MXNET框架基础7-BN
1、ailab 代码中wobn和wbn模型的区别
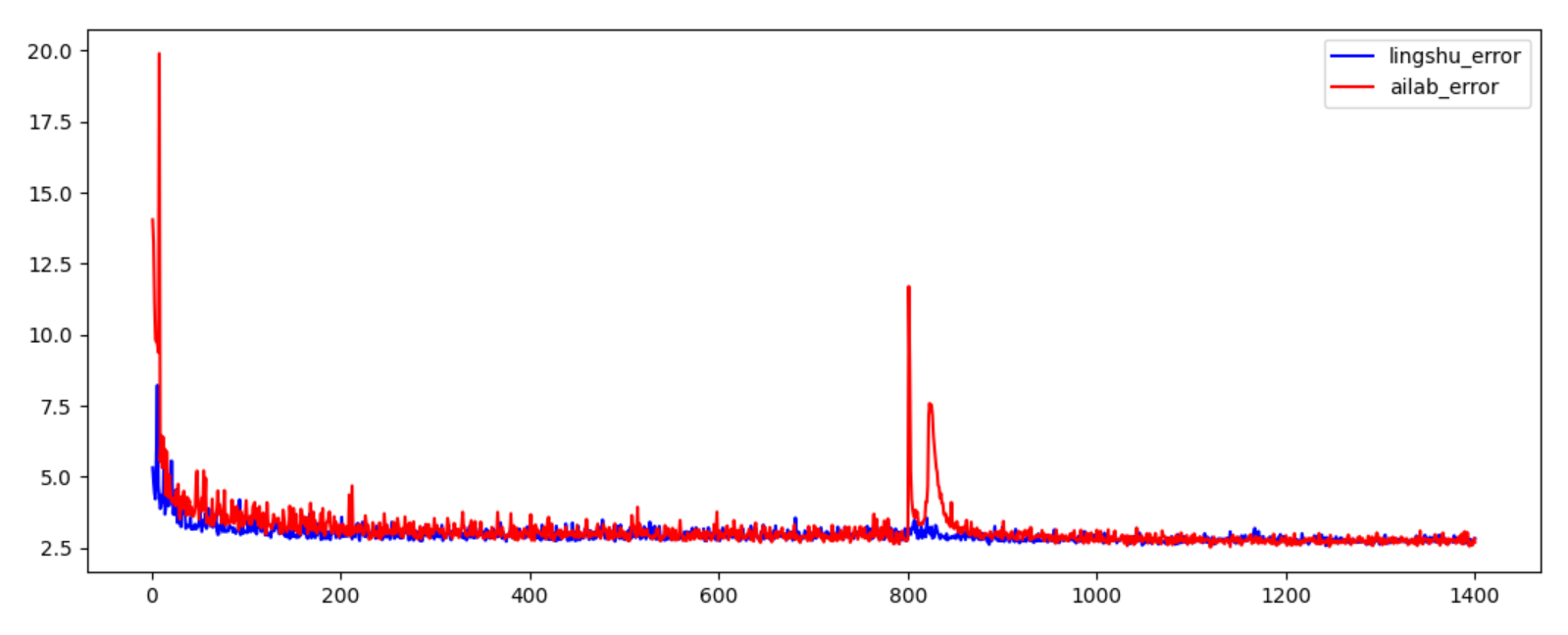
wbn with BN 层模型的训练 前800轮wbn训练
wobn without BN的模型训练 800轮后wobn训练
正如图
以

局部放大图
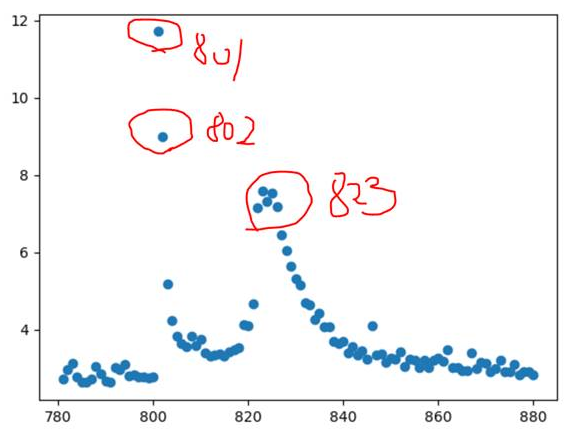
这时出现的大抖动 就是wbn训练后 抽调BN层,导致wobn开始训练时出现抖动,后逐渐平稳。
2 为什么用WOBN
3 BN 原理
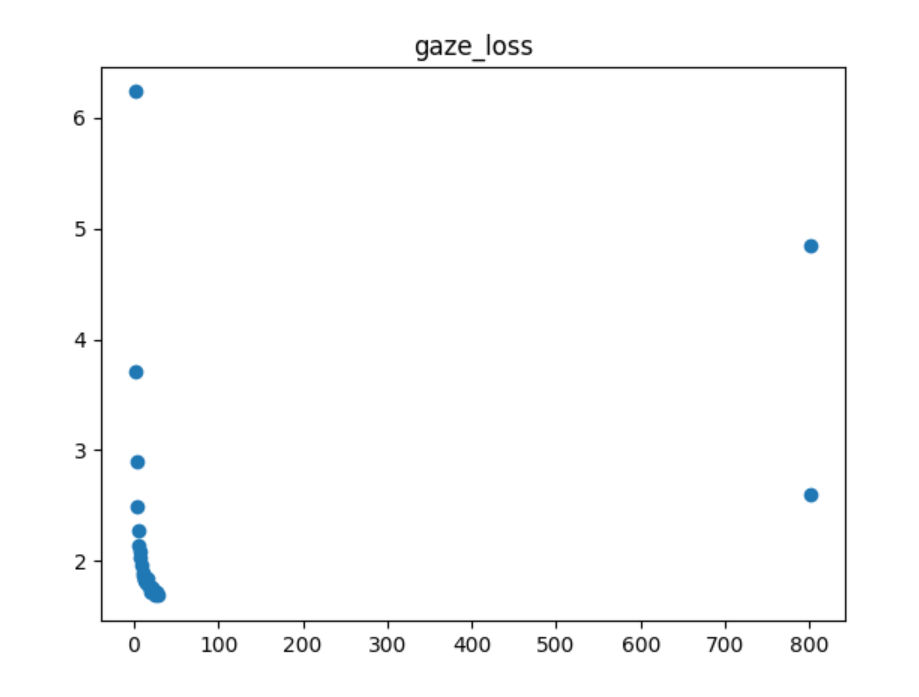
