一、数据挖掘流程介绍
1.数据读取
-读取数据
-统计指标
-数据规模
2.数据探索(特征理解)
-单特征的分析,诸个变量分析对结果y的影响(x,y的相关性)
-多变量分析(x,y之间的相关性)
-统计绘图
3.数据清洗和预处理
-缺失值填充
-标准化、归一化
-特征工程(筛选有价值的特征)
-分析特征之间的相关性
4.建模
-特征数据的准备和标签
-数据集的切分
-多种模型对比:交叉验证、调参(学习曲线,网格搜索)
-集成算法(提升算法)XGBoost、GBDT、light-GBM、神经网络(多种集成)
二、数据文件说明
本案例所用泰坦尼克号数据存储在文件 train.csv 中,来源于kaggle竞赛
三、Python代码实现
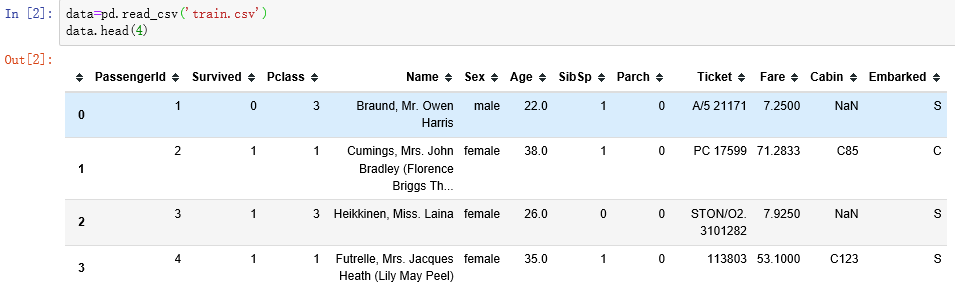
1.数据读取


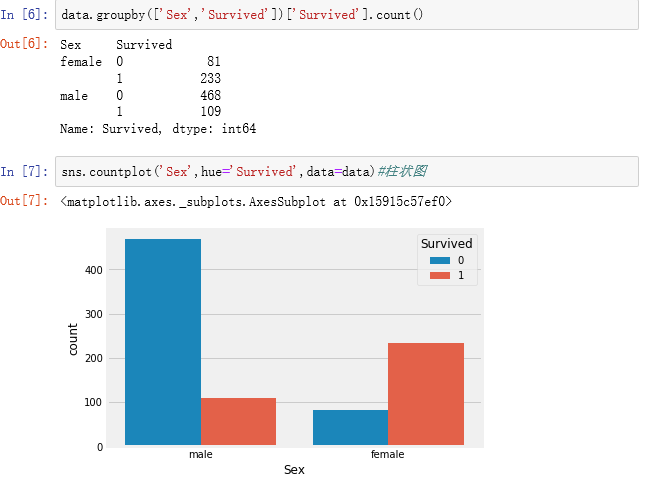
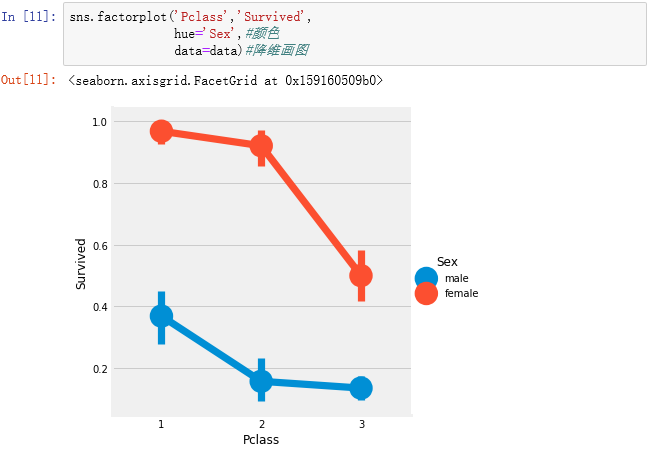
2.数据探索




