一. 在c中分为这几个存储区
1.栈 - 由编译器自动分配释放
2.堆 - 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收
3.全局区(静态区),全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。- 程序结束释放
4.另外还有一个专门放常量的地方。- 程序结束释放
在函数体中定义的变量通常是在栈上,用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上。在所有函数体外定义的是全局量,加了static修饰符后不管在哪里都存放在全局区(静态区),在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。另外,函数中的"adgfdf"这样的字符串存放在常量区。比如:
二.在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区
1.栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
2.堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3.自由存储区,就是那些由malloc等分配的内存块,它和堆是十分相似的,不过它是用free来结束自己的生命的。
4.全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
5.常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)
以上引自http://www.cnblogs.com/JCSU/articles/1051579.html
三、堆和栈的理论知识
申请方式
stack: 由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap: 需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
三。
VC++ 6.0 编译器编译期存储器分配模型 (内存布局)
VC ++ 6.0 编译器编译期存储器分配模型(内存布局)
----转载自网络
一、内存区域的划分
一个由C/C++编译的程序占用的内存分为以下几个部分:
1)、栈区(Stack):由编译器(Compiler)自动分配释放,存放函数的参数值,局部变的值等。其操作方式类似于数据结构中的栈。
2)、堆区(Heap ):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配
方式倒是类似于链表。
3)、全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全
局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。
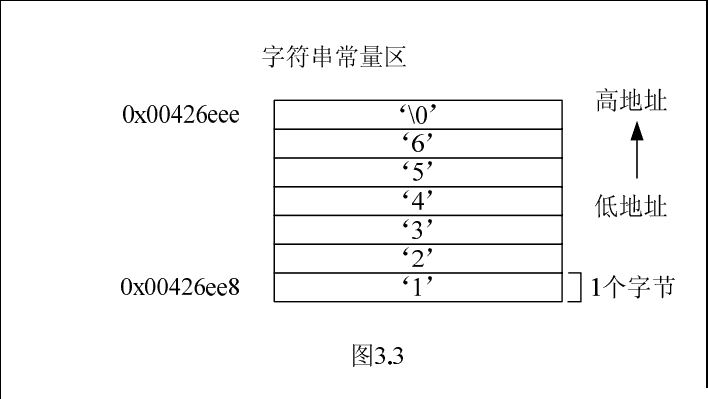
4)、文字常量区:常量字符串就是放在这里的。程序结束后由系统释放。
5)、程序代码区:存放函数体的二进制代码。
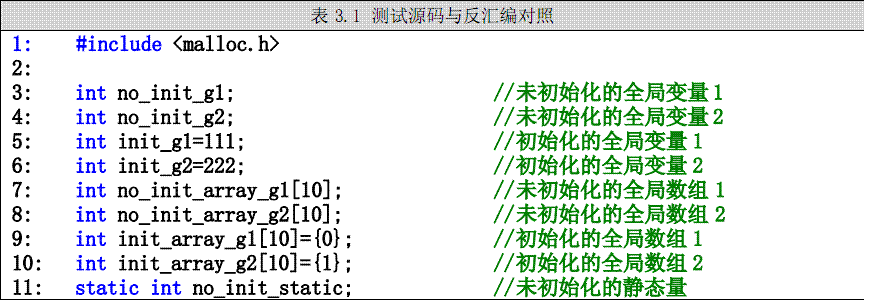
二、测试案例(源码与反汇编对照)
2.1 测试案例源码与反汇编对照
为了能够形象地说明内存布局模型,先来看一段Win32 Console Application代码(表3.1),其中,加粗文字(行最左端为行标号)
为C源代码,未加粗文字(行最左端为地址)为反汇编后的指令代码。看上去比较零乱,不过一定要耐住性子,后面的文字将基于此。

