【5216 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 】
WEEK NINE (4.18——4.24)期中总结
SECTION 0 学习目录
- 第一周《计算机是如何工作的?》 http://www.cnblogs.com/lwr-/p/5211491.html
- 第二周《操作系统是如何工作的?》 http://www.cnblogs.com/lwr-/p/5235693.html
- 第三周《构建一个简单的操作系统MenuOS》http://www.cnblogs.com/lwr-/p/5256212.html
- 第四周 《扒开操作系统的“三层皮”(上)》http://www.cnblogs.com/lwr-/p/5280810.html
- 第五周《扒开操作系统的“三层皮”(下)》http://www.cnblogs.com/lwr-/p/5313464.html
- 第六周《进程的描述与创建》http://www.cnblogs.com/lwr-/p/5330839.html
- 第七周《可执行程序的装载》http://www.cnblogs.com/lwr-/p/5353078.html
- 第八周《进程的切换和系统的一般执行过程》http://www.cnblogs.com/lwr-/p/5379835.html
SECTION 1 基础知识点归纳梳理
1.计算机基础
- 寻址方式
- 直接寻址&立即数寻址
- movl $0x123,%eax —— %eax=0x123
- movl 0x123,%eax —— 立即数是以$开头的十六进制数值。直接访问指定的内存地址(0x123)中的数据然后赋给%eax
- 变址寻址
- movl 4(%ebx),%edx//edx = *(inet_32 *)(ebx+4),即ebx的值加4之后作为一个地址,将其指向的数据赋给%edx
- 直接寻址&立即数寻址
- 重要的汇编指令
-