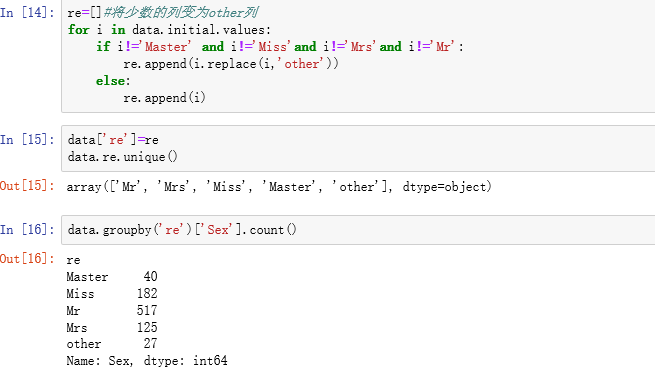
3.数据清洗和预处理


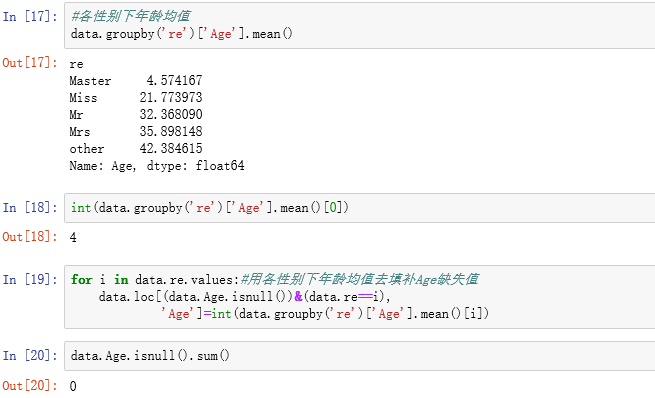
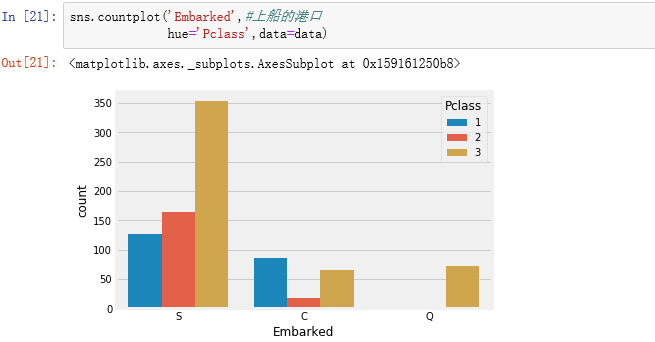


