Sparse Autoencoder稀疏自编码器实验报告
1.Sparse Autoencoder稀疏自编码器实验描述
自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如  。自编码神经网络尝试学习一个
。自编码神经网络尝试学习一个 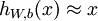 的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出  接近于输入
接近于输入  。当我们为自编码神经网络加入某些限制,比如给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。对施加了稀疏性限制的自编码神经网络进行训练,我们可以提取到到训练样本更高层次上的特征。比如本实验中,对图像进行稀疏自编码后,隐藏层单元可以学习到类似图像边缘的特征,我们可以认为算法学习到了比单纯像素点更高层次的特征。
。当我们为自编码神经网络加入某些限制,比如给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。对施加了稀疏性限制的自编码神经网络进行训练,我们可以提取到到训练样本更高层次上的特征。比如本实验中,对图像进行稀疏自编码后,隐藏层单元可以学习到类似图像边缘的特征,我们可以认为算法学习到了比单纯像素点更高层次的特征。
-
实现流程
Step 1 :产生训练样本集
Step 2 :稀疏自编码的对象:计算成本函数和梯度
Step 3 :梯度检查(若检查结果差距过大,返回step2)
Step 4 :训练稀疏自编码器,更新参数
Step 5 :对隐藏层单元进行可视化
3.每步关键点及代码、注释
Step 1 :产生训练样本集
从10张图片中,每张随机采样1000个大小8x8的像素块,共得到10,000个像素块。对其进行重新排列得到矩阵patches作为实验的样本训练集,patches是64x10,000的矩阵。
同时随机选择204张,显示如下:

这些图像都事先进行了白化whiting处理,减少了各相邻像素点间的关联性。
随机采样的关键实现代码如下:
function patches = sampleIMAGES()
% sampleIMAGES
% Returns 10000 patches for training
%% ---------- YOUR CODE HERE --------------------------------------
for imageNum = 1:10
[rowNum colNum] = size(IMAGES(:,:,imageNum));
% select 1000 patches from every picture
% Here , patch size is 8x8
% randi([iMin,iMax],m,n)
% patches : e.g. 64x10000
% reshape(X,M,N) -> MxN matrix;Here 8x8 ->64x1
for patchNum = 1:1000
xPos = randi([1,rowNum - patchsize + 1]);
yPos = randi([1,colNum - patchsize + 1]);
patches(:,(imageNum - 1)*1000 + patchNum) = ...
reshape(IMAGES(xPos:xPos + patchsize-1,yPos:yPos + patchsize-1,imageNum),64,1);
end
end
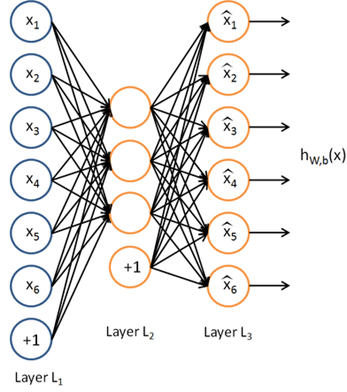
Step 2 :稀疏自编码的对象:计算成本函数和梯度
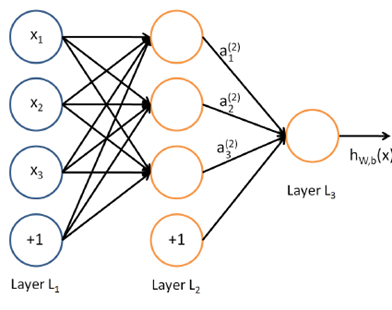
隐藏层单元输出(activation)的表达式如下:
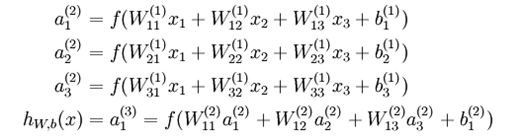
也可以表示为:


矢量化表达式如下

这个步骤称为前向传播forward propagation,更一般的,对神经网络中的l层和l+1层,有:

成本函数由三项构成:

其中

和
 。
。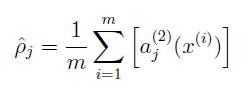 算法通过迭代,尽量使
算法通过迭代,尽量使
用反向传播(Backward propagation)算法计算预测误差,需要用到成本函数的梯度,其表达式如下:

算法调用minFunc()更新参数W,b,以便得到更好的预测模型。
实现矢量化的关键是了解各变量的维度大小,各变量维数大小如下:

关键实现代码如下:
function [cost,grad] = sparseAutoencoderCost(theta, visibleSize, hiddenSize, ...
lambda, sparsityParam, beta, data)
%% ---------- YOUR CODE HERE --------------------------------------
[n,m] = size(data); % m is the number of traning set,n is the num of features
% forward algorithm
% B = repmat(A,M,N) -> replicate and tile an array->MxN
% b1 -> b1 row vector 1xm
z2 = W1*data+repmat(b1,1,m);
a2 = sigmoid(z2);
z3 = W2*a2+repmat(b2,1,m);
a3 = sigmoid(z3);
% compute first part of cost
Jcost = 0.5/m*sum(sum((a3-data).^2));
% compute the weight decay
Jweight = 1/2* lambda*sum(sum(W1.^2)) + 1/2*lambda*sum(sum(W2.^2));
% compute the sparse penalty
% sparsityParam(rho): The desired average activation for the hidden units
% rho(rho^) : the actual average activation of hidden unit
rho = 1/m*sum(a2,2);
Jsparse = beta * sum(sparsityParam.*log(sparsityParam./rho)+...
(1-sparsityParam).*log((1-sparsityParam)./(1-rho)));
% the complete cost function
cost = Jcost + Jweight + Jsparse;
% backward propagation
% compute gradient
d3 = -(data-a3).*sigmoidGradient(z3);
% since we introduce the sparsity term--Jsparse in cost function
extra_term = beta*(-sparsityParam./rho+(1-sparsityParam)./(1-rho));
% add the extra term
d2 = (W2'*d3 + repmat(extra_term,1,m)).*sigmoidGradient(z2);
% compute W1grad
W1grad = 1/m*d2*data' + lambda*W1;
% compute W2grad
W2grad = 1/m*d3*a2'+lambda*W2;
% compute b1grad
b1grad = 1/m*sum(d2,2);
% compute b2grad
b2grad = 1/m*sum(d3,2);
Step 3 :梯度检查(若检查结果差距过大,返回step2)
checkNumericalGradient.m定义了一个简单的二次函数h(x) = x21+ 3x1x2,检查在x = (4, 10)T点处的梯度是否计算正确。帮助我们确认梯度的代码是否正确实现。
梯度的数值近似表达式如下所示:

computeNumericalGradient.m可以帮我们详细检查计算的梯度是否正确。实际得到的梯度与数值计算得到的梯度尽可能接近,在本实验中要小于10 e-9。如果这个差值过大,则应该重新检查算法的实现代码。
梯度的数值近似关键实现代码如下:
function numgrad = computeNumericalGradient(J, theta)
%% ---------- YOUR CODE HERE --------------------------------------
epsilon = 1e-4;
n = size(theta,1);
E = eye(n);
for i = 1:n
delta = E(:,i)*epsilon;
numgrad(i) = (J(theta+delta)-J(theta-delta))/(epsilon*2.0);
end
Step 4 :训练稀疏自编码器,更新参数
在本实验中优化函数常用minFunc,是有Mark Schmidt 编写的一个Matlab优化工具箱,采用Limited-memory BFGS等算法实现最优化。
优化代码如下所示:
% Randomly initialize the parameters
theta = initializeParameters(hiddenSize, visibleSize);
% Use minFunc to minimize the function
% addpath minFunc/
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% sparseAutoencoderCost.m satisfies this.
options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
options.display = 'on';
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, patches), ...
theta, options);
Step 5 :对隐藏层单元进行可视化
最后调用display_network.m,将隐藏层单元可视化,并存到weights.jpg文件中。
W1 = reshape(opttheta(1:hiddenSize*visibleSize), hiddenSize, visibleSize);
display_network(W1', 12);
print -djpeg weights.jpg % save the visualization to a file
实验结果显示的那些权值图像代表什么呢?如果输入的特征满足二泛数小于1的约束,即满足:

那么可以证明只有当输入的x中的每一维满足:
 时,其对隐含层的active才最大,也就是说最容易是隐含层的节点输出为1,可以看出,输入值和权值应该是正相关的。
时,其对隐含层的active才最大,也就是说最容易是隐含层的节点输出为1,可以看出,输入值和权值应该是正相关的。4.实验结果及运行环境
实验结果
梯度检查所得差值为7.0949e-11,远小于1.0e-9,满足条件。
得到的隐藏层单元可视化图像如下所示;

我们可以看到隐藏层单元学习到类似图像边缘的高阶特征。
梯度检查耗时:1261.874秒,约21分钟
关闭梯度检查,训练样本耗时:85.030秒
运行环境
处理器: AMD A6-3420M APU with Radeon(tm) HD Graphics 1.50 GHz
RAM:4.00GB(2.24GB可用)
OS:Windows 7,32 bit
Matlab:R2012b(8.0.0.783)
-
附录:实际运行结果

...skip some results

>> train
Iteration FunEvals Step Length Function Val Opt Cond
1 4 7.63802e-02 8.26408e+00 2.99753e+02
2 5 1.00000e+00 4.00717e+00 1.59412e+02
3 6 1.00000e+00 1.63622e+00 6.87329e+01
4 7 1.00000e+00 8.46885e-01 3.03970e+01
5 8 1.00000e+00 5.82961e-01 1.13785e+01
6 9 1.00000e+00 5.27282e-01 3.28861e+00
7 10 1.00000e+00 5.21369e-01 5.66333e-01
8 11 1.00000e+00 5.21182e-01 6.87621e-02
9 12 1.00000e+00 5.21174e-01 5.95455e-02
10 13 1.00000e+00 5.21153e-01 1.00395e-01
11 14 1.00000e+00 5.21136e-01 8.79291e-02
12 15 1.00000e+00 5.21108e-01 8.22846e-02
13 16 1.00000e+00 5.21027e-01 1.21261e-01
....
395 410 1.00000e+00 4.46807e-01 4.30329e-02
396 411 1.00000e+00 4.46794e-01 5.90697e-02
397 412 1.00000e+00 4.46780e-01 6.49777e-02
398 413 1.00000e+00 4.46768e-01 4.46670e-02
399 414 1.00000e+00 4.46761e-01 2.51915e-02
400 415 1.00000e+00 4.46758e-01 2.03033e-02
Exceeded Maximum Number of Iterations
>>