-

- enter指令相当于在原来的堆栈上再建一个新的空堆栈【因为将栈底指针%ebp挪到和栈顶指针相同的位置了】
- leave指令与enter相反,相当于撤销函数调用堆栈【把栈顶指针提上来,则撤消了该栈】
-
2.计算机工作模式
- 参数传递过程
-
以如下的代码反汇编程序为例:
#include <stdio.h> void p1(char c) { printf("%c",c); } int p2(int x,int y) { return x+y; } int main(void) { char c ='a'; int x,y; x =1; y =2; p1(c); z = p2(x,y); printf("%d = %d+%d",z,x,y); } -
补充:关于z = p2(x,y)一句
-
关于0xfffffff4、0xfffffff8的意思?
- 我在网上查了一下,其实这里面的0x虽然是16进制的意思,不过f并不是表示负数,而是一种内存表示方法(也有说0xfffffff4这个地址有一些其他的限制)
-
前两条语句什么意思?
- 就是把y的值和x的值存放到堆栈中;
- 为什么不是pushl y而是采用变址寻址的方式呢?因为这两个值是局部变量,已经被保存在堆栈中了,所以就可以用变址寻址的方式找到;
- 前两句中的pushl对应着第四句的add $0x8,%esp即:有压栈必有出栈
-
如何将p2的值返回给调用函数?
- 看mov %eax,0xfffffffc(%ebp)一句;
- 0xfffffffc(%ebp)的位置上放置的是z,也就是说,这句指令将把返回值赋给z
-
push $0x8048510;就是把内存地址的内容压入堆栈
-
3.简单的Linux操作系统相关代码
-
简单的内核源代码分析
-
mymain.c 内核初始化和0号进程启动
1 /* 2 * linux/mykernel/mymain.c 3 * 4 * Kernel internal my_start_kernel 5 * 6 * Copyright (C) 2013 Mengning 7 * 8 */ 9 #include <linux/types.h> 10 #include <linux/string.h> 11 #include <linux/ctype.h> 12 #include <linux/tty.h> 13 #include <linux/vmalloc.h> 14 15 16 #include "mypcb.h" 17 18 tPCB task[MAX_TASK_NUM]; //声明一个task数组,tPCB结构体类型在mypcb.h中有定义 19 tPCB * my_current_task = NULL; 20 volatile int my_need_sched = 0; 21 22 void my_process(void); 23 24 25 void __init my_start_kernel(void) 26 { 27 int pid = 0; //这样的话修改进程序号就很方便 28 int i; 29 /* Initialize process 0*/ //以下是0号进程数据结构的初始化 30 task[pid].pid = pid; 31 task[pid].state = 0;/* -1 不可运行, 0 可运行, >0 停止*/ 32 task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process; //见第58行开始的my_process函数;起点是my_process 33 task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1]; //堆栈的栈顶位置,这个在mypcb.h中也有定义 34 task[pid].next = &task[pid]; //下一个进程还是指向自己(这时候没有其他进程) 35 /*fork more process */ 36 for(i=1;i<MAX_TASK_NUM;i++) 37 { 38 memcpy(&task[i],&task[0],sizeof(tPCB)); //copy一下0号进程的状态,然后需要修改的地方再修改(好机智的做法) 39 task[i].pid = i; 40 task[i].state = -1; //不能让它们现在就开始运行 41 task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1]; 42 task[i].next = task[i-1].next; //42,43两句是很常见的链表加入新项的方法 43 task[i-1].next = &task[i]; 44 } 45 /* start process 0 by task[0] */ //为什么这里会是两句pushl和两句popl(ret相当于popl eip)?我的理解是:这样使得新的堆栈中的ebp和eip都与task[i]相匹配(esp的位置已经由第49句决定) 46 pid = 0; //作用同第27行 47 my_current_task = &task[pid]; 48 asm volatile( 49 "movl %1,%%esp " /* set task[pid].thread.sp to esp */ //确定esp的位置 50 "pushl %1 " /* push ebp */ //当前的栈是空的,ebp就等于esp 51 "pushl %0 " /* push task[pid].thread.ip */ //IP压栈 52 "ret " /* pop task[pid].thread.ip to eip */ //弹出来eip,这之后0号进程正式启动 53 "popl %%ebp " //弹出来ebp,内核初始化工作完成 54 : 55 : "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/ 56 ); 57 } 58 void my_process(void) //所有的进程都以这个作为起点 59 { 60 int i = 0; 61 while(1) 62 { 63 i++; 64 if(i%10000000 == 0) 65 { 66 printk(KERN_NOTICE "this is process %d - ",my_current_task->pid); 67 if(my_need_sched == 1) //执行10 000 000次才判断一次是否需要调度 68 { 69 my_need_sched = 0; //在第20行初始化为0 70 my_schedule(); 71 } 72 printk(KERN_NOTICE "this is process %d + ",my_current_task->pid); 73 } 74 } 75 } -
myinterrupt.c 调度机制