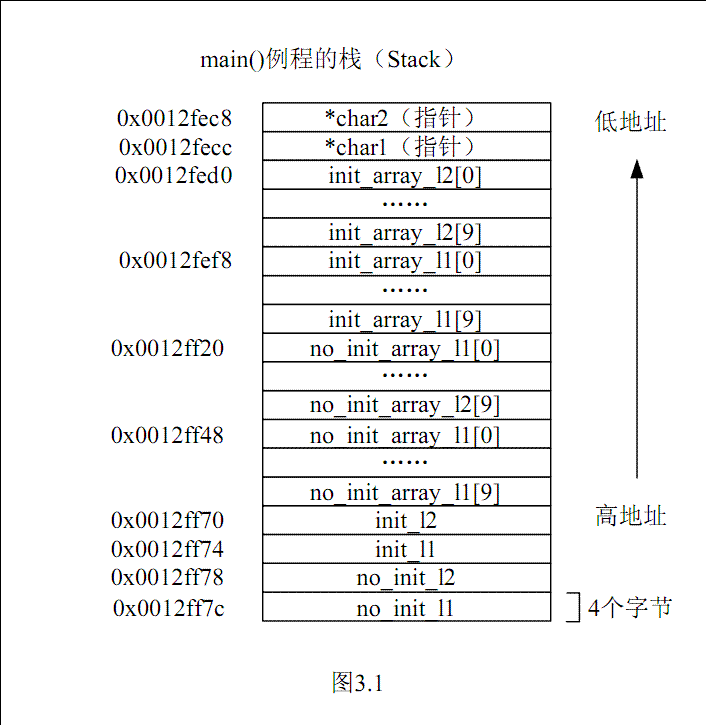
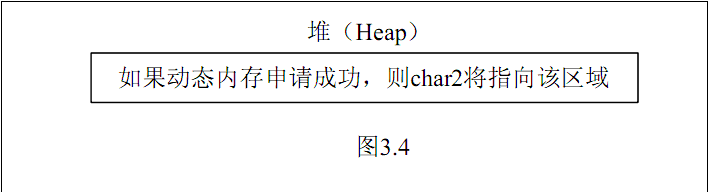
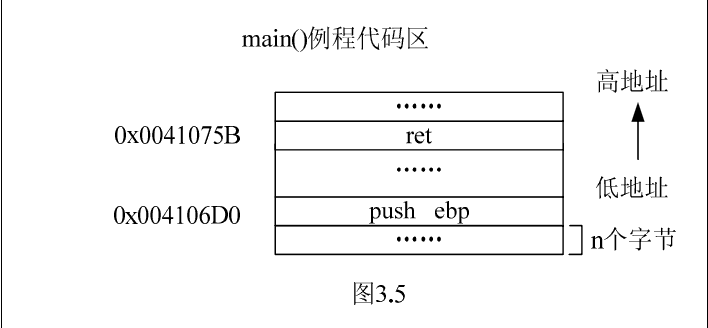
3.2 内存布局图
对于该案例,以下几幅图形象地说明了第2节提到的内存5大区域。需要注意的是,图中各区域的起始地址不是绝对的,不同的编译环境可能不完全相同,这里给出的只是一个典型示例。需要注意的是,不同区域地址编址方向也不同。


3、应用
通过对第3节案例的理解,我们将对一些现象予以解释。
3.1、变量初始化
1)局部变量将被分配在栈中,如果不初始化,则为不可预料值。编译时,编译器将抛出一个编号为C4700警告错误(local variable '变量名' used without having been initialized)。
表4.1代码测试了局部变量未初始化的情况。
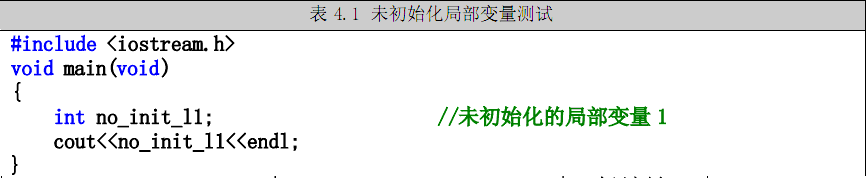
该测试的一个典型的输出结果为:-858993460,同时,编译时编译器抛出了一条警告错误。
2)全局变量如果不初始化,则默认为0,编译时编译器不提示“变量未初始化”。
表4.2代码测试了全局变量未初始化的情况。

该测试的输出结果为:0.
3)全局变量初始化为0与不初始化效果一样。请留意表3.1第9行代码,即
intinit_array_g1[10]={0}; //初始化的全局数组1
等效于:
int init_array_g1[10]; //初始化的全局数组1
当然,出于谨慎,我们还是建议在使用全局变量前对其初始化。
3.2 变量初始化对代码空间的影响
本小节任然讨论变量初始化问题,但出于重视,我们将其独立成小节。现在看两个测试案例。
案例1:建立Win32 Console Application工程,工程名:Test1,代码如表4.3。

编译成Debug版本,察看Debug目录下的Test1.exe可执行文件大小,典型大小约184KB(约0.18MB)。
案例2:建立Win32 Console Application工程,工程名:Test2,代码如表4.4。

