13.1堆的概念
-
- 堆是一种二叉树,是一种特殊的二叉树
 节点的子节点的关键字
节点的子节点的关键字


13.2 java程序实现堆这种数据结构
13.2.1编程思路:
step1,首先了解堆的概念
-
-
- 堆是完全二叉树
- 使用数组来存储堆元素,熟记数组元素下标和子节点、父节点的关系
- 如果堆中某个节点的数组下标为x,那么

- 熟记“”堆条件“”
-
step2,依据堆的概念,设计class Heap中成员函数——fun:删除堆中关键值最大的节点
-
-
- 编程思路
-
- java代码
- 编程思路
-





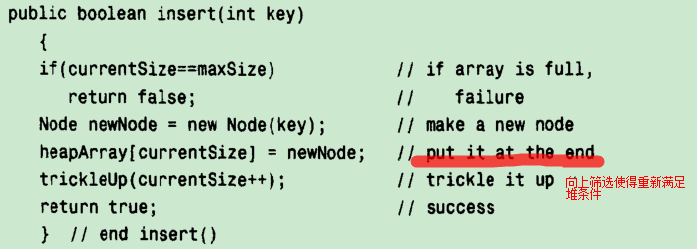
step3,依据堆的概念,设计class Heap中的成员函数——fun:往现有的堆中插入一个新的节点
-
-
- 编程思路:

-
向上筛选,使得新插入的节点关键值小于父节点关键值,大于子节点关键值,使得新的二叉树重新满足“”堆条件“”
-
只需要将新节点关键值和其“”暂时位置“”上的父节点的关键值相比较,并根据需要交换位置即可
-
- java代码:
-
trickleUp(int index)函数将新节点向上筛选使得重新满足堆条件,该函数的参数是节点在存储堆元素的数组中的位置下标
-
应注意上述程序中插入的一个新的节点之后,数组大小currentSize++

- 编程思路:
-
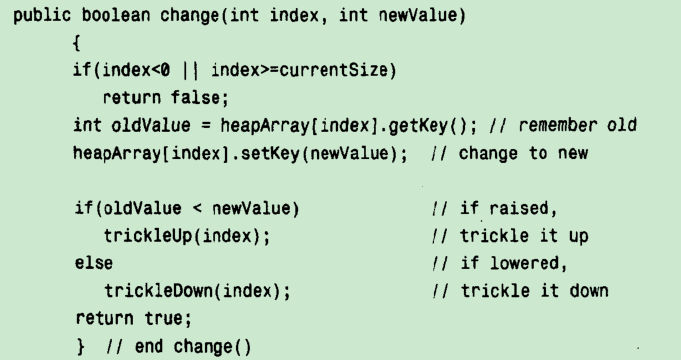
step4,依据堆的概念,设计class Heap中的成员函数——fun:改变的堆中某个节点的值
-
-
- 编程思路:
- 如果该节点的关键值降低了,就向下筛选使得新的二叉树重新满足堆条件
- 如果该节点的关键值上升了,就向上筛选
- java代码:
- 编程思路:
-
13.2.2 用java所实现的Heap:class (完整程序)
-
-
Node.java
/** * @description: 堆中节点类,由于堆是使用数组存储的二叉树,所以堆的节点类中不必有引用,引用之类的属性是不必要的*/ package tree; import POJO.Student; public class HeapNode { private String key;//关键字 private double data;//数据项(基本数据类型) private Student stu;//数据项(POJO对象) public HeapNode(){} public HeapNode(String key,double data,Student stu){ this.key=key; this.data=data; this.stu=stu; } //输出节点中的数据内容 public void displayNode(){ System.out.println("节点关键字key="+this.key); System.out.println("节点数据内容:data:double="+this.data+" Student.name="+this.stu.getName()); } public String getKey(){ return this.key; } public void setKey(String key){ this.key=key; } public double getData(){ return this.data; } }
Heap.java
/** * @author lxrm * @date 20161024 * @description * 堆:这是树的应用,堆是一种特殊的二叉树 * 堆是完全二叉树 * 堆是用数组实现的二叉树 * (堆条件)堆这种特殊的二叉树必须满足一个条件,即树中父节点的关键值必须大于其子节点的关键值*/ package tree; import POJO.Student; public class Heap { private HeapNode heapArray[];//堆数组,用于存储堆中各个节点 private int maxSize;//堆中可存储的最大元素个数 private int currentSize;//堆中现有元素个数 /** *@param size:int 堆数组大小(由于堆这种二叉树的所有节点是使用数组来存储的,所以要在开始就初始化相应的数组,该参数是数组大小,也是堆中元素最大个数 **/ public Heap(int size){ heapArray=new HeapNode[size]; maxSize=size; currentSize=0; } /** * @description:向堆中插入数据 * 编程思路:step1,将待插入数据封装成Node对象(节点对象) * step2,将待插入节点对象放到堆最底层最末尾位置(往堆中插入新的节点,但是现在还不满足堆的条件) * 先判断当前堆数组是否已满,若已满则不能插入新的节点 * 若堆未满,则将待插入节点放置在堆数组末尾位置(末尾第一个空位置) * step3,使新插入的节点沿着路径上升,直到满足堆的条件(即使得父节点关键值大于子节点关键值)*/ public void insert(String key,double data,Student stu){ HeapNode newNode=new HeapNode(key,data,stu);//step1 if(currentSize==maxSize){//step2 System.out.println("堆已满,无法插入新的节点"); return; } heapArray[currentSize++]=newNode; this.tricleUpNode(currentSize-1);//step3,将乱序节点heapArray[currentSize]沿路径上升放置到正确的位置,使乱序二叉树重新满足堆条件 } /** * @description:删除堆中优先级最高的元素,并将该元素作为返回值返回*/ public HeapNode deleteRoot(){ HeapNode root=heapArray[0];//根元素,下面的程序会将根节点删除,所以如果后面还想使用该节点中的数据,就要先将该节点保存下来 heapArray[0]=heapArray[currentSize-1];//step1:将根节点删除,并将堆中最后一个节点放到根节点的位置(这样使得删除根节点后的堆还是完全二叉树) currentSize--;//step2:删掉了一个节点,所以堆数组的当前大小要减一 this.tricleDownNode(0);//step3:此步骤将前面所得无序完全二叉树重新满足堆条件 return root; } /** * @description:这个函数用于更改某个节点的关键值大小,且在更改后自动重新排序,以使其重新满足堆条件(父节点关键值比两个子节点的关键值都大) * @param index:int 待改动节点的索引值(即该节点在堆数组中的下标值) * @param targetKey:String 目的关键字值 * */ public void changeKey(int index,String targetKey){ if(index<0||index>=currentSize){ System.out.println("给出的index超出范围,index应该在[0,"+currentSize+")中取值"); return; } String initKey=heapArray[index].getKey(); heapArray[index].setKey(targetKey); if(targetKey.compareTo(initKey)>0){ this.tricleUpNode(index); }else{ this.tricleDownNode(index); } } /** * @description:这个函数用于使参数节点沿着"树路径"上升,直至这个树重新满足"堆条件"(堆条件:父节点关键字值大于他的子节点的关键字的值) * @param node:HeapNode 乱序节点,本函数可以使这个乱序节点最终被放置在正确的位置,从而使得“乱序完全二叉树”编程符合堆条件的堆 * @param index:int 乱序节点在数组中的位置,也即乱序节点在堆数组中的下标 * 编程思路:从乱序节点开始,沿着树路径上升,查找乱序节点应该被放置的正确位置 * 树路径是这样的,乱序节点-->乱序节点的父节点-->乱序节点的父节点的父节点(用数组实现的堆中parentIndex=(childIndex-1)/2) * 终止条件:父节点下标<0,或者途中某个父节点的关键值大于乱序节点的关键值 * */ private void tricleUpNode(int index){ HeapNode tmp=heapArray[index];//暂时存储乱序节点的地址值 int currentIndex=index;//从当前节点开始沿着“树路径”上升,查找乱序节点应该被放置的正确位置 int parentIndex=(currentIndex-1)/2;//父节点数组下标 //如果父节点的关键值比乱序节点的关键值小,则父节点下移 while((parentIndex>=0)&&(heapArray[parentIndex].getKey().compareTo(heapArray[currentIndex].getKey())<0)){ heapArray[currentIndex]=heapArray[parentIndex]; currentIndex=parentIndex; parentIndex=(parentIndex-1)/2; } heapArray[currentIndex]=tmp; } /** * @description:从无序节点开始,沿着树路径“向下查找”参数节点应该被放置的位置,并且将参数节点放置到正确的位置,使得乱序的完全二叉树重新满足堆条件 * @param index:int 无序节点在数组中的位置,数组下标 * 编程思路:从参数节点(无序节点)开始,沿着树路径向下查找,直至找到无序节点应该被放置的正确位置 * 从当前层到下一层有两条路径,应该选择哪条路径呢(答:应该选择关键值较大的子节点构成实际行走的路径) * 终止条件:当前层节点作为父节点,比左子节点和右子节点关键值都大,则当前层节点位置就是乱序节点应该被放置的正确位置 * 终止条件:查找到了堆末尾位置*/ private void tricleDownNode(int index){ HeapNode tmp=heapArray[index];//step1:暂时存储无序节点对象 int currentIndex=index; int leftChildIndex=2*currentIndex+1; int rightChildIndex=leftChildIndex+1;//这样写可以比乘法少些运算量,节省运行时间 while(leftChildIndex<currentSize){//至少有一个子节点时(也即至少拥有左子节点) boolean flagLeftChild=tmp.getKey().compareTo(heapArray[leftChildIndex].getKey())>0;//当前节点关键值比其左子节点的关键值大,该值为true if(rightChildIndex<currentSize){//拥有两个子节点时 boolean flagRightChild=tmp.getKey().compareTo(heapArray[rightChildIndex].getKey())>0;//当前节点的关键值比其右子节点的关键值大,该值为true if(flagLeftChild&&flagRightChild){//当乱序节点关键值比heapArray[currentIndex]左子节点和右子节点都大时,currentIndex就是乱序节点应该被放置的位置 break; }else{ if(heapArray[leftChildIndex].getKey().compareTo(heapArray[rightChildIndex].getKey())>0){ heapArray[currentIndex]=heapArray[leftChildIndex]; currentIndex=leftChildIndex; }else{ heapArray[currentIndex]=heapArray[rightChildIndex]; currentIndex=rightChildIndex; } leftChildIndex=2*currentIndex+1; rightChildIndex=leftChildIndex+1; } }else{//仅拥有一个子节点时(即只拥有左子节点时) if(flagLeftChild){//如果当前节点关键值比左子节点关键值大,就跳出while循环,currentIndex就是乱序节点应该插入的位置 break; }else{ heapArray[currentIndex]=heapArray[leftChildIndex]; currentIndex=leftChildIndex; break;//这里已经是堆末尾,所以可以跳出while循环 } } }//end while heapArray[currentIndex]=tmp; }//end tricleDownNode() //堆是否为空 public boolean isEmpty(){ return currentSize==0; } //堆是否已满 public boolean isFull(){ return currentSize==maxSize; } //将堆展示在屏幕上 public void displayHeap(){ int layerNum=1;//每层节点数目 int index=0;//堆中元素索引(也即堆数组下标) //展示堆数组 System.out.println("heapArray:"); for(;index<currentSize;index++){ System.out.print(heapArray[index].getKey()+" "); } /* //以树的形式展示堆(有待改进) while(true){ for(int i=0;i<layerNum;i++){ if(heapArray[index].getKey()!=null){ System.out.print(heapArray[index].getKey()+" "); } index++; if(index>=currentSize-1){ return; } } System.out.println("index="+index); layerNum=2*layerNum; }//end while() */ } }
-
13.3 堆的特点(性质)
-
- 堆是一种特殊的二叉树,它的父节点的关键值大于子节点的关键值,但是不能保证右子节点的关键值大于左子节点的关键值,所以没有一种遍历方法能够按照一定的顺序(升序或者降序)顺序访问树中所有节点。
- 但是堆能保证,按照从根节点到任何一个叶子节点的路径,关键值都是按照降序排列的。
- 堆,除了以上所述无法进行按序遍历之外,还有一些缺点,如:不便于按照关键值查找特定的节点。
- 因为不易查找到指定关键值的节点,所以也不易删除某个指定关键值的节点,因为删除之前要先定位该节点。
- 堆的时间复杂度:
- 查找指定关键值的节点O(N) 在存储堆元素的数组中依次查找,所以时间复杂度为O(N)
- 删除指定关键值的节点O(N) 查找定位+删除+移动子树
- 往堆中插入一个新的节点O(logN) 先插入到堆的末尾,然后向上筛选新插入的节点,使得重新满足“堆条件”
- 删除堆中关键值最大的节点O(logN) 删除根节点,然后将最后一个节点作为根节点,再向下筛选使得重新满足“堆条件”
- 已有的堆中先删除一个节点,紧接着再将该节点插入堆中,得到的新的堆可能和之前的堆不一样。如:堆中删除最大关键值节点(即根节点)后再将该节点插入到堆中,得到的新的堆和之前的堆是不一样的。
- 同样的一组节点,形成的堆可能不一样,最后形成的堆和节点的插入顺序有关。
- 如何扩展堆:
- 由于堆是使用数组存储的完全二叉树,不停地往堆中插入新的元素的情况下,有可能会导致存储堆元素的数组溢出,这时就要扩展堆数组。
- 需要创建一个新的堆数组,应使新的堆数组的容量为之前的二倍,并且将原有数组内容copy到新的数组中即可。
- 为了避免上述手动扩展过程,可以不使用数组来存储堆元素,而是使用Vector类来存储堆元素,因为Vector可以自动扩展容量。

-

13.4 堆的应用场景
场景一:堆可用于实现优先级队列。(用堆实现的优先级队列,往队列插入新队员和删除队首元素的时间复杂度都是O(logN))
概述:优先级队列有多种实现方法,如使用有序数组就可以实现优先级队列,这种方法中元素的插入时间为O(N),因为要移动数组元素。
根据上面的叙述可知,使用有序数组实现的优先级队列,新元素的插入较慢,所以考虑使用其他方法实现优先级队列。
可以使用堆来实现优先级队列。
堆实现优先级队列的方法:
往队列中插入新的元素就用Heap类中的insert()函数
删除队首元素就用Heap类中的deleteRoot()函数
场景二:使用堆实现堆排序
概述:借助于堆,将一个无序数据集按照从大到小的顺序排列
堆排序的实现:将无序数据依次插入堆中
然后使用Heap类中的deleteRoot()函数不停地删除堆顶部的元素
堆排序的时间复杂度:O(N*logN)