1 /* 2 * linux/mykernel/myinterrupt.c 3 * 4 * Kernel internal my_timer_handler 5 * 6 * Copyright (C) 2013 Mengning 7 * 8 */ 9 #include <linux/types.h> 10 #include <linux/string.h> 11 #include <linux/ctype.h> 12 #include <linux/tty.h> 13 #include <linux/vmalloc.h> 14 15 #include "mypcb.h" 16 17 extern tPCB task[MAX_TASK_NUM]; 18 extern tPCB * my_current_task; 19 extern volatile int my_need_sched; 20 volatile int time_count = 0; 21 22 /* 23 * Called by timer interrupt. 24 * it runs in the name of current running process, 25 * so it use kernel stack of current running process 26 */ 27 void my_timer_handler(void) 28 { 29 #if 1 30 if(time_count%1000 == 0 && my_need_sched != 1) //设置时间片的大小,时间片用完时设置一下调度标志。只要满足上述两个条件,就将my_need_sched设为1,这样mymain.c循环到这个进程的时候就可以对这个进程进行调度 31 { 32 printk(KERN_NOTICE ">>>my_timer_handler here<<< "); 33 my_need_sched = 1; 34 } 35 time_count ++ ; 36 #endif 37 return; 38 } 39 40 void my_schedule(void) 41 { 42 tPCB * next; 43 tPCB * prev; 44 45 if(my_current_task == NULL 46 || my_current_task->next == NULL) 47 { 48 return; 49 } 50 printk(KERN_NOTICE ">>>my_schedule<<< "); 51 /* schedule */ 52 next = my_current_task->next; 53 prev = my_current_task; 54 if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */ //在两个正在执行的进程之间做上下文切换 55 { 56 /* switch to next process */ 57 asm volatile( 58 "pushl %%ebp " /* save ebp */ 59 "movl %%esp,%0 " /* save esp */ 60 "movl %2,%%esp " /* restore esp */ 61 "movl $1f,%1 " /* save eip */ //$1f就是指标号1:的代码在内存中存储的地址 62 "pushl %3 " 63 "ret " /* restore eip */ //这两句使得下一个进程的ip作为eip,这样下一个进程就会接下来执行 64 "1: " /* next process start here */ 65 "popl %%ebp " 66 : "=m" (prev->thread.sp),"=m" (prev->thread.ip) 67 : "m" (next->thread.sp),"m" (next->thread.ip) 68 ); 69 my_current_task = next; 70 printk(KERN_NOTICE ">>>switch %d to %d<<< ",prev->pid,next->pid 71 } 72 else //进程是一个新的进程(从来没有执行过) 73 { 74 next->state = 0; 75 my_current_task = next; 76 printk(KERN_NOTICE ">>>switch %d to %d<<< ",prev->pid,next->pid); 77 /* switch to new process */ 78 asm volatile( 79 "pushl %%ebp " /* save ebp */ 80 "movl %%esp,%0 " /* save esp */ 81 "movl %2,%%esp " /* restore esp */ 82 "movl %2,%%ebp " /* restore ebp */ //新进程的esp和ebp都是相同位置 83 "movl $1f,%1 " /* save eip */ 84 "pushl %3 " //保存当前进程的入口 85 "ret " /* restore eip */ 86 : "=m" (prev->thread.sp),"=m" (prev->thread.ip) 87 : "m" (next->thread.sp),"m" (next->thread.ip) 88 ); 89 } 90 return; 91 }- 这样,就完成了一个简单地操作系统内核程序并能够在虚拟机中启动。实现的效果就是0,1,2,3号进程依次循环切换。
-
-
简单分析一下start_kernel
- 分析一下Linux系统是如何启动的:
- 参考
- 代码节选(分析见注释)
-
不管分析内核的那一部分都会涉及到start_kernel;因为几乎所有的模块在启动的时候都是通过调用init函数来启动的
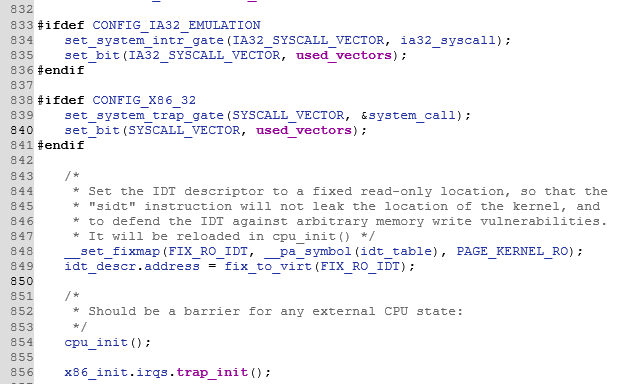
500asmlinkage __visible void __init start_kernel(void) 501{ 502 char *command_line; 503 char *after_dashes; 504 505 /* 506 * Need to run as early as possible, to initialize the 507 * lockdep hash: 508 */ 509 lockdep_init(); 510 set_task_stack_end_magic(&init_task);//init_task即手工创建的PCB,0号进程及最终的idle进程 511 smp_setup_processor_id(); 512 debug_objects_early_init(); 513 514 /* 515 * Set up the the initial canary ASAP: 516 */ 517 boot_init_stack_canary(); 518 519 cgroup_init_early(); 520 521 local_irq_disable(); 522 early_boot_irqs_disabled = true; 523 524/* 525 * Interrupts are still disabled. Do necessary setups, then 526 * enable them 527 */ 528 boot_cpu_init(); 529 page_address_init(); …… setup_log_buf(0); 558 pidhash_init(); 559 vfs_caches_init_early(); 560 sort_main_extable(); 561 trap_init();//初始化中断向量。跟踪此函数,见下方解释 562 mm_init(); …… 677 ftrace_init(); 678 679 /* Do the rest non-__init'ed, we're now alive */ 680 rest_init();//跟踪此函数,见下方解释 681} -
点击追踪561行的trap_init函数,找到x86对应的trap_init函数,可以看到其中设置了很多断点。
-

