了解python编码
资料来源:
https://www.tr0y.wang/2018/09/13/py-coding-type/
各字符编码功能介绍
ASCII码主要是为了处理英文字符
GB2312主要是处理中文字符
unicode主要是为了处理各国字符
UTF-8提高了unicode存储和传输性能,它是unicode的一种表现形式
创造str和unicode
直接创造str和unicode
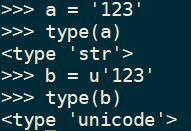
str => unicode,unicode => str
python提供了 decode/encode 用于两者的转换
1)str -> decode('某种编码') -> unicode
2) unicode -> encode('某种编码') -> str
总结:unicode经过编码后形成str,str编码后形成unicode
注:unicode是一种字符集,不属于编码,其它编码是具体实现unicode思想的一种编码,所以str到unicode的转换称为解码,而unicode到str的转换称为编码
环境编码
系统默认编码 1)linux,unix:utf-8 2)windows:gbk2312
编辑器编码
可以自由设置,最好统一为UTF-8
文件头部编码声明
声明编码方式为:# -*- coding: utf-8 -*- 或 #coding=utf-8(今天才知,-*-仅仅是为了好看),utf-8、utf8,python都能识别
注:声明放在第一行,代码中直接声明的字符串编码类型,与头部声明编码方式直接相关,为避免乱码和后续处理,建议统一为utf-8
编码之间的转换
需要用unicode搭桥。str有各种编码的区别,unicode是没有编码的标准形式
python2.x和python3.x的编码方式
python2.x默认使用ascii编码,python3.x默认使用utf-8编码,
python2中,str编码后的结果是bytes,str = bytes, 所以s只能decode
python3.x的编码方式是:
文本总是 Unicode,由 str 类型表示,二进制数据则由 bytes 类型表示。Python 3 不会以任意隐式的方式混用 str 和 bytes
解释:首先,Unicode 是内存编码表示方案(是规范),而 UTF 是如何保存和传输 Unicode 的方案(是实现)。 这也是 UTF 与 Unicode 的区别。py3.X 中只有一种能保存文本信息的数据类型:str,不可变,保存的是 Unicode 码位。Unicode 是离用户更近的数据,bytes 是离计算机更近的数据
变化: str 表示的概念都是字符串类型,只不过 Py2.x 的 str 是经过编码的 unicode,而 py3.x 的 str 就是 unicode。 那么,py3.x 的 unicode 经过编码后,是什么呢?就是 bytes。也就是说,py3.x 的字符串默认是 unicode,至于你想把它怎么编码(utf8 或者 gbk),都是你自己的事。
#python2.x #python3.x 字符串:str类型 字符串:unicode 类型 type("123") :str type("123"): str len("我"):3 len("我"):1 len("我".decode("utf-8")) : 1 len("我".encode()) : 3
python3.x编码示例
a = "我" # a 是一个 字符串,类型是 str,用 unicode 表达 print(a) # '我'
a = b'xe6x88x91' # a 是一个 字节流,类型是 bytes,用 utf8 编码的 unicode 表达 print(a) # b'xe6x88x91' a = "我".encode("utf8") # 将 a 编码,转为用 utf8 编码的 unicode 表达 print(a) # b'xe6x88x91' a = b'xe6x88x91'.decode("utf8") # 将 a 解码,转为用 unicode 表达 print(a) # "我" a = "我".decode("utf8") # 试图将 unicode 解码 # 报错:AttributeError: 'str' object has no attribute 'decode' a = b'xe6x88x91'.encode("utf8") # 试图将 bytes 编码 # 报错:AttributeError: 'bytes' object has no attribute 'encode' a = b'xe6x88x91'.decode("gbk") # 解码的编码类型与原有编码类型不匹配 # 报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0x91 in position 2: incomplete multibyte sequence