附: 训练gaze模型 gazeloss变化
ailab loss

lingshu loss
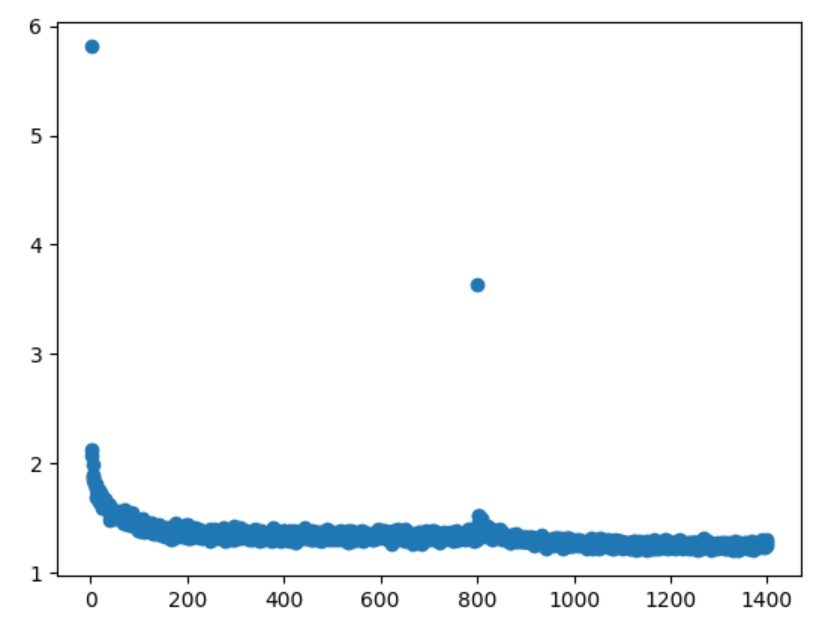
比较
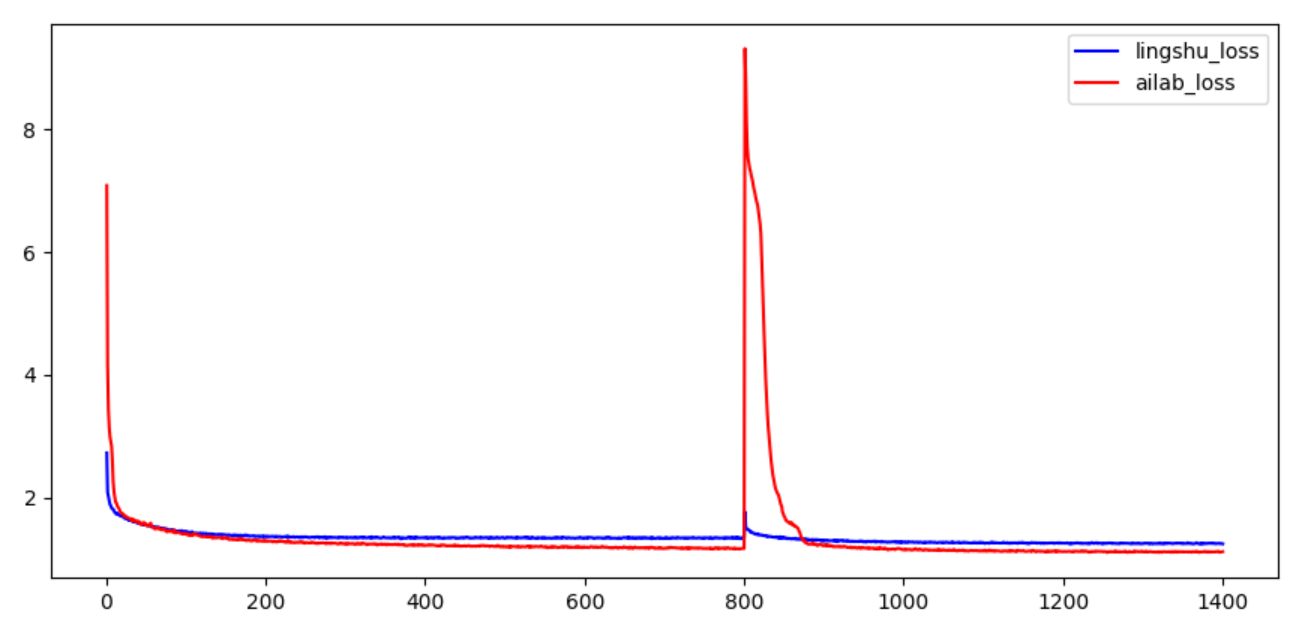
放大图 说明ailab的loss 略优于 零束的loss
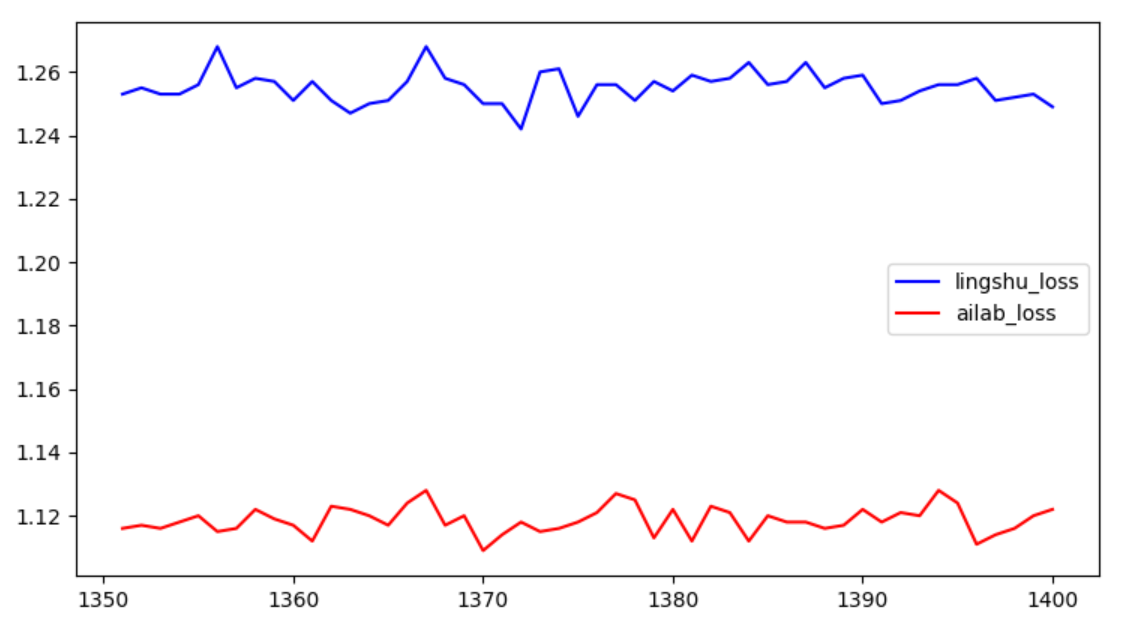
ailab使用batch-size 为4096 4个GPU 每个GPU1024个
lingshu使用batch-size为256
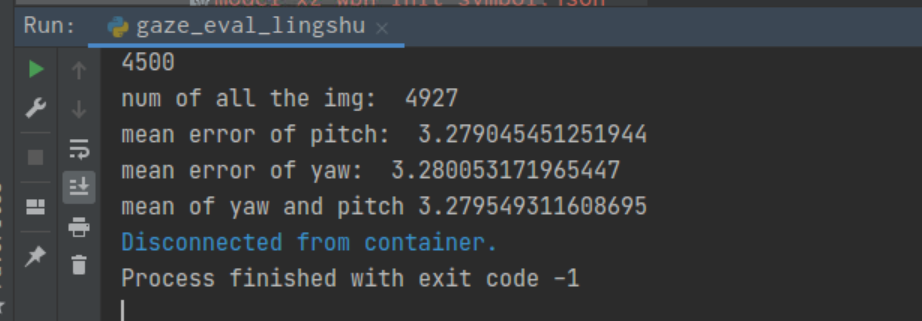
接下来,gaze error 比较以LeftEyePitchMAE 为例
放大图 说明gaze error LeftEyePitchMAE最后相差不大。

提问1:总数量4万,batchsize为4096,分在四个GPU计算。与batchsize为256,一个GPU,哪个更快收敛,哪个训练的模型更优(更容易找到最优解)
提问2:为什么权重可以在4个GPU同时训练。
已解决
为什么数据并行的batchsize相当于增大了
https://www.zhihu.com/question/323307595
提问3:证明过拟合? 在验证集上输出的内容将loss输出,或在训练集上将 指标输出。
-------------------------
epoch 851 ailab 的权重在1102测试集表出现为8度 这个就是奇怪?

于是对比了851的gaze_loss 和error
gaze_loss 比851低的零束数据

只有epoch 800。
error 比851低的有一些 892,829等 但是这些model在1102测试集表现都是pitchMAE=3.不能复现出 ailab epoch=851时 pitchMAE=8.
目前看是 因为训练的参数配置不一致。
重新配置一样的参数,四个卡,一样batchsize。比较
loss 超过851的loss的权重
error 超过851的权重 为1172