-
set_intr_gate就是set interrupt(设置断点)的意思;从图中也可以看到,程序中设置了很多不同的硬件中断。其中,第839行的系统陷阱门就是我们重点关注的系统调用。
-
rest_init中有kernel_thread函数:
-

-
此函数中有一个函数参数kernel_init:
-

-
run_init函数是系统的1号进程,用户态的第一个进程;
-
创建了一号进程后,kernel_thread函数通过405行的kthreadd管理线程;
-
由cpu_startup_entry(CPUHP_ONLINE);——>cpu_idle_loop();——>static void cpu_idle_loop(void):
- cpu_idle_loop中有一个while循环,当start_kernel启动之后,她就一直存在。当系统没有进场需要执行的时候就调度到idle进程。
-
- 分析一下Linux系统是如何启动的:
-
Linux系统启动过程总结
- kernel_thread是0号进程,它创建了1号进程kernel_init,以及它的一些服务的内核线程,这样整个系统及启动起来了;
- 然后init进程会再启动一些进程。
- 道生一,一生二,二生三,三生万物。系统就这样运行起来了
- 根据CSDN中博客的系统阐述,来龙去脉更加深邃
- init_task进程在Linux中属于一个比较特殊的进程,它是内核开发者人为制造出来的,而不是其他进程通过do_fork来完成【这是系统在通电之后就会加载的数据结构struct】
- Linux在无进程概念的情况下将一直从初始化部分的代码执行到start_kernel,然后再到其最后一个函数调用rest_init【这一点也是和视频中推的是一致的】
- 从rest_init开始,Linux开始产生进程,因为init_task是静态制造出来的,pid=0,它试图将从最早的汇编代码一直到start_kernel的执行都纳入到init_task进程上下文中。在rest_init函数中,内核将通过下面的代码产生第一个真正的进程(pid=1),也就是 kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);【0号进程创建1号进程】
- 此时init_task的任务基本上已经完全结束了,它将沦落为一个idle task【很符合操作系统精简一切不必要支出的特征】
- 事实上在更早前的sched_init()函数中,通过init_idle(current, smp_processor_id())函数的调用就已经把init_task初始化成了一个idle task,init_idle函数的第一个参数current就是&init_task,在init_idle中将会把init_task加入到cpu的运行队列中,这样当运行队列中没有别的就绪进程时,init_task(也就是idle task)将会被调用,它的核心是一个while(1)循环,在循环中它将会调用schedule函数以便在运行队列中有新进程加入时切换到该新进程上。【这样就保证了系统可以随时迎接新进程而不至于卡壳】
4.系统调用概述
-

- 解释:系统调用减少了系统与硬件之间的耦合,所以极大提高了系统可移植性
-
操作系统提供的API和系统调用的关系
-

-

-
解释:libc库定义的API使得程序员不用去以汇编代码进行系统调用而是直接以函数调用的形式。
-
-
系统调用的三层皮
-

-
系统调用的三层皮:xyz,system_call,sys_xyz。也就是:API,中断向量,服务程序
4.系统调用的参数传递方法(难点) -

-

-
补充解释:
- 系统调用号将xyz和sys_xyz关联起来;
- 为什么把eax寄存器的值设置为2?
- 参考http://www.cnblogs.com/bastard/archive/2012/08/31/2664896.html
- 这句话的意思是举例说明eax的作用,即:fork()通过系统调用创建与原进程几乎一样的进程。在进行系统调用之前就把_NR_fork(也就是2)传给eax
- 参数超过6个怎么办?
- 把某一个寄存器作为一个指针,指针会指向一个地址空间,把其他参数放在这里;这样内存也可以访问。
-
5.深入理解系统调用
- 理解system_call伪代码
-
system_call的位置就在ENTRY(system_call)处;(其他中断的处理过程与此类似)
-

-
501行的syscall_table是系统调用表(比如,对于time函数而言,在此处调用的就应该是sys_time)
-
503行after_call之后,保存返回值
-
505行要exit的时候,会有一个syscall_exit_work,否则直接返回用户态
-
进入syscall_exit_work之后,简化为下图所示的伪代码
-

-
19行,判断当前的任务是否需要处理syscall_exit_work;一般来说,系统调用都需要处理一些系统调度,也就是需要“work”
-
从第30行开始,跳转到work_pending。有work_notifying也就是处理信号;work_reschedle也就是重新调度(调度完之后再restore all)
-
- 画出从system_call到iret的流程图

6.进程的生命周期
-
进程的描述
-
进程描述符——struct task_struct
-

-

-
pid_t pid又叫进程标识符,唯一地标识进程
-
第1295行,list_head tasks即 进程链表
- 双向循环链表链接起了所有的进程,也表示了父子、兄弟等进程关系