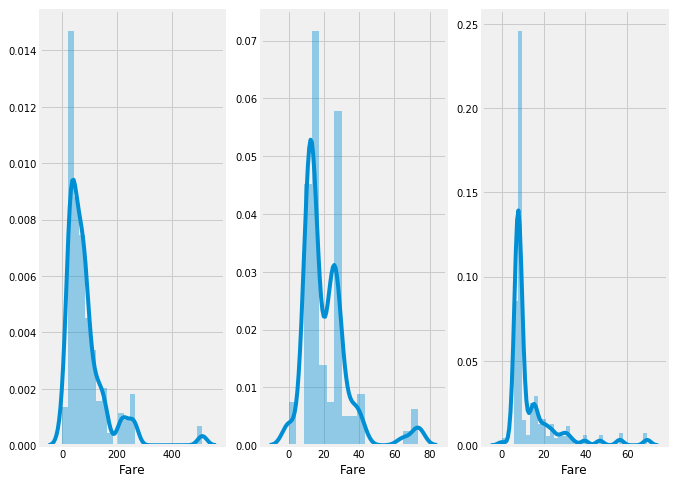

3.3数据处理
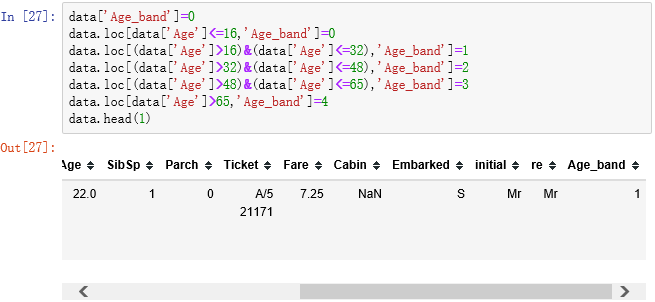




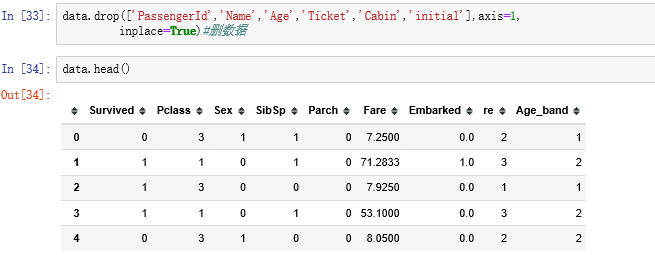
4.建模
- 导包
- 划分数据集




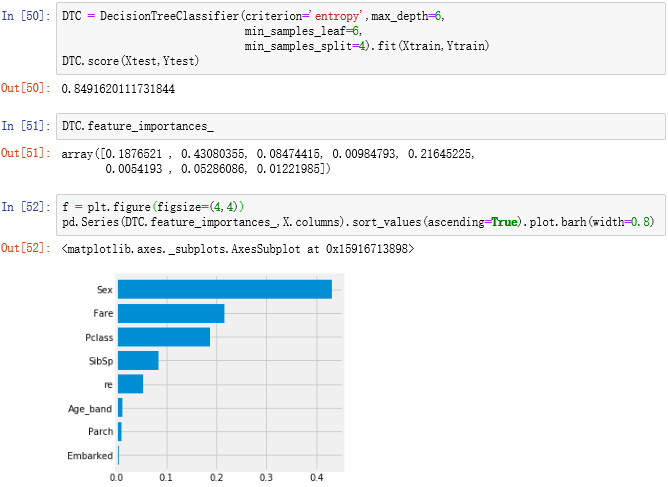
ROC曲线的含义:受试者工作特征曲线
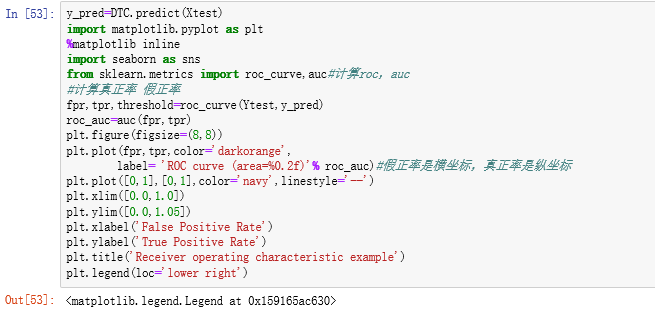
#评价统计量计算
- 1.ROC曲线下的面积值在0.5和1之间。
- 2.在AUC>0.5的情况下,AUC越接近于1,说明效果越好。
- AUC在 0.5~0.7时有较低准确性,
- AUC在0.7~0.9时有一定准确性,
- AUC在0.9以上时有较高准确性。
- 3.AUC小于等于0.5时,说明该方法完全不起作用。
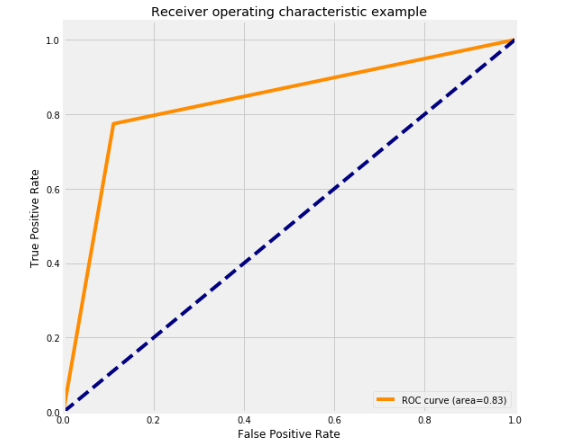
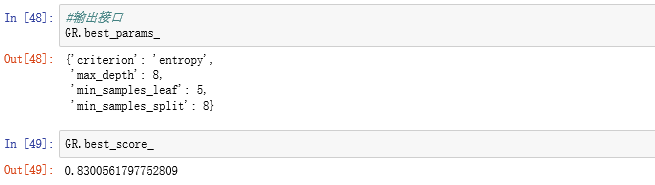
从上图可以看出:AUC值等于0.83,说明效果较好

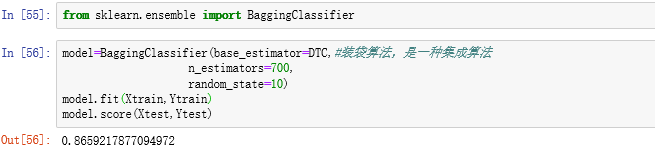
通过比较发现装代法的得分最高,约为0.8659,即使用该方法效果最好。