篡改图像检测发展-深度学习篇
要了解图像篡改检测,我们首先需要了解何谓“图像篡改”。篡改在英文文献中常用manipulation、tamper、forgery这三个词表达。广义上的图像篡改指的是对原始图像做了改动的操作,这种改动操可以是:图像格式转换、高斯模糊、接缝剪裁(seam carving)、利用GAN网络改动等等。
目前对于图像篡改的分类还处于较混乱的状态,类别五花八门,分类标准不统一,各个类别也有包含、相交的关系。随着新的图像处理技术的出现,图像篡改方法也会增加。在MFC竞赛(Media Forensics Challenge)中,对于图像篡改的类别划分就有70余种,并且每年的类别划分也有变动。
尽管图像篡改类别繁杂,但可以粗略划分为manipulation和tamper两类(按英文直译,manipulation是操作的意思,此类篡改有点类似仅对图像做非内容性的处理,而tamper按直译,则是对图像做了内容性的处理):
-
Manipulation:中值滤波处理(Median Filtering)、高斯模糊处理(Gaussian Blurring)、添加高斯白噪声(Additive White Gaussian Noise)、重采样(Resampling)、JPEG 压缩(JPEG Compression)等。
-
Tamper :删除(Removal)、添加(Adding)、复制(Copy)、截取(Splicing)等。
篡改检测问题实际上就是要检测出图像当中做过改动的区域来。近几年,学术上更趋于集中研究splicing、copy-move、removal这三个类型图像篡改的检测问题。
-
A deep learning approach to detection of splicing and copy-move forgeries in images [3]
这篇论文是2016年发表在WIFS,关于深度学习模型数字图像篡改的开山之作。

文章提出了一种基于深度学习技术的伪造图像伪造检测方法,该方法包含10层卷积层,其中第一层为SRM富模型(spatial rich model)[4] 预处理层,有助于加快网络收敛;输出使用SVM二分类;中间层卷积核多为3x3。
早年算法,整体来看比较中规中矩,只能做到检测是否篡改(Detection ),无法做到定位(Localization ),同时使用的是CASIA v1.0、CASIA v2.0、Columbia gray DVMM 这三个数据库完成实验。
-
Detection and Localization of Image Forgeries using Resampling Features and Deep Learning [5]
这篇文章是2017年发表在CVPR Workshop,使用重采样算法实现篡改检测的算法。

算法主要包含2个步骤,第一,通过重叠的图像块计算重采样随机特征;第二,使用深度学习分类器和高斯条件随机场模型来创建热力图,从而定位篡改区域。算法先将图像块重叠堆放,然后使用CNN特诊提取,接着建立统计学模型,根据统计直方分布,分析篡改小块的位置。
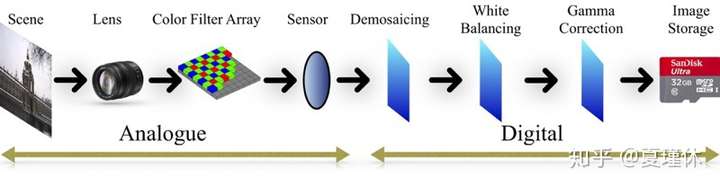
上图显示了数字图像成像过程,其中成像过程需要经历:模拟信号处理、数字信号处理,其中模拟信号处理包含镜头偏移、CFA插值等;数字信号处理包含了去马赛克、伽马矫正、重采样等等,而不同的图像的重采样程度是不同的,经过篡改必然导致篡改部位重采样率的差异,文章的算法正是源于这个原理。
-
Tampering Detection and Localization through Clustering of Camera-Based CNN Features[6]
这篇文章也是发表在CVPR Workshop的基于CNN篡改检测、定位的文章。
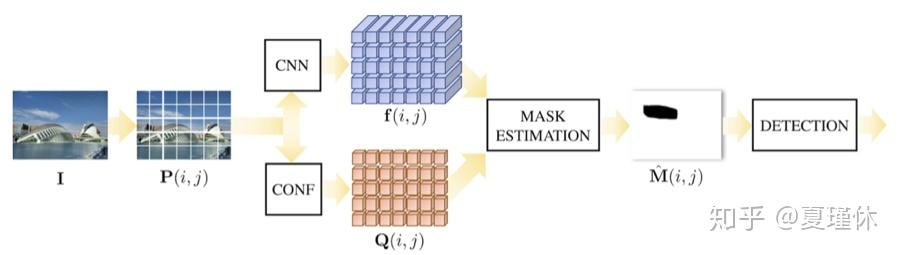
文章提出了一种图像篡改检测和定位算法,利用不同相机模型留在图像上的特征足迹,最直接的原理即是检测图像的拍摄相机来源,由于不同型号相机拍摄的照片所携带的模式噪声不一样,以此鉴定图像是否篡改、篡改定位。
这篇文章是作者 Bondi 在2016年发表[7]的工作的延续,[7]通过建立CNN+SVM模型,鉴定数字图像拍摄来源,但是存在一定的缺陷,即是相同型号相机生成的图像篡改无法被检测出来。算法的基本模型考虑到了两层因数:第一,CNN检测到的部位是否被篡改(即f(i, j));第二,我们知道纹理度低的部位的篡改明显存在误差,因此,作者根据纹理度计算公式对每个图像小块计算置信度因子(即Q(i, j)),其中Q(i, j)定义为:

最后将两个计算结果合成后得到篡改部位的置信度热力图,1.CNN输出f做K-means聚类;2.对检测散点图做密度去噪(检测最小篡改粒度为128x128);3.并使用纹理度去噪(不计算纹理度低的检测结果);4.最终使用平均篡改率(篡改点÷所有测点)阈值判定输入图像是否为篡改图像,得到最终的结果:

算法使用Dresden图像库,该数据集由来自26种不同相机模型的超过16k图像组成,描绘了总共83个场景,关于篡改图像如何制作,本文作者没有解释。这篇文章做得相对完整,从图像切片(patches)->CNN特征提取/Q纹理度换算置信度->整合块热力图->除噪,每个步骤都很扎实。
-
Deep Matching and Validation Network: An End-to-End Solution to Constrained Image Splicing Localization and Detection [9]
文章发表在2017 ACM on Multimedia Conference,作者代码在Gitlab: https://gitlab.com/rex-yue-wu/Deep-Matching-Validation-Network

文章考虑的主要问题是限制性的图像篡改检测问题(constrained image splicing detection (CISD) problem),即问题提供查询图像Q和潜在篡改来源图像P,需要从图像Q中检测是否有物体来源于图像P,问题更倾向于Copy-Move篡改模型。文章提出一种深度匹配网络(Deep Matching and Verification Network (DMVN)),扩展了底层拼接问题的公式,以考虑两个输入图像,一个查询图像Q和一个潜在的供体图像P。
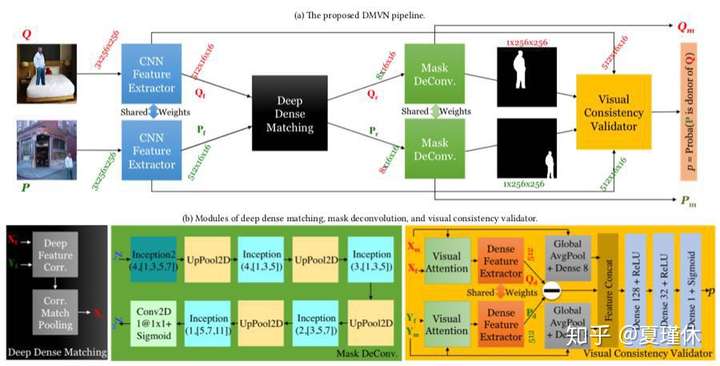
文章提到创新点为:(1) 相比传统算法,DMVN是一种端到端(End-to-End)模型;(2) 相比其他深度学习算法,DMVN不仅特征提取自动,而且后处理也是非干预;(3) 创新地提出深度学习模块(Deep Dense Matching和Visual Consistency Validator),用于执行视觉匹配和验证。
仔细地看了下论文,算法主要包含以下流程(1) CNN Feature Extractor:使用的是VGG-16;(2) Deep Dense Matching:使用的是inception-based Mask Deconvolution模块,来源于[10];(3) Visual Consistency Validator:用于强制模型聚焦于两个图像中的分割区域,将两个Mask快融合起来。总体看来,是将多个深度学习网络拼接起来。
-
Image Splicing Detection via Camera Response Function Analysis[11]
文章发表在2017 CVPR上面,主要采用相机响应函数(Camera Response Function, CRF)分析篡改部位的轮廓直方图差异,并以此鉴定Copy-Move和Splicing篡改。非线性CRF对于图像处理有很大作用,很多图像去燥算法有所使用,实验表明篡改区域的CRF值比起未篡改区域有所不同。虽然目前的研究未知CRF如何成为模糊估计中的噪声源,但是文章证明CRF是一个关键信号,有助于区分不同的边缘和伪造的拼接边界。
参考文献
5. Reference
- [1] 朱叶. 数字图像复制—粘贴篡改盲取证关键技术研究[D]. 吉林大学, 2017.
- [2] Qian, Y., Dong, J., Wang, W., & Tan, T. (2015, March). Deep learning for steganalysis via convolutional neural networks. In Media Watermarking, Security, and Forensics 2015 (Vol. 9409, p. 94090J). International Society for Optics and Photonics.
- [3] Rao, Y., & Ni, J. (2016, December). A deep learning approach to detection of splicing and copy-move forgeries in images. In Information Forensics and Security (WIFS), 2016 IEEE International Workshop on (pp. 1-6). IEEE.
- [4] J. Fridrich, and J. Kodovsky ́, “Rich models for steganalysis of digital images,” IEEE Transactions on Information Forensics and Security, vol. 7, no. 3, pp. 868-882, June 2012.
- [5] Bunk, J., Bappy, J. H., Mohammed, T. M., Nataraj, L., Flenner, A., Manjunath, B. S., ... & Peterson, L. (2017, July). Detection and localization of image forgeries using resampling features and deep learning. In Computer Vision and Pattern Recognition Workshops (CVPRW), 2017 IEEE Conference on(pp. 1881-1889). IEEE.
- [6] Bondi, L., Lameri, S., Guera, D., Bestagini, P., Delp, E. J., & Tubaro, S. (2017, July). Tampering Detection and Localization Through Clustering of Camera-Based CNN Features. In CVPR Workshops (pp. 1855-1864).
- [7] Bondi, L., Baroffio, L., Güera, D., Bestagini, P., Delp, E. J., & Tubaro, S. (2017). First steps toward camera model identification with convolutional neural networks. IEEE Signal Processing Letters, 24(3), 259-263.
- [8] Güera, D., Yarlagadda, S. K., Bestagini, P., Zhu, F., Tubaro, S., & Delp, E. J. (2018). Reliability Map Estimation For CNN-Based Camera Model Attribution. *arXiv preprint arXiv:1805.01946.
- [9] Wu, Y., Abd-Almageed, W., & Natarajan, P. (2017, October). Deep matching and validation network: An end-to-end solution to constrained image splicing localization and detection. In Proceedings of the 2017 ACM on Multimedia Conference (pp. 1480-1502). ACM.
- [11] Chen, Can, Scott McCloskey, and Jingyi Yu. "Image Splicing Detection via Camera Response Function Analysis." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.