-
struct mm_struct 指的是进程地址空间,涉及到内存管理(对于X86而言,一共有4G的地址空间)
-
thread_struct thread 与CPU相关的状态结构体
-
struct *file表示打开的文件链表
-
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
-
-
进程的创建
-
代码(以fork函数为例)
1.#include <stdio.h> 2.#include <stdlib.h> 3.#include <unistd.h> 4.int main(int argc, char * argv[]) 5.{ 6.int pid; 7./* fork another process */ 8.pid = fork(); 9.if (pid < 0) 10.{ 11./* error occurred */ 12.fprintf(stderr,"Fork Failed!"); 13.exit(-1); 14.} 15.else if (pid == 0) //pid == 0和下面的else都会被执行到(一个是在父进程中即pid ==0的情况,一个是在子进程中,即pid不等于0) 16.{ 17./* child process */ 18.printf("This is Child Process! "); 19.} 20.else 21.{ 22./* parent process */ 23.printf("This is Parent Process! "); 24./* parent will wait for the child to complete*/ 25.wait(NULL); 26.printf("Child Complete! "); 27.} 28.} -
过程
- dup_thread复制父进程的PCB
- copy_process修改复制的PCB以适应子进程的特点,也就是子进程的初始化
- 分配一个新的内核堆栈(用于存放子进程数据)
- 内核堆栈的一部分也要从父进程中拷贝
- 根据拷贝的内核堆栈情况设置eip,esp寄存器的值
-
说明(子进程获得CPU之后从哪一条代码开始执行?)
-
这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
1.*childregs = *current_pt_regs(); //复制内核堆栈,并不是全部,只是regs结构体(内核堆栈栈底的程序) 2.childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因! 3. 4.p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 5.p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址,也就是说返回的就是子进程的空间了
-
-
-
进程切换
-
schedule()函数选择一个新的进程来运行,下图就是选择函数
-

-
下一步通过context_switch完成进程上下文切换
-

-
switch_to完成寄存器的切换:先保存当前进程的寄存器,再进行堆栈切换(下图第44、45行)自此后所有的压栈都是在新进程的堆栈中了,再切换eip(下图46、56行),这样当前进程可以从新进程中恢复,还有其他必要的切换
-
next_ip一般是$1f(对于新创建的进程来说就是ret_from_fork)
-
49行jmp __switch_to是函数调用,通过寄存器传递参数;函数执行结束return的时候从下一条指令开始(也就是认为是新进程的开始)
-

