转换成一个固定维度的特征向量,然后基于抽取的特征训练一个分类器。而TextCNN 是利用卷积神经网络对文本进行分类的算法,并且有着卓越的表现,下面是TextCNN的模型架构:
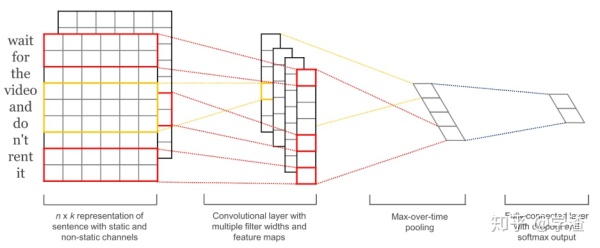
句子中每个word使用K维向量来表示,句子可表示为一个N*K的矩阵,作为CNN的输入。
TextCNN的结构比较简单,输入数据首先通过一个embedding layer,得到输入语句的embedding表示,然后通过一个convolution layer,提取语句的特征,最后通过一个fully connected layer得到最终的输出,整个模型的结构具体如下:
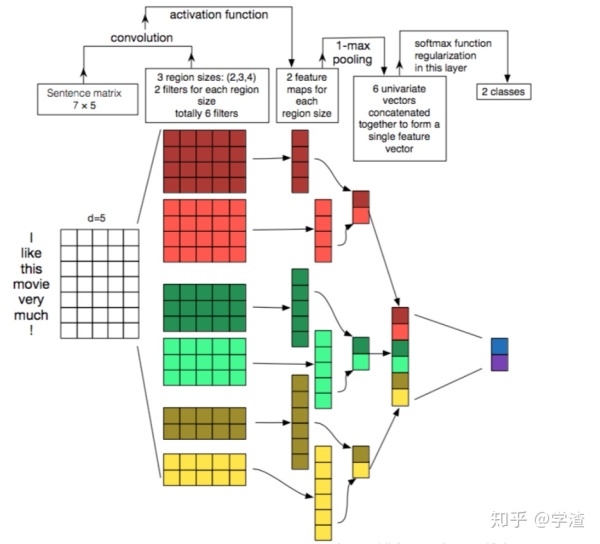
TextCNN结构
embedding layer:即嵌入层,这一层是将输入的自然语言编码成distributed representation,具体的实现方法可以使用word2vec。使用预训练好的词向量,也可以直接在训练textcnn的过程中训练出一套词向量(CNN-rand),不过前者比或者快100倍不止。如果使用预训练好的词向量,又分为static方法和no-static方法,前者是指在CNN训练过程中作为固定的输入,不作为优化的参数,后者在训练过程中调节词向量的参数,所以,后者的结果比前者要好。更为一般的做法是:不要在每一个batch中都调节emdbedding层,而是每个100个batch调节一次,这样可以减少训练的时间,又可以微调词向量。 对于没有出现在训练好的词向量表中的词(未登录词)的词向量,论文实验中采取的是使用随机初始化为0或者偏小的正数表示。
convolution layer:这一层主要是通过卷积,提取不同的n-gram特征。输入的语句或者文本,通过embedding layer后,会转变成一个二维矩阵,假设文本的长度为|T|,词向量的大小为|d|,则该二维矩阵的大小为|T|x|d|,接下的卷积工作就是对这一个|T|x|d|的二维矩阵进行的。卷积核的大小一般设定为
n是卷积核的长度,|d|是卷积核的宽度,这个宽度和词向量的维度是相同的,也就是卷积只是沿着文本序列进行的,n可以有多种选择,比如2、3、4、5等。对于一个|T|x|d|的文本,如果选择卷积核kernel的大小为2x|d|,则卷积后得到的结果是|T-2+1|x1的一个向量。在TextCNN网络中,需要同时使用多个不同类型的kernel,同时每个size的kernel又可以有多个。如果我们使用的kernel size大小为2、3、4、5x|d|,每个种类的size又有128个kernel,则卷积网络一共有4x128个卷积核。使用更多不同高度的卷积核,能够提取更丰富的特征表达。
max-pooling layer:最大池化层,对卷积后得到的若干个一维向量取最大值,然后拼接在一块,作为本层的输出值。如果卷积核的size=2,3,4,5,每个size有128个kernel,则经过卷积层后会得到4x128个一维的向量,再经过max-pooling之后,会得到4x128个scalar值,拼接在一块,得到最终的结构—512x1的向量。max-pooling层的意义在于对卷积提取的n-gram特征,提取激活程度最大的特征。
fully-connected layer:这一层的输入为池化操作后形成的一维向量,经过激活函数输出,再加上Dropout层防止过拟合。并在全连接层上添加l2正则化项。
softmax-layer: 最后接一层全连接的 softmax 层,输出每个类别的概率。
基于tensorflow的代码实现:
import numpy as np
import tensorflow as tf
class TextCNN(object):
"""
A CNN for text classification.
