本节主要介绍文本分类中的一种算法即向量空间模型,这个算法很经典,包含文本预处理、特征选择、特征权值计算、分类算法、这是VSM的几个主要步骤,在宗老师的书里都有详细的讲解,这里也会进行深入的讲解,浅显易懂的是目的,深入理解是目标,下面给出这个VSM模型的方框流程图:
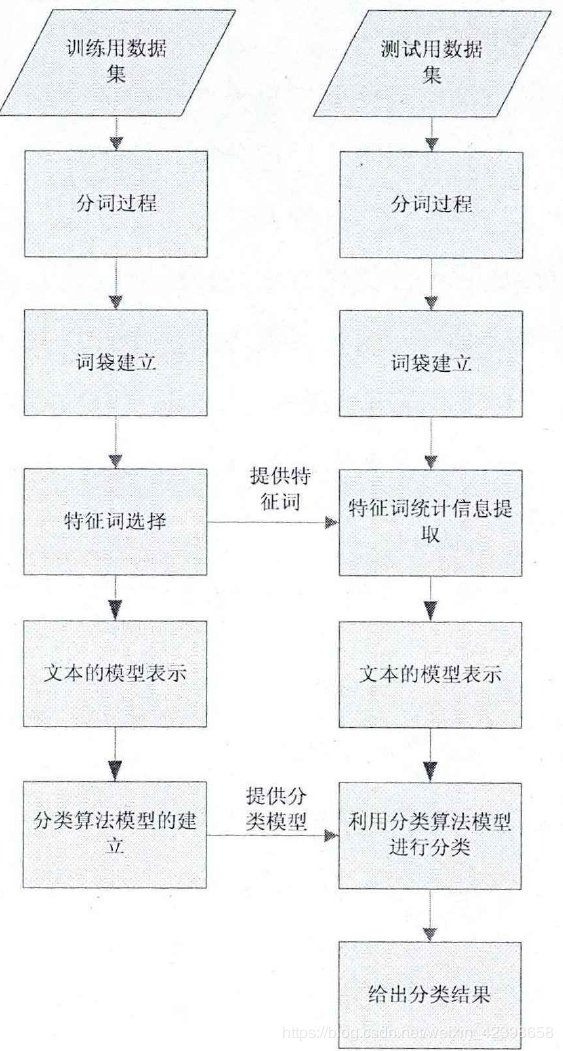
其中分词和词袋的建立我们在前两节进行解释了,这一节将主要介绍特征词选择、文本模型表示(VSM),分类算法的建立。下面就系统的进行梳理VSM的算法过程,这里大家多参考宗老师的书效果会更好:
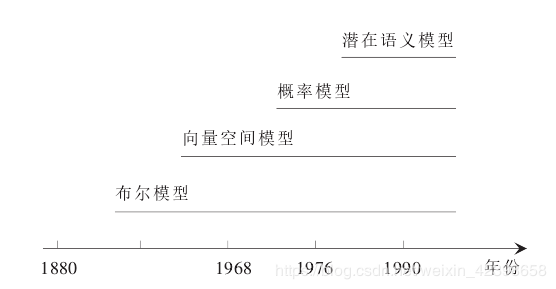
文本分类就是在给定的分类模型下, 由计算机根据文本内容自动判别文本类别的过程。 随着文本分类技术的发展, 不同的文本表示模型逐渐出现多种文本分类算法, 使得文本挖掘领域道路越来越宽。 目前已经出现多种中文文本表示方法,如布尔模型、向量空间模型、潜在语义模型和概率模型等。 所以在构造自动文本分类器时, 面临的选择也越来越多。 空间向量模型是一种出现较早的文本表示模型, 但现在仍然在广泛的使用。 本篇的重点是对已经出现的基于向量空间模型的文本分类算法进行研究分析。
文本分类的定义
Sebastiani(2002)以如下数学模型描述文本分类任务。文本分类的任务可以理解为获得这样的一个函数:
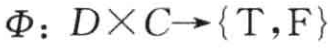
其中,![]() 表示需要进行分类的文档,
表示需要进行分类的文档,![]() 表示预定义的分类体系下的类别集合。T值表示对于
表示预定义的分类体系下的类别集合。T值表示对于![]() 来说,文档属于类,而F值表示对于
来说,文档属于类,而F值表示对于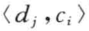 而言文档不属于类。也就是说,文本分类任务的最终目的是要找到一个有效的映射函数,准确地实现域D×C到值T或F的映射,这个映射函数实际上就是我们通常所说的分类器。因此,文本分类中有两个关键问题:一个是文本的表示,另一个就是分类器设计。
而言文档不属于类。也就是说,文本分类任务的最终目的是要找到一个有效的映射函数,准确地实现域D×C到值T或F的映射,这个映射函数实际上就是我们通常所说的分类器。因此,文本分类中有两个关键问题:一个是文本的表示,另一个就是分类器设计。
一个文本分类系统可以简略地用下图所示:

文本表示
中文文本信息多数是无结构化的, 并且使用自然语言,很难被计算机处理。 因此,如何准确地表示中文文本是影响文本分类性能的主要因素。 经过多年发展,如下图所示,研究人员提出了布尔模型、向量空间模型、潜在语义模型和概率模型等文本表示模型,用某种特定结构去表达文本的语义。基于分类速度的考虑, 目前的文本分类挖掘系统主要采用向量空间模型来表示文本
。VSM由哈佛大学的 G Salton 提出,这一模型将给定的文本转换成一个维数很高的向量, 并以特征项作为文本表示的基本单位
, 向量的各维对应文本中的一个特征项, 而每一维本身则表示了其对应的特征项在该文本中的权值。 权值代表了特征项对于所在文本的重要程度, 即该特征项能够多大程度上反映它所在文档的类别。
下面给出VSM的概念和相关的定义,主要参考了宗老师的书,因为我查了很多资料,感觉还是宗老师说的比较简单明了,大家也看看,算法难点我会详细的讲解的,下面开始:
目前文本表示通常采用向量空间模型(vector space model,VSM)。VSM是20世纪60年代末期由G.Salton等人提出的[Salton,1971],最早用在SMART信息检索系统中,目前已经成为自然语言处理中常用的模型。下面首先给出VSM涉及的一些基本概念。
文档(document):通常是文章中具有一定规模的片段,如句子、句群、段落、段落组直至整篇文章。本书对文本(text)和文档不加区分。
项/特征项(term/feature term):特征项是VSM中最小的不可分的语言单元,可以是字、词、词组或短语等。一个文档的内容被看成是它含有的特征项所组成的集合,表示为: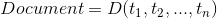 ,其中
,其中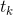 是特征项,
是特征项,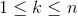 。
。
项的权重(term weight):对于含有n个特征项的文档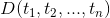 ,每一特征项都依据一定的原则被赋予一个权重
,每一特征项都依据一定的原则被赋予一个权重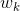 ,表示它们在文档中的重要程度。这样一个文档D可用它含有的特征项及其特征项所对应的权重所表示:
,表示它们在文档中的重要程度。这样一个文档D可用它含有的特征项及其特征项所对应的权重所表示: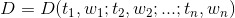 ,简记为
,简记为 ,其中
,其中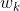 就是特征项
就是特征项 的权重,
的权重, 。
。
一个文档在上述约定下可以看成是视维空间中的一个向量,这就是向量空间模型的由来。下面给出其定义。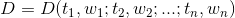
定义: (向量空间模型(VSM)) 给定一个文档,D符合以下两条约定:
(1)各个特征项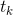 (
( )互异(既没有重复);
)互异(既没有重复);
(2)各个特征项无先后顺序关系(即不考虑文档的内部结构)
在以上两个约定下,可以把特征项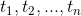 看成一个n维坐标系,而权重
看成一个n维坐标系,而权重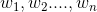 为相应的坐标值,因此,一 个 文本就表示为维空间中的一个向量,我们称
为相应的坐标值,因此,一 个 文本就表示为维空间中的一个向量,我们称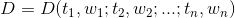 为文本D的向量或向量空间模型,如下图所示:
为文本D的向量或向量空间模型,如下图所示:
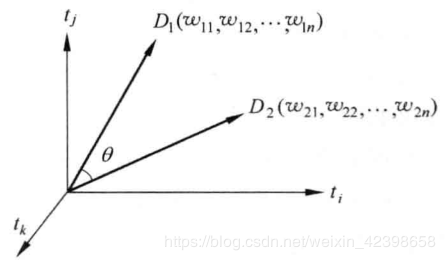
向量的相似性度量
定义: 任意两个文档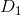 和
和 之间的相似性系数
之间的相似性系数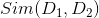 指两个文档内容的相关程度(degree of relevance)。设文档
指两个文档内容的相关程度(degree of relevance)。设文档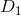 和
和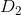 表示
表示
VSM中的两个向量: ![]()
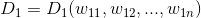
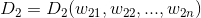
那么,可以借助于n维空间中两个向量之间的某种距离来表示文档之间的相似度,常用的方法是使用向量之间的內积来计算:
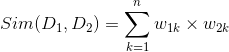
考虑到向量的归一化,则可以使用两个向量的余弦值来表示相似系数:
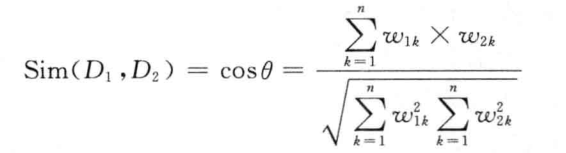
这里需要解释一下,我们知道在平面向量里两个向量越接近,那么这两个向量的夹角越小,直到这两个向量平行这两个向量才完全相等,大家需要理解一下基本的向量知识就懂了,上式是根据求向量的夹角进行判断,如下:
设二维空间内有两个向量 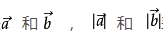 表示向量a和b的大小,它们的夹角为
表示向量a和b的大小,它们的夹角为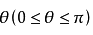 ,则内积定义为以下实数: 、
,则内积定义为以下实数: 、 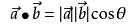

则 夹角的计算 
这样大家应该可以理解吧,我们继续:
采用向量空间模型进行文本表示时,需要经过以下两个主要步骤:
(1)根据训练样本集生成文本表示所需要的特征项序列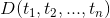 ;
;
(2)依据文本特征项序列,对训练文本集和测试样本集中的各个文档进行权重赋值、规范化等处理,将其转化为机器学习算
法所需的特征向量。
另外,用向量空间模型表示文档时,首先要对各个文档进行词汇化处理,在英文、法文等西方语言中这项工作相对简单,但在汉语中主要取决于汉语自动分词技术。由于n元语法具有语言无关性的显著优点,而且对于汉语来说可以简化分词处理,因此,有些学者提出了将n元语法用于文本分类的实现方法,利用n元语法表示文本单元(“词”)。
需要指出的是,除了VSM文本表示方法以外,研究比较多的还有另外一些表示方法,例如:词组表示法,概念表示法等。但这些方法对文本分类效果的提高并不十分显著。词组表示法的表示能力并不明显优于普通的向量空间模型,原因可能在于,词组虽然提高了特征向量的语义含量,但却降低了特征向量的统计质量,使得特征向量变得更加稀疏,让机器学习算法难以从中提取用于分类的统计特性。