-
51行,next进程曾经是prev进程(即:对于之前提到的next而言,它执行完后执行的“下一个”其实是刚刚被切换的进程)
1.31#define switch_to(prev, next, last) 2.32do { 3.33 /* 4.34 * Context-switching clobbers all registers, so we clobber 5.35 * them explicitly, via unused output variables. 6.36 * (EAX and EBP is not listed because EBP is saved/restored 7.37 * explicitly for wchan access and EAX is the return value of 8.38 * __switch_to()) 9.39 */ 10.40 unsigned long ebx, ecx, edx, esi, edi; 11.41 12.42 asm volatile("pushfl " /* save flags */ 13.43 "pushl %%ebp " /* save EBP */ 14.44 "movl %%esp,%[prev_sp] " /* save ESP */ 15.45 "movl %[next_sp],%%esp " /* restore ESP */ 16.46 "movl $1f,%[prev_ip] " /* save EIP */ 17.47 "pushl %[next_ip] " /* restore EIP */ 18.48 __switch_canary 19.49 "jmp __switch_to " /* regparm call */ 20.50 "1: " 21.51 "popl %%ebp " /* restore EBP */ 22.52 "popfl " /* restore flags */ 23.53 24.54 /* output parameters */ 25.55 : [prev_sp] "=m" (prev->thread.sp), 26.56 [prev_ip] "=m" (prev->thread.ip), 27.57 "=a" (last), 28.58 29.59 /* clobbered output registers: */ 30.60 "=b" (ebx), "=c" (ecx), "=d" (edx), 31.61 "=S" (esi), "=D" (edi) 32.62 33.63 __switch_canary_oparam 34.64 35.65 /* input parameters: */ 36.66 : [next_sp] "m" (next->thread.sp), 37.67 [next_ip] "m" (next->thread.ip), 38.68 39.69 /* regparm parameters for __switch_to(): */ 40.70 [prev] "a" (prev), 41.71 [next] "d" (next) 42.72 43.73 __switch_canary_iparam 44.74 45.75 : /* reloaded segment registers */ 46.76 "memory"); 47.77} while (0)
-
7.系统执行时可执行程序的装载
-
可执行程序的执行环境
-
一般我们执行一个程序的Shell环境,我们的实验直接使用execve系统调用。
-
Shell本身不限制命令行参数的个数,命令行参数的个数受限于命令自身
- 例如,int main(int argc, char *argv[])
- 又如, int main(int argc, char *argv[], char *envp[])//envp是shell的执行环境
-
Shell会调用execve将命令行参数和环境参数传递给可执行程序的main函数
- int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
-
例子:
1.#include <stdio.h> 2.#include <stdlib.h> 3.#include <unistd.h> 4.int main(int argc, char * argv[])//这里不是完整的命令函数,没有写命令行参数 5.{ 6. int pid; 7. /* fork another process *///避免原有的shell程序被覆盖掉 8. pid = fork(); 9. if (pid<0) 10. { 11. /* error occurred */ 12. fprintf(stderr,"Fork Failed!"); 13. exit(-1); 14. } 15. else if (pid==0) 16. { 17. /* child process */ 18. execlp("/bin/ls","ls",NULL);//以ls命令为例 19. } 20. else 21. { 22. /* parent process */ 23. /* parent will wait for the child to complete*/ 24. wait(NULL); 25. printf("Child Complete!"); 26. exit(0); 27. } 28.}
-
-
命令行参数和环境串都放在用户态堆栈中
- fork子进程的时候完全复制了父进程;调用exec的时候,要加载的可执行程序把原来的进程环境覆盖掉,用户态堆栈也被清空
- 命令行参数和环境变量进入新程序的堆栈:把环境变量和命令行参数压栈(如上图),也就相当于main函数启动
- shell程序-->execve-->sys_execve,然后在初始化新程序堆栈的时候拷贝进去
- 先传递函数调用参数,再传递系统调用参数
-
动态链接分为可执行程序装载时动态链接和运行时动态链接(大部分使用前者);
-
举例1(共享库的动态链接)
-
准备.so文件(在Linux下动态链接文件格式,在Windows中是.dll)
#ifndef _SH_LIB_EXAMPLE_H_ #define _SH_LIB_EXAMPLE_H_ #define SUCCESS 0 #define FAILURE (-1) #ifdef __cplusplus extern "C" { #endif /* * Shared Lib API Example * input : none * output : none * return : SUCCESS(0)/FAILURE(-1) * */ int SharedLibApi();//内容只有一个函数头定义 #ifdef __cplusplus } #endif #endif /* _SH_LIB_EXAMPLE_H_ */ /*------------------------------------------------------*/ #include <stdio.h> #include "shlibexample.h" int SharedLibApi() { printf("This is a shared libary! "); return SUCCESS; }/* _SH_LIB_EXAMPLE_C_ */ -
编译成.so文件
$ gcc -shared shlibexample.c -o libshlibexample.so -m32
-
-
举例2(动态加载库)(与上面的方式一样)