编译成Debug版本,察看Debug目录下的Test2.exe可执行文件大小,典型大小约46MB。
两个案例唯一区别不过在于是用0还是1初始化 init_array_g1[]数组第0个元素。生成的可执行文件大小却天壤之别。
上面已经说过,对于全局变量初始化为0与不初始化效果一样。因此,这里的Test1案例并没有对全局变量初始化。
那么全局变量初始化于不初始化对代码空间又有什么影响呢?
我们知道,运行于基于冯·诺依曼体系结构系统上的程序,数据和程序是一起存储了。因此,编译时,编译器会将全局变量的初始化数据捆绑到最终生成的程序文件中,而对于未初始化的全局变量只是为其分配(指示)了存储位置,不会将大量的0捆绑到程序中。
现在再来看以上两个案例。Test1实质上没有初始化全局变量,编译时编译器只是为了init_array_g1[]指出了将要使用的内存位置,而不发生 数据绑定。Test2则不同,它将init_array_g1[0]初始化为1,其它元素全部初始化为0,因此,编译器将把 init_array_g1[]数组的10000000个元素的初始化数据全部捆绑到最终的可执行文件中,导致编译后的文件十分庞大。
3.3 关于堆和栈
由于历史原因,我们习惯把堆和栈合在一起称呼(堆栈),然而,在这里我们要严格区分堆和栈的概念。
例程中声明的局部变量被分配在栈中,而栈的大小是相当有限的(一、两个兆),庞大的数组可能使栈不够用,造成运行期栈溢出(Overflow)错误(注意:不是编译器错误),而堆的大小主要取决于系统可用内存和虚存的多少。下面来看几个例子:
案例3代码如表4.5所示:

编译该代码,没有编译期错误。执行时却发生了运行期错误(提示Statck Overflow),因为栈空间不够用。
案例4,把案例3代码改一下,数组定位为全局变量,如表4.6所示:

编译该代码,没有编译期错误,也不发生运行期错误。因为全局变量不是分配在栈中的(注意:也不在堆中),能用多大空间取决于系统可用内存和虚存的多少。
对于案例3的问题还有一种方法可以解决:动态申请内存空间。
动态申请的内存空间是在运行期分配的,一旦申请成功,将分配在堆中,因此,大小也是取决于系统可用内存和虚存的多少。
案例5:把案例3代码用另一种方法改一下,如表4.7所示。
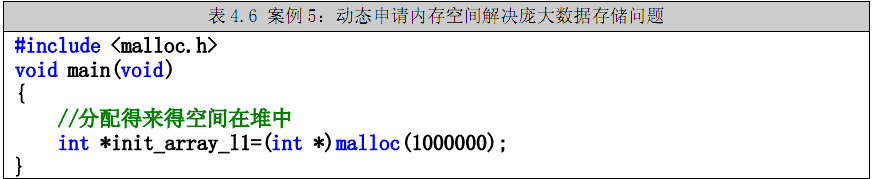
案例5的内存空间在堆中。还有一点不同于案例4:案例4的内存空间是在编译器分配的,而案例5的内存空间是在运行期分配的,有可能分配不到空间。
3.4) 地址递减编制方式
或许其它资料中已经描述了“地址递减”编址方式分配内存的概念,所谓“地址递减“是指编译器编译程序时,按变量声明先后,从可分配内存中从高地址向低地址分配内存。什么意思?还是先来看一个例子。
案例6是一个有逻辑错误的程序(表4.7所示),不妨称其为“变态”程序。那么它是如何BT的呢?

这个程序没有编译器错误,但却是一个死循环程序。我们想知道的是:它为什么是个死循环,而不是其它什么错误?通过以上文字对内存布局的介绍,我们已经可以很容易解释之。
仿照第3节内容可以画出内存布局示意图(如图4.1所示,图中起始地址只是一个典型情况)。
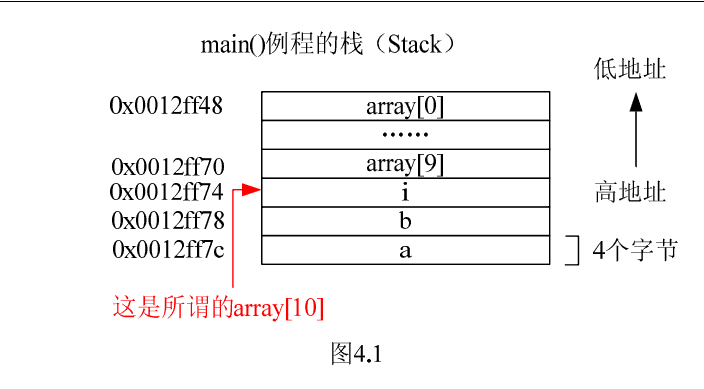
注意,程序中引用了array[10]————数组下标越界(VC++6.0编译器可以检查出显示的下标越界,但是不检查隐式的下标越界)。循环内部会将 所谓的array[10]置1,而从图4.1可知,array[10]实质上就是i,导致程序最终死循环也就理所当然了。
一切变得明朗起来,我们不仅解释了程序中的问题,同时还明白了“地址递减”编址方式并不神秘,它原来就是我们前面提到的栈内存区的编址方式。