Use an embedding layer, followed by a convolution, max-pooling and softmax layer.
"""
__shuffer_falg = False
__static_falg = True
def __init__(self, W_list, shuffer_falg, static_falg, filter_numbers, filter_sizes, sentence_length, embedding_size,
learnrate, epochs, batch_size, dropout_pro):
self.__shuffer_falg = shuffer_falg
self.__static_falg = static_falg
self.learning_rate_item = learnrate
self.epochs = epochs
# max length of sentence
self.sentence_length = sentence_length
# number of filters
self.filter_numbers = filter_numbers
self.batch_size = batch_size
self.dropout_pro_item = dropout_pro
# length of word embedding
self.embedding_size = embedding_size
# setting graph
tf.reset_default_graph()
self.train_graph = tf.Graph()
with self.train_graph.as_default():
# 1 input layer
self.input_x = tf.placeholder(dtype=tf.int32, shape=[None, sentence_length], name='input_x')
self.input_y = tf.placeholder(dtype=tf.int32, shape=[None, 2], name='input_y')
self.dropout_pro = tf.placeholder(dtype=tf.float32, name='dropout_pro')
self.learning_rate = tf.placeholder(dtype=tf.float32, name='learning_rate')
self.l2_loss = tf.constant(0.0)
# self.embedding_layer = tf.placeholder(dtype=tf.float32,
# shape=[self.batch_size, sentence_length, embedding_size],
# name='embedding_layer')
# 2 embedding layer
with tf.name_scope('embedding_layer'):
train_bool = not self.__static_falg
# tf.convert_to_tensor(W_list,dtype=tf.float32)
self.embedding_layer_W = tf.Variable(initial_value=W_list,dtype=tf.float32, trainable=train_bool, name='embedding_layer_W')
# shape of embedding chars is (None, sentence_length, embedding_size)
self.embedding_layer_layer = tf.nn.embedding_lookup(self.embedding_layer_W, self.input_x)
# shape of embedding char expanded is (self.embedding_layer_layer, -1)
self.embedding_layer_expand = tf.expand_dims(self.embedding_layer_layer, -1)
# 3 conv layer + maxpool layer for each filer size
pool_layer_lst = []
for filter_size in filter_sizes:
max_pool_layer = self.__add_conv_layer(filter_size, filter_numbers)
pool_layer_lst.append(max_pool_layer)
# 4.full connect droput + softmax + l2
# combine all the max pool —— feature
with tf.name_scope('dropout_layer'):
max_num = len(filter_sizes)*self.filter_numbers
h_pool = tf.concat(pool_layer_lst, name='last_pool_layer', axis=3)
pool_layer_flat = tf.reshape(h_pool, [-1, max_num], name='pool_layer_flat')
dropout_pro_layer = tf.nn.dropout(pool_layer_flat, self.dropout_pro, name='dropout')
with tf.name_scope('soft_max_layer'):
SoftMax_W = tf.Variable(tf.truncated_normal([max_num, 2], stddev=0.01), name='softmax_linear_weight')
self.__variable_summeries(SoftMax_W)
SoftMax_b = tf.Variable(tf.constant(0.1, shape=[2]), name='softmax_linear_bias')
self.__variable_summeries(SoftMax_b)
self.l2_loss += tf.nn.l2_loss(SoftMax_W)
self.l2_loss += tf.nn.l2_loss(SoftMax_b)
# dropout_pro_layer_reshape = tf.reshape(dropout_pro_layer,[batch_size,-1])
self.softmax_values = tf.nn.xw_plus_b(dropout_pro_layer, SoftMax_W, SoftMax_b, name='soft_values')
self.predictions = tf.argmax(self.softmax_values, axis=1, name='predictions', output_type=tf.int32)
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.softmax_values, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + 0.001 * self.l2_loss # lambda = 0.001
tf.summary.scalar('last_loss', self.loss)
with tf.name_scope('accuracy'):
correct_acc = tf.equal(self.predictions, tf.argmax(self.input_y,axis=1,output_type=tf.int32))
self.accuracy = tf.reduce_mean(tf.cast(correct_acc, 'float'), name='accuracy')
tf.summary.scalar('accuracy', self.accuracy)
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
self.train_op = optimizer.minimize(self.loss)
self.session = tf.InteractiveSession(graph=self.train_graph)
self.merged = tf.summary.merge_all()
self.train_writer = tf.summary.FileWriter('./NLP/log/text_cnn', graph=self.train_graph)
def train(self, train_x, train_y):
self.session.run(tf.global_variables_initializer())
for epoch in range(self.epochs):
train_batch = self.__get_batchs(train_x, train_y, self.batch_size)
train_loss, train_acc, count = 0.0, 0.0, 0.0
for batch_i in range(len(train_x) // self.batch_size):
x, y = next(train_batch)
feed = {
self.input_x: x,
self.input_y: y,
self.dropout_pro: self.dropout_pro_item,
self.learning_rate: self.learning_rate_item
}
_, summarys, loss, accuracy = self.session.run([self.train_op, self.merged, self.loss, self.accuracy],
feed_dict=feed)
train_loss, train_acc, count = train_loss + loss, train_acc + accuracy, count + 1
self.train_writer.add_summary(summarys, epoch)
# each 5 batch print log
if (batch_i + 1) % 15 == 0:
print('Epoch {:>3} Batch {:>4}/{} train_loss = {:.3f} accuracy = {:.3f}'.
format(epoch, batch_i, (len(train_x) // self.batch_size), train_loss / float(count),
train_acc / float(count)))
def validation(self, test_x, test_y):
test_batch = self.__get_batchs(test_x, test_y, self.batch_size)
eval_loss, eval_acc, count = 0.0, 0.0, 0.0
for batch_i in range(len(test_x)//self.batch_size):
x, y = next(test_batch)
feed = {
self.embedding_layer: x,
self.input_y: y,
self.dropout_pro: self.dropout_pro_item,
self.learning_rate: 1.0
}
loss, accuracy = self.session.run([self.loss, self.accuracy], feed_dict=feed)
eval_loss, eval_acc, count = eval_loss + loss, eval_acc + accuracy, count + 1
return eval_acc / float(count), eval_loss / float(count)
def close(self):
self.session.close()
self.train_writer.close()
def __get_batchs(self, Xs, Ys, batch_size):
for start in range(0, len(Xs), batch_size):
end = min(start + batch_size, len(Xs))
yield Xs[start:end], Ys[start:end]
pass
def __add_conv_layer(self, filter_size, filter_num):
with tf.name_scope('conv-maxpool-size%d' % (filter_size)):
# convolutio layer
filter_shape = [filter_size, self.embedding_size, 1, filter_num]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name='filter_weight')
self.__variable_summeries(W)
b = tf.Variable(tf.constant(0.1, shape=[filter_num]), name='filter_bias')
self.__variable_summeries(b)
conv_layer = tf.nn.conv2d(self.embedding_layer_expand, W, strides=[1, 1, 1, 1], padding='VALID',
name='conv_layer')
relu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer, b), name='relu_layer')
max_pool_layer = tf.nn.max_pool(relu_layer, ksize=[1, self.sentence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1], padding='VALID', name='maxpool')
return max_pool_layer
def __variable_summeries(self, var):
"""
:param var: Tensor, Attach a lot of summaries to a Tensor (for TensorBoard visualization).
"""
with tf.name_scope('summeries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean) # 记录参数的均值
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)