#ifndef _DL_LIB_EXAMPLE_H_ #define _DL_LIB_EXAMPLE_H_ #ifdef __cplusplus extern "C" { #endif /* * Dynamical Loading Lib API Example * input : none * output : none * return : SUCCESS(0)/FAILURE(-1) * */ int DynamicalLoadingLibApi(); #ifdef __cplusplus } #endif #endif /* _DL_LIB_EXAMPLE_H_ */ /*------------------------------------------------------*/ #include <stdio.h> #include "dllibexample.h" #define SUCCESS 0 #define FAILURE (-1) /* * Dynamical Loading Lib API Example * input : none * output : none * return : SUCCESS(0)/FAILURE(-1) * */ int DynamicalLoadingLibApi() { printf("This is a Dynamical Loading libary! "); return SUCCESS; } -
比较
#include <stdio.h> #include "shlibexample.h" //只include了共享库 #include <dlfcn.h> /* * Main program * input : none * output : none * return : SUCCESS(0)/FAILURE(-1) * */ int main() { printf("This is a Main program! "); /* Use Shared Lib */ printf("Calling SharedLibApi() function of libshlibexample.so! "); SharedLibApi();//可以直接调用,因为include了这个库的接口 /* Use Dynamical Loading Lib */ void * handle = dlopen("libdllibexample.so",RTLD_NOW);//先打开动态加载库 if(handle == NULL) { printf("Open Lib libdllibexample.so Error:%s ",dlerror()); return FAILURE; } int (*func)(void); char * error; func = dlsym(handle,"DynamicalLoadingLibApi"); if((error = dlerror()) != NULL) { printf("DynamicalLoadingLibApi not found:%s ",error); return FAILURE; } printf("Calling DynamicalLoadingLibApi() function of libdllibexample.so! "); func(); dlclose(handle);//与dlopen函数配合,用于卸载链接库 return SUCCESS; }-
解释
- dlopen函数参考http://baike.baidu.com/link?url=05ftxNgbVsyrGNLqJbo3TpCyn27QeKOKaU7D70O-3bMu9ZsvruBZIHBZz-mhJgviNf4obS5HBNlpMPzcrbABZK的说明,负责打开一个动态库并将其加载到内存;
- dlsym函数与上面的dlopen函数配合使用,通过dlopen函数返回的动态库句柄(由dlopen打开动态链接库后返回的指针handle)以及对应的符号返回符号对应的指针
-
编译
1.$ gcc main.c -o main -L/path/to/your/dir -lshlibexample -ldl -m32 #这里只提供shlibexample的-L(库对应的接口头文件所在目录,也就是path to your dir)和-l(库名,如libshlibexample.so去掉lib和.so的部分),并没有提供dllibexample的相关信息,只是指明了-ldl 2.$ export LD_LIBRARY_PATH=$PWD #将当前目录加入默认路径,否则main找不到依赖的库文件,当然也可以将库文件copy到默认路径下。 3.$ ./main 4.This is a Main program! 5.Calling SharedLibApi() function of libshlibexample.so! 6.This is a shared libary! 7.Calling DynamicalLoadingLibApi() function of libdllibexample.so! 8.This is a Dynamical Loading libary!
-
SECTION 2 测验题回顾
1.计算机工作模式
32位x86的Linux系统中,函数调用约定使用__stdcall方式, 调用f(x,y,z)时,需要把参数压栈,首先压入的参数是x,y,z中的哪一个?
分析:【根据堆栈变化图可以看出,在压栈的时候是逆序压栈的,所以最先压入的是z】
32位x86 计算机中,cs: eip总是指向地址连续的下一条指令
分析:【顺序执行总是指向地址连续的下一条指令,有分支/跳转时不是】
2.构造简单的Linux操作系统MenuOS
Linux 启动中的第一个用户态进程是idle进程,即0号进程。
分析:【第一个用户态进程是init,即1号进程】
Linux源码start_kernel函数中调用进程调度初始化的是哪个函数?
1.trap_init
2.mm_init
3.sched_init
4.rest_init
分析:【调用的是3.sched_init】
3.关于操作系统“三层皮”
Linux中,用户态切换到内核态时,int指令不会保存下面哪项?
1.用户态堆栈顶地址
2.当时的状态字
3.当时的cs:eip值
4.当时的中断向量
分析:【int指令不会保存当时的中断向量(因为软中断对应的中断向量号是0x80,系统直接调用对应的“中断处理程序”,没必要保存这个值)】
针对API xyz, Linux中系统调用的三层皮指的是不包括哪一项
1.API xyz
2.中断向量system_call
3.中断服务程序sys_xyz
4.中断返回程序ret_from_sys_call
分析:【不包括4.中断返回程序】
Linux中,()将API xyz和中断服务程序sys_xyz关联起来。
分析:系统调用号
使用gdb调试MenuOS的time命令时,希望在time系统调用的内核处理函数处停下来,可以使用b time设定断点。
分析:无法在系统调用处设置断点
32位x86 Linux系统中系统调用处理过程的最后一条汇编指令( )
分析:【iret】
4.进程的描述和创建
Linux中,PCB task_struct中不包含哪个信息()?
进程状态
进程打开的文件
进程优先级信息
进程包含的线程列表信息
分析:【不包括4.线程列表。因为对于Linux系统来说,进程和线程是一样的。】
Linux中,1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先。
分析:【是正确的。0号进程是所有进程的祖先,因此也是所有内核线程的祖先。】
5.可执行程序装载
运行时动态装载链接至少需要用到以下哪些函数()
1.dlopen
2.dlclose
3.dlsym
4.dlload
分析:【至少要用到dlopen和dlsym两个函数】
一般系统调用库函数API的参数传递过程,比如execve系统调用,先进行函数调用参数传递,然后系统调用参数传递,最后又进行函数调用参数传递。
分析:正确的
execve执行静态链接程序时,通过修改内核堆栈中保存的()的值作为新进程的起点。
分析:【eip】
6.进程的切换和系统的一般执行过程
Linux进程调度基于分时和优先级
分析:正确
内核可以看做是各种中断处理过程和内核线程的集合
分析:正确
SECTION 3 实践&虚拟机操作
1.嵌入式汇编代码编写&系统调用练习
- 概述:
- 主要集中在第二周和第四周的实验中,首先是对嵌入式汇编的理解和练习,然后在此基础上完成C语言调用系统调用和嵌入式汇编调用系统调用的等价操作。
- 步骤:
- 练习嵌入式汇编:
-

