本文内容:
一、XML语言概述
1.1 XML和HTML的区别
1.2 XML的常用场景
二、XML文件的基本语法知识(如何编写一个XML文件)
三、如何使用CSS或者XSL来控制XML文件的显示样式
四、如何解析一个XML文件(java中直接提供的两种XML文档解析方式)
4.1概述
4.2DOM法解析*.xml
4.3SAX法解析*.xml
4.4xml文件两种解析方法的比较(DOM和SAX的比较)
五、对用于XML文件解析(读取、写/修改)的Java API的进一步封装(用于xml文件解析的三方组件,需要手动导入相应jar包才可以使用其提供的API)
5.1概述
5.2 JDOM(由Jason Hunter和Brett Mclaughlin联合发布)
5.3 DOM4J(由SourceForge发布)
一、XML语言概述:
1.1 XML和HTML的区别
-

-
HTML和XML都是由SGML发展而来的,但是两者又有很多的不同之处。其中最大的不同便是:
-
HTML中的元素都是固定的,且以显示为主
- XML中的元素不是固定的,都是程序员自定义的,主要以数据保存为主
-
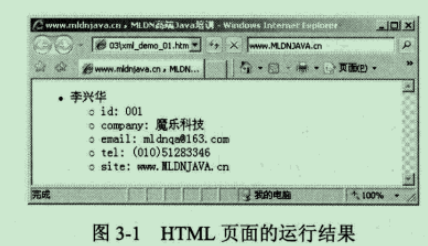
- 实例:由下面的例子可以看出,HTML中的标签都是固定的,是由HTML标准定义好的,每种标签怎么写,拥有什么含义都是HTML标准中已经定义好的,要想编写出一个能够运行的HTML文件就必须按照HTML规则来使用相应的标签,并且按照HTML语法要求来写。而XML中的元素(标签)则是由程序员来根据实际需求自定义的,XML中的标签的标识符怎么写,各个标签代表什么意思,完全都是由程序员来定义的。
-


-

-
上述例子中HTML页面中的<html> <head> <title> <body> <ul> <li> 等标签都是HTML标准中已经定义好的,HTML文件中程序员只能使用这些标签,不能使用其他标签
-
上述例子中XML文件的<addresslist> <linkman> <name> <id> <company> <email> <tel> <site> 都是程序员自己定义的,程序员还可以在该XML文件中添加更多的自定义标签
-
XML文件中除了含有自定义标签之外,还必须含有一个文件头来表示这个文件是XML文件,这个文件头是必不可少的,如下:
<?xml version="1.0" encoding="utf-8" standalone=“”?> <自定义标签1> ....其他自定义标签... </自定义标签1>
这个文件头规定了该XML页面的一些属性:如version规定了当前xml版本,encoding规定了该xml页面使用的编码方式,standalone表示该xml文件是否是独立显示的(XML文件可以结合CSS或者XSL来控制xml文件的显示样式)
1.2 XML的常用场景
-
- 数据交换
- 系统配置
- 内容管理
二、XML文件语法知识(编写第一个xml文件)
- 首先,所有的XML文件都必须含有文件头(即前导区)和数据区,前导区用于定义该XML文件的一些属性,数据区即为该XML文件的有效内容
- 前导区:
-
<?xml version="1.0" encoding="utf-8" standalone=“”?>
-
这个文件头规定了该XML页面的一些属性:如version规定了当前xml版本,encoding规定了该xml页面使用的编码方式,standalone表示该xml文件是否是独立显示的(XML文件可以结合CSS或者XSL来控制xml文件的显示样式)
- 前导区的三个属性必须按照version encoding standalone的顺序来写,否则该XML编译时会出错
-
- 数据区:
- 数据区就是开发人员自定义的一些标签了,他们的标识符、含义都是由开发者自行定义的
- 所有的数据区必须有一个根元素,一个根元素下可以存放多个子元素,且要求每一个元素必须完结(即</**>)
- XML中的每一个标记都是区分大小写的
- 自定义标签也可以拥有属性,但是属性的值必须用“”括起来。如果一个自定义标签有多个自定义属性,则属性之间用空格隔开
- 什么时候用自定义标签,什么时候用自定义属性?(答:一般不建议使用自定义属性。因为如果该xml文件需要结合CSS或XSL来显示的话,XML文件的标签属性的值是无法显示的。)
- 数据区的自定义标签要赋值,赋值时有一些特殊符号必须使用转义字符来表示:

-
XML文件内部注释:使用CDATA添加注释。
-
当XML解析器处理到CDATA标识符处时,就知道这一块实际上只是注释,所以解析器不会解析CDATA内部所包含的内容。
-
语法:<![CDATA[注释(该部分内容不会被XML解析器解析)]]>
-
-
如上所述,XML数据区的标签是可以由开发者自由定义的,如果要对一个XML文件中经常出现的元素或属性进行严格的定义,则需要使用DTD和Schema技术。
-
如,Spring的配置文件*.xml中,<bean>标签专门用于定义bean,至于它的bean标签就是根据DTD技术定义的。
-
- xml文件实例:
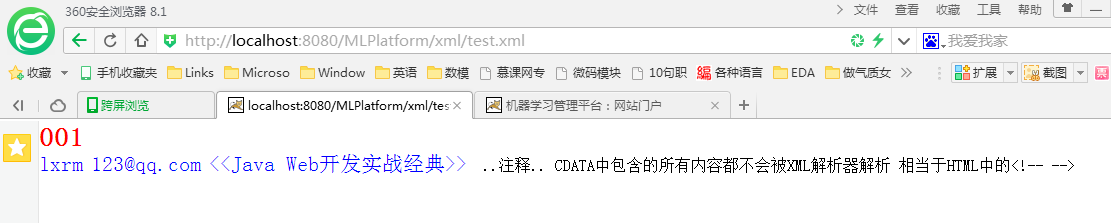
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <?xml-stylesheet type="text/css" href="../css/test.css"?> <linklist> <id>001</id> <name chinese="yes">lxrm</name> <email>123@qq.com</email> <textbook><<Java Web开发实战经典>></textbook> <![CDATA[ ..注释.. CDATA中包含的所有内容都不会被XML解析器解析 相当于HTML中的<!-- --> ]]> </linklist>

三、通过CSS或者XSL来控制XML文件内容的显示样式
概述:如果xml文件前导区定义的standalone=“yes”,那么该XML文件运行后显示结果就如本文第二部分展示的那样,只是将数据区的内容以树的形式展示出来。
如果将xml绑定了其他CSS文件或者XSL文件,则该XML文件中的内容就可以按照CSS或XSL中定义的格式来显示。
实例:

-
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/css" href="../css/test.css"?> <linklist> <id>001</id> <name chinese="yes">lxrm</name> <email>123@qq.com</email> </linklist>

@CHARSET "UTF-8"; id{ display:block; color:red; font-weight:bold; font-size:20pt; } name,email{ dispaly:block; color:blue; font-weight:normal; font-size:16pt; }
四、XML文件的解析
4.1 概述:
-
- XML文件有多种解析方式,如DOM解析、SAX解析法

4.2 DOM解析*.xml文件
| 基于DOM解析的XML分析器 | |
| *.xml——>DOM树 | |
| 优点:支持随机访问,即支持应用程序在任何时候随机访问XML文档的任何一部分内容 | |
|
缺点:
|
|
 
|
|
|
基于DOM的XML文件解析器,所提供的DOM接口:
|
|
|
1. 读取*.xml文件:(编程思路)
2.写*.xml文件:(编程思路)
|
|
|
在应用程序中使用基于DOM的XML文件解析器解析*.xml文件,并且调用该XML文件解析器提供的DOM接口获取xml文件的内容,并做出后续操作:
|






4.3 SAX法解析*.xml文件
| SAX法解析*.xml文件 |
|
原理:
|
|
优点: 对内存的需求不会随着*.xml文件的大小而改变,也就是说,即使*.xml文件很大,SAX解析法依然可以使用,因为SAX解析法对内存的需求不大 |
|
缺点:
|
|
SAX法构造*.xml文件解析器:(编程思路)
|
|
示例一:使用SAX解析方法解析d:/testDOM.xml文件(读取该文件内容,并且将他们在后台输出)
|




4.4 DOM解析法和SAX解析法的比较
| 基于DOM解析的XML分析器 | 基于SAX解析法的xml文件解析器 | |
| 原理:将整个xml文件转化成一个DOM树,并且放到内存中 |
原理:
|
|
|
优点: 支持随机访问,即支持应用程序在任何时候随机访问XML文档的任何一部分内容 |
优点: 对内存的需求不会随着*.xml文件的大小而改变,也就是说,即使*.xml文件很大,SAX解析法依然可以使用,因为SAX解析法对内存的需求不大 |
|
|
缺点:
|
|
|
DOM法解析*.xml,编程实现: 1.读取*.xml文件
2.java程序中修改*.xml文件(或者新建一个*.xml文件)
|
SAX法解析*.xml文件,编程实现:
|
|
|
DOM解析法的适用场景:
|
SAX解析法的适用场景:
|
五、对用于XML文件解析(读取、写/修改)的Java API的进一步封装
5.1 概述
- XML语法是由W3C提供的
- W3C除了提供XML语法的标准化文档之外,还提供了用于XML文档解析的java API(包括DOM解析相关API和SAX解析相关API)
- 但是上述两种XML文件的解析方法都有各自的缺点,所以其他一些组织就开始思考有没有更加好的方法可以集成两种解析方法的优点,同时又能避免他们各自的缺点
- 经过漫长的探索,产生了JDOM和
5.2 JDOM(一种专门用于XML文件解析的Java组件)
5.2.1概述
-
- JDOM(由Jason Hunter和Brett Mclaughlin联合发布),是开源的
- 可以在http://www.jdom.org/上下载相应的JDOM包(即用于XML文件解析的java API)
- JDOM是对DOM解析和SAX解析的改良,同时拥有两种解析方法的优点
- JDOM是专门为java application设计的,为在java应用中的xml操作过程提供了一种更低消耗的方法
- JDOM的主要操作类:

5.2.2使用JDOM组件操作XML文件(即XML文件解析操作)
-
- 涉及到的java API
-
import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.JDOMException; import org.jdom2.input.SAXBuilder;
import org.jdom2.Attribute; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.output.XMLOutputter;
-
- 编程思路:
- 首先从http://www.jdom.org/下载JDOM相应开发包,并且将其集成至自己的project中
- 具体导入过程参见如下博客:如何在eclipse中导入jdom组件的开发包(即java API)
- 其次针对项目实际需求使用JDOM组件提供的相应java API编写程序实现相应操作
- 实例1,xml文件的读取
- 涉及到的类:
-
import java.io.File; import java.io.IOException; import java.util.List; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.JDOMException; import org.jdom2.input.SAXBuilder;
-
- 编程思路:
-
/** * step1,创建SAXBuilder,并且使用该对象创建DOM树 * step2,通过前面创建的*.xml对应的DOM树访问树中的元素 * */
-
- 涉及到的类:
- 实例2,修改已有xml文件(或者新建一个xml文件)
- 涉及到的类:
import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import org.jdom2.Attribute; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.output.XMLOutputter;
-
编程思路:
-
/**step1,创建待写入到*.xml中的元素(标签、属性、标签内容) * step2,创建DOM树并且向该DOM树中添加子节点 * step3,将上面创建的DOM树写入到*.xml中 * */
-
- 涉及到的类:
- 实例1,xml文件的读取
- 首先从http://www.jdom.org/下载JDOM相应开发包,并且将其集成至自己的project中
- 示例:
- 示例一,使用JDOM组件提供的java API生成一个xml文件,使得该文件包含以下内容
-
- 编程实现:

/** *@author lxrm *@date 2017年4月10日 *@description:*/ package xml.operation; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import org.jdom2.Attribute; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.output.XMLOutputter; public class JDOM_Exam1_WriteXMLFile { public static void main(String[] args){ /**step1,创建待写入到*.xml中的元素(标签、属性、标签内容) * */ //定义节点(标签),并为标签赋值 Element addresslist=new Element("addresslist"); Element linkman=new Element("linkman"); Element name=new Element("name"); name.setText("lxrm"); //定义节点属性,并将属性绑定到节点(标签) Attribute id=new Attribute("id","001"); name.setAttribute(id); Element email=new Element("email"); email.setText("123@qq.com"); /** * step2,创建DOM树并且向该DOM树中添加子节点*/ //创建DOM树 Document dom=new Document(addresslist);//创建DOM树(即Document对象),并以addresslist为根节点 //为该DOM树添加子节点 addresslist.addContent(linkman); linkman.addContent(name); linkman.addContent(email); /** * step3,将上面创建的DOM树写入到*.xml中*/ XMLOutputter outputter = new XMLOutputter(); outputter.setFormat(outputter.getFormat().setEncoding("GBK")); String path="D:"+File.separator+"test.xml"; try { outputter.output(dom, new FileOutputStream(path)); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
-
程序运行结果:
-
生成了一个D:/test.xml文件(如果该文件已经存在,则用新生成的文件替换原有文件)
-
-
- 示例二,读取*.xml文件中的内容
- 待读取的*.xml文件
<?xml version="1.0" encoding="GBK"?> <addresslist> <linkman><name id="001">lxrm</name><email>123@qq.com</email></linkman> <linkman><name id="002">lx</name><email>123@qq.com</email></linkman> </addresslist>
- 编程实现:
/** *@author lxrm *@date 2017年4月10日 *@description:*/ package xml.operation; import java.io.File; import java.io.IOException; import java.util.List; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.JDOMException; import org.jdom2.input.SAXBuilder; public class JDOM_Exam2_ReadXMLFile { public static void main(String[] args){ /** * step1,创建SAXBuilder,并且使用该对象创建DOM树 * */ String file="D:"+File.separator+"test.xml"; SAXBuilder builder=new SAXBuilder(); Document dom=null;//创建DOM树 try { dom=builder.build(file); } catch (JDOMException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } /** * step2,通过前面创建的*.xml对应的DOM树访问树中的元素 * */ Element addresslist=dom.getRootElement(); List list=addresslist.getChildren("linkman"); for(int i=0;i<list.size();i++){ Element linkman=(Element) list.get(i); String name=linkman.getChildText("name"); String id=linkman.getChild("name").getAttributeValue("id"); String email=linkman.getChildText("email"); System.out.println("编号:"+id+" 姓名:"+name+" 邮箱:"+email); } } }
程序运行结果:
编号:001 姓名:lxrm 邮箱:123@qq.com 编号:002 姓名:lx 邮箱:123@qq.com
- 待读取的*.xml文件
- 示例一,使用JDOM组件提供的java API生成一个xml文件,使得该文件包含以下内容
- 涉及到的java API

5.3 DOM4J(另一种用于XML文件解析的java组件)
5.3.1概述
-
- DOM和SAX解析方法都有各自的缺点,所以其他一些学者就开始研究有没有更好地XML文档解析方案,很多好的XML文档解析方法应运而生,但是水平参差不齐,后来JDOM和DOM4J凭借着自己的优良性能展露头角,得到广泛流行
- 上面一节讲述了JDOM的用法,这节讲述另一种组件——DOM4J的用法
- DOM4J和JDOM一样,也是在基础的XML文件解析API上发展而来的,同时拥有两种解析方法的优点
- DOM4J是SourceForge发表的
- DOM4J也是开源的
- 可以从http://sourceforge.net/projects/dom4j/files网址下载DOM4J开发包(该开发包中包含很多jar包,一般情况下只需要引入dom4j-*.jar和lib/jaxen-*-beta-*.jar这两个jar包到自己的项目即可,至于其他的jar包,则可以根据实际需求选用)
- DOM4J得到了广泛应用,如Hibernate/Spring框架中都使用了DOM4J
- DOM4J组件所提供的常用接口如下表,一般在自己的project中使用下面这些接口解析*.xml文件(这些接口的用法和JDOM中相应接口的用法类似)

5.3.2使用DOM4J组件提供的javaAPI操作*.xml
-
- 涉及到的类(java API):
- 编程思路:
- 首先从http://sourceforge.net/projects/dom4j/files下载DOM4J相应开发包,并且将其集成至自己的project中
- 具体导入过程参见如下博客:如何在eclipse中导入dom4j组件的开发包(即java API)
- 其次针对项目实际需求使用DOM4j组件提供的相应java API编写程序实现相应操作
- 实例1,xml文件的读取
- 涉及到的类:
-
import java.io.File; import java.util.Iterator; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader;
-
- 编程思路:
-
/** * step1,创建SAXReader对象,将*.xml文档转变成DOM树 *step2,通过step1中建立的DOM树访问树中节点内容(也即XML文件标签内容) * */
-
- 示例:
- 问题描述:读取*.xml中的内容,并在后台输出相应内容
<?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>lxrm</name> <email>123@123.com</email> </linkman> <linkman> <name>lx</name> <email>123@123.com</email> </linkman> <link> <name>link子节点</name> <email>123@123.com</email> </link> </addresslist>
编程实现:

/** *@author lxrm *@date 2017年4月10日 *@description:*/ package xml.operation; import java.io.File; import java.util.Iterator; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class DOM4J_Exam2_ReadXMLFile { public static void main(String[] args){ /** * step1,创建SAXReader对象,将*.xml文档转变成DOM树 * */ String path="D:"+File.separator+"testDOM4J.xml"; File file=new File(path); SAXReader reader=new SAXReader(); Document dom=null; try { dom=reader.read(file); } catch (DocumentException e) { // TODO Auto-generated catch block e.printStackTrace(); } /** * step2,通过step1中建立的DOM树访问树中节点内容(也即XML文件标签内容) * */ Element root=dom.getRootElement();//根节点“addresslist” Iterator it=root.elementIterator();//根节点的一级子节点(直接子节点)的集合 while(it.hasNext()){ Element linkman=(Element) it.next(); String name=linkman.elementText("name"); String email=linkman.elementText("email"); System.out.println("姓名:"+name+" 邮箱:"+email); } } }
运行结果:
姓名:lxrm 邮箱:123@123.com 姓名:lx 邮箱:123@123.com 姓名:link子节点 邮箱:123@123.com
- 问题描述:读取*.xml中的内容,并在后台输出相应内容
- 涉及到的类:
- 实例2,修改*.xml文件(或者新建*.xml文件)
- 涉及到的类:
-
import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.XMLWriter;
-
- 编程思路:
-
/** * step1,创建待写入*.xml文件的DOM树 * step2,将step1中创建的DOM树输出成*.xml文件 */
-
-
示例:
-
问题描述:希望通过java程序创建一个拥有如下内容的*.xml文件
-
-
编程实现:

-
/** *@author lxrm *@date 2017年4月10日 *@description:使用SourceForge公司开发并开源的DOM4J组件来进行xml文件的解析操作 * *本程序功能:新建一个*.xml文件,并且在本java程序中定义该*.xml文件的内容 * **/ package xml.operation; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.XMLWriter; public class DOM4J_Exam1_WriteXMLFile { public static void main(String[] args) { /** * step1,创建待写入*.xml文件的DOM树 */ Document dom=DocumentHelper.createDocument(); Element addresslist=dom.addElement("addresslist");//直接在Document对象上添加根节点 Element linkman=addresslist.addElement("linkman"); Element name=linkman.addElement("name"); Element email=linkman.addElement("email"); name.setText("lxrm"); email.setText("123@123.com"); /** * step2,将step1中创建的DOM树输出成*.xml文件 * */ OutputFormat format=OutputFormat.createPrettyPrint(); format.setEncoding("GBK"); String file="D:"+File.separator+"testDOM4J.xml"; try { XMLWriter writer=new XMLWriter(new FileOutputStream(file),format); writer.write(dom); writer.close(); } catch (UnsupportedEncodingException | FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
-
-
运行结果:
-
-
- 涉及到的类:
- 实例1,xml文件的读取
- 首先从http://sourceforge.net/projects/dom4j/files下载DOM4J相应开发包,并且将其集成至自己的project中
- 涉及到的类(java API):

