参考:
https://www.osgeo.cn/scrapy/intro/tutorial.html
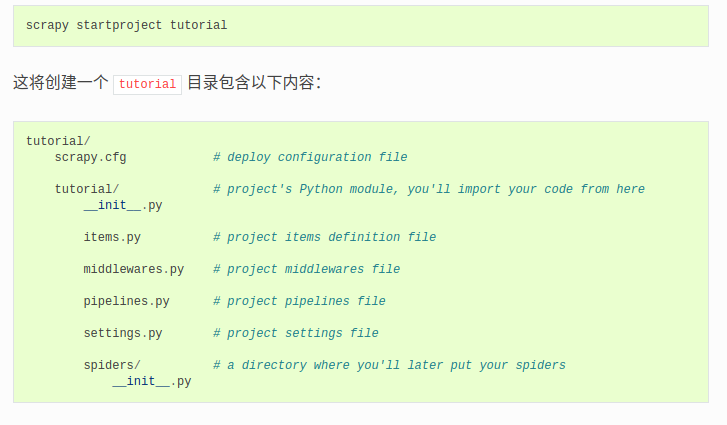
创建project后的目录结构如下:
project_name(folder) ------project_name(folder) ------scrapy.cfg
一 、 建立python运行env
二、 启动env
D:�0pystudy�1envScripts>activate.bat
(01env) D:�0pystudy�1envScripts>pip list
三、安装 scripy
(01env) D:�0pystudy�1envScripts>pip install Scripy
四、确认是否成功
(01env) D:�0pystudy�1envScripts>pip list
Package Version
---------------- -------
asgiref 3.2.3
attrs 19.3.0
Automat 20.2.0
cffi 1.14.0
constantly 15.1.0
cryptography 2.8
cssselect 1.1.0
Django 3.0.3
scripy 1.8
Django 3.0.3
五、创建爬虫工程跟目录
(01env) D:�0pystudy>mkdir 09scripy
(01env) D:�0pystudy>cd 09scripy
六、进入目录,创建工程
(01env) D:�0pystudy�9scripy>scrapy startproject scrapy_spider
七、用pycharm打开,
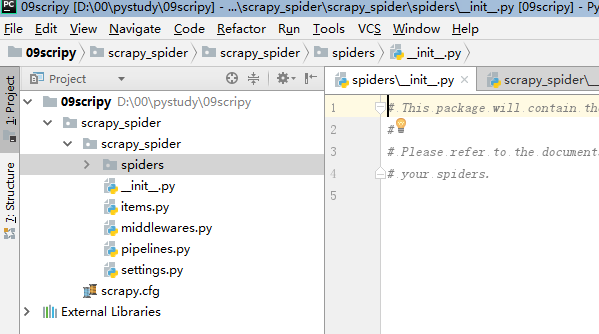
八、工程创建完后,创建爬虫
可以用指令模板创建,也可以手工创建py文件。
(01env) D:�0pystudy�9scripy>cd scrapy_spider
(01env) D:�0pystudy�9scripyscrapy_spider>scrapy genspider quotes_spider quotes.toscrape.com
Created spider 'quotes_spider' using template 'basic' in module:
scrapy_spider.spiders.quotes_spider
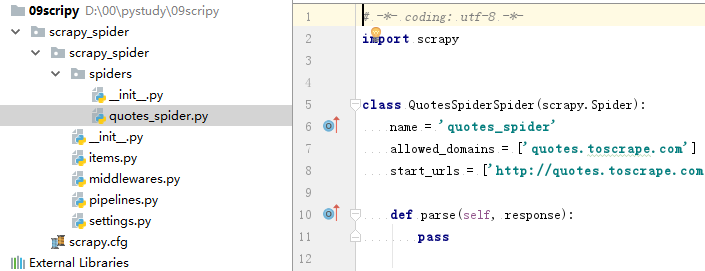
九、编辑parse() ,运行
def parse(self, response): quotes = response.xpath("//div[@class='quote']//span[@class='text']/text()").extract() yield {'quotes': quotes}
在工程目录下(含scrapy.cfg),执行 scrapy crawl quotes_spider