-

-
解释
- movl $0,%%eax :第一个%表示转义字符
- addl %1,%%eax :%1也是特殊符号,表示output与input(即下方:之后的部分)变量依次编号后,按照0,1,2,...的号码取变量
- :"c"(val1),"d"(val2):也就是将val1的值放到ecx这个寄存器中,系统就会在编译之前自动完成这些工作。这样addl %1,%%eax 就会把ecx的值放到eax中
- addl %%eax,%0 :把eax的值放到m(内存变量)中
-
- 加入系统调用
-

-
-

-
-
- 练习嵌入式汇编:
2.简单的Linux内核MenuOS启动&基础操作
-
概述:
- 简单的启动内核操作从第三周的实验开始,一直贯穿后续的学习过程。本模块主要涉及内核的启动和分析,以及一些基础的操作
-
步骤
-
进入环境,启动内核
-
-
启动gdb调试内核
-
-
增加新的命令(以time和time_asm为例)
-
首先,强制(即 -rf命令)删除当前的menu;
-
克隆一个新的menu:
git clone https://github.com/mengning/menu.git -
进入test.c代码,加入time和time_asm函数;
-
在main函数中加入如下语句:
menuconfig("time","Show system Time",Time); menuconfig("time-asm","Show system Time",Time(asm)); -
进入menu之后,输入make rootfs,就可以自动编译
-
输入help,可以发现系统支持更多的命令:
- help
- version
- quit
- time
- time-asm
-
-
-
理解:关于makefile代码与自动编译
1 # 2 # Makefile for Menu Program 3 # 4 //1.以下类似于变量声明,就是将右侧的变量在代码中用左侧替代 5 CC_PTHREAD_FLAGS = -lpthread 6 CC_FLAGS = -c 7 CC_OUTPUT_FLAGS = -o 8 CC = gcc //2.CC 是一个全局变量,它指定你的Makefile所用的编译器,一般默认是gcc 9 RM = rm 10 RM_FLAGS = -f 11 12 TARGET = test 13 OBJS= linktable.o menu.o test.o //3.Define a macro for the object files;.o文件是unix下的中间代码目标文件 14 15 all: $(OBJS) 16 $(CC) $(CC_OUTPUT_FLAGS) $(TARGET) $(OBJS) //4.即 gcc -o XXX 17 rootfs: //5.挂载根文件系统(root files system),见下方解释 18 gcc -o init linktable.c menu.c test.c -m32 -static -lpthread //该句以下是编译顺序 19 gcc -o hello hello.c -m32 -static 20 find init hello | cpio -o -Hnewc |gzip -9 > ../rootfs.img 21 qemu -kernel ../linux-3.18.6/arch/x86/boot/bzImage -initrd ../rootfs.img 22 .c.o: 23 $(CC) $(CC_FLAGS) $< 24 25 clean: 26 $(RM) $(RM_FLAGS) $(OBJS) $(TARGET) *.bak-
参考:
-
分析:
-
makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
-
此外,在不同的系统中启动内核的起点有着不同的定义。在实际操作的kali虚拟机中,第21行即可更改为:
qemu-system-x86-64 -kernel 4.3.0-kali-amd64 -initrd ../rootfs.img//kali是64位虚拟机
-
-




SECTION 4 xmind思维导图
SECTION 5 总结&反思
一共八周的课程已经结束,对于Linux系统的“巡幽探秘”所获得的“地图”需要用一定的心思进行梳理和总结,升华出来一个不辜负这两个月学习的思维脉络。
- 计算机操作系统的普适法则
- 在之前学习“深入理解计算机系统”的时候,我对于那些有着哲学痕迹的计算机运行原则已经有了模糊的概念和感触,只不过在Linux系统的实践中获得了更深刻的印证:最基础的冯 诺依曼体系结构是十分简单的,就像解剖学中人的主要骨干一样简洁;忙忙碌碌、简简单单的,受二进制可执行代码驱使的寻址系统兢兢业业地搬运代码、数据或者其它们并不“知晓”也不用“了解”的东西……一层层垒起来的模块就像筋脉、血肉、神经节等等托起来了系统的大脑:CPU,不过,归结起来,它也是基础的神经元、肌肉和血脉的集合罢了。
- Linux系统的特殊魅力
- “萝卜白菜,各有所爱”;打包所有功能出售给lv.0小白用户的Windows系统自有其流行之道,而“只做一件事,就做到最好”的程序思维集大成者的Linux更有乐趣一点;
- 在后期的学习中,常常需要追踪内核相关的代码或者是调试一些test程序,在gdb里面窥见诸如进程切换这样系统比较原始的功能代码的时候往往很开心地发现“似曾相识”,在《数据结构》这样基本的课程中讲过的swap函数就与此异曲同工——“天下大事必作于细”,it is true.
- 个人的收获与遗憾
- 收获:
- Linux系统的内核构造方法以及调试方法
- Linux系统的进程切换分析
- 操作系统的基础:寻址方式
- 遗憾:
- 最大的遗憾是动手实践不够理想,因为个人原因没能够对内核做更深研究
- 收获: