工具介绍
1.1 Yearning
1.1.1 Yearning简介
Yearning 开源的MySQL SQL语句审核平台,提供数据库字典查询,查询审计,SQL审核等多种功能。
Yearning 1.x 版本需Inception提供SQL审核及回滚功能。
Inception是集审核,执行,回滚于一体的自动化运维系统,它是根据MySQL代码修改过来的,工
作模式和MySQL相同。Yearning是基于python实现的Web版人机交互界面。
Yearning 2.0 版本开始无需Inception,已自己实现了SQL审核及回滚功能。
Yearning1.0 python版本已不再进行官方维护。
Yearning2.0 golang版本为后续维护项目。
如仍使用python版本Yearning须知:
Yearning python版本不会闭源,仍可基于AGPL3.0许可进行二次开发。
由于inception已闭源失去后续支持,python版本将失去对审核规则及审核逻辑的维护。(此问
题即使Yearning项目也无法解决。go版本已实现相关审核逻辑,由Yearning自己维护,保证
后续维护的可控性。)
已知python版本含有多个提权漏洞(用户 -> 管理员) golang版本通过token内嵌角色信息的方
式避免了此类问题。
强烈建议使用Yearning2.0。
1.1.2 Yearning功能
-
Yearning 工具包含的主要功能如下:
-
SQL查询
-
查询导出
-
查询自动补全
-
SQL审核
-
流程化工单
-
SQL语句检测
-
SQL语句执行
-
SQL回滚
-
历史审核记录
-
推送
-
站内信工单通知
-
E-mail工单推送
-
钉钉webhook机器人工单推送
-
其他
-
todoList
-
LDAP登陆
-
用户权限及管理
-
拼图式细粒度权限划分
-
功能界面
-
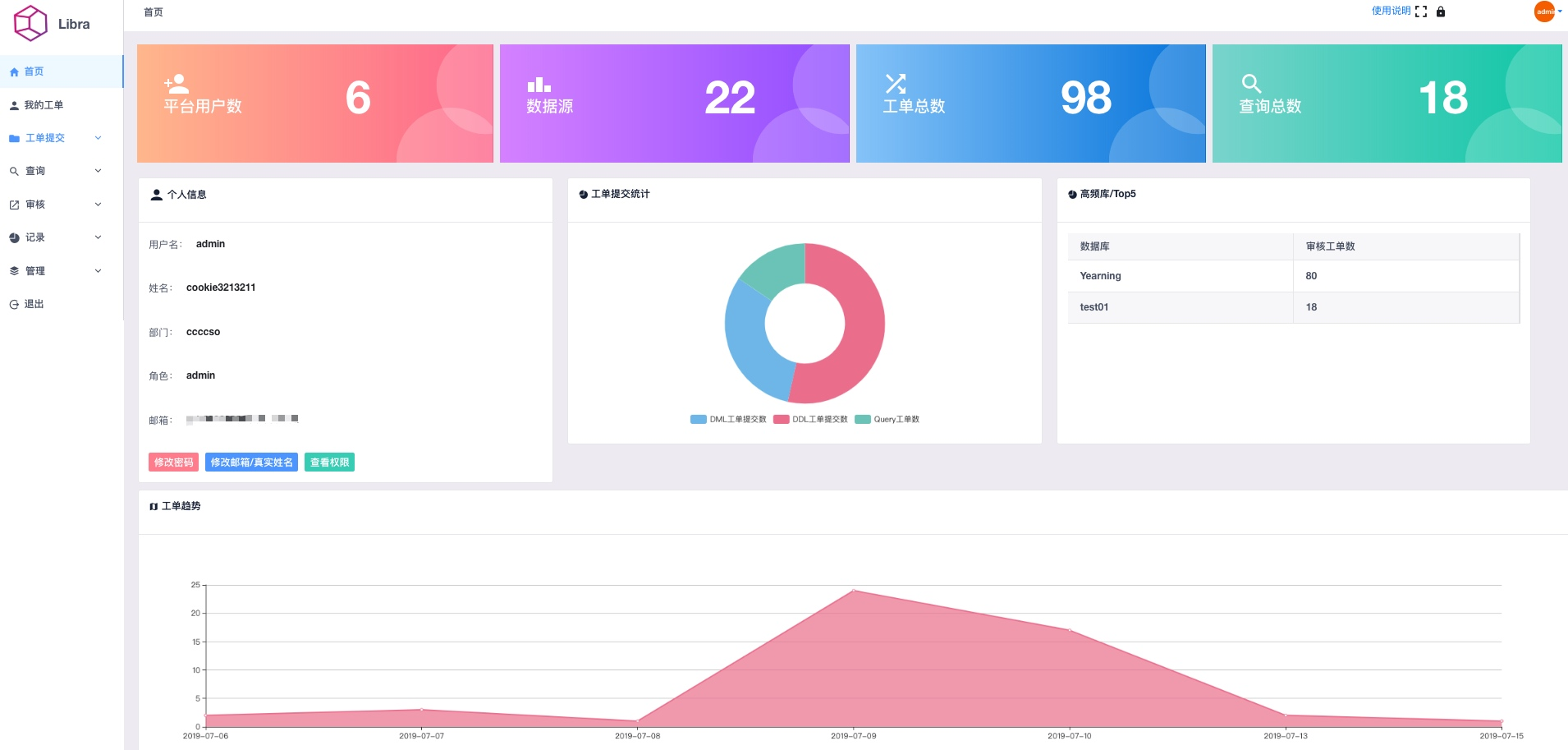
dashboard
dashboard主要展示Yearning各项数据包括用户数/数据源数/工单数/查询数以及其他图表。
个人信息栏内用户可以修改密码/邮箱/真实姓名,同时可以查看该用户权限以及申请权限
-
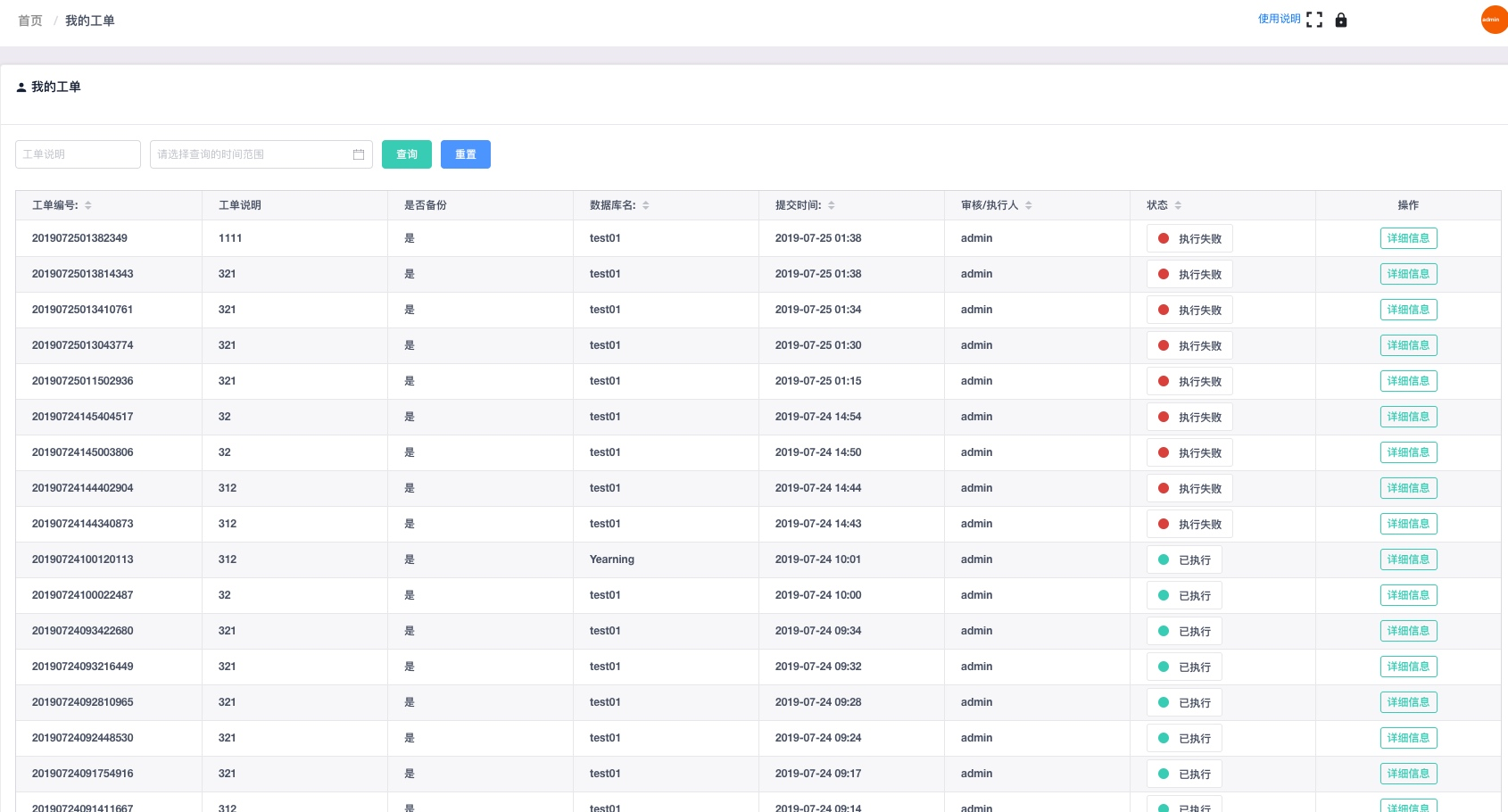
我的工单
展示用户提交的工单信息。对于执行失败/驳回的工单点击详细信息后可以重新修改sql并提
交;对于执行成功的工单可以查看回滚语句并且快速提交SQL。
-
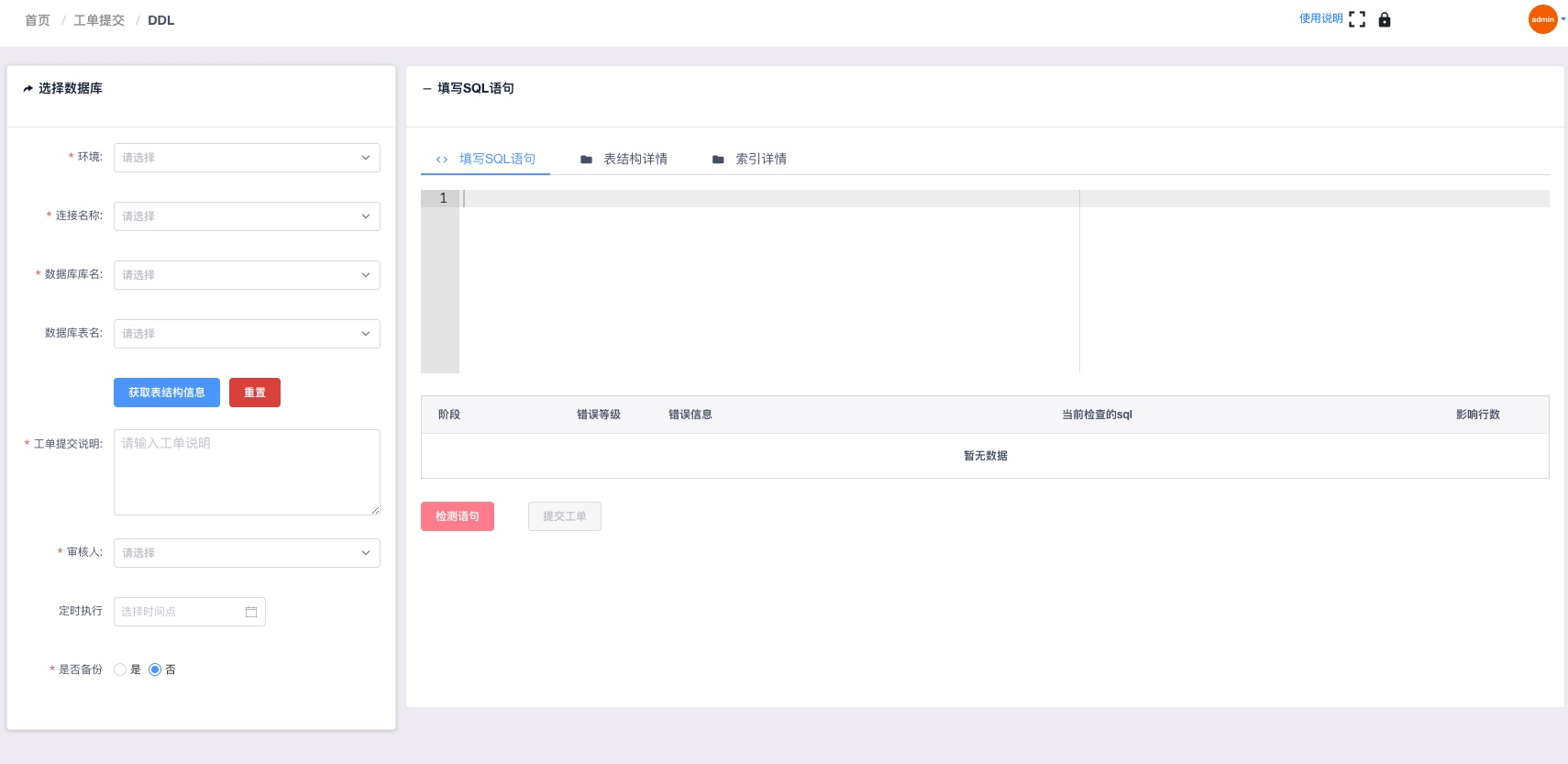
DDL审核
DDL相关SQL提交审核,查看表结构/索引,SQL语法高亮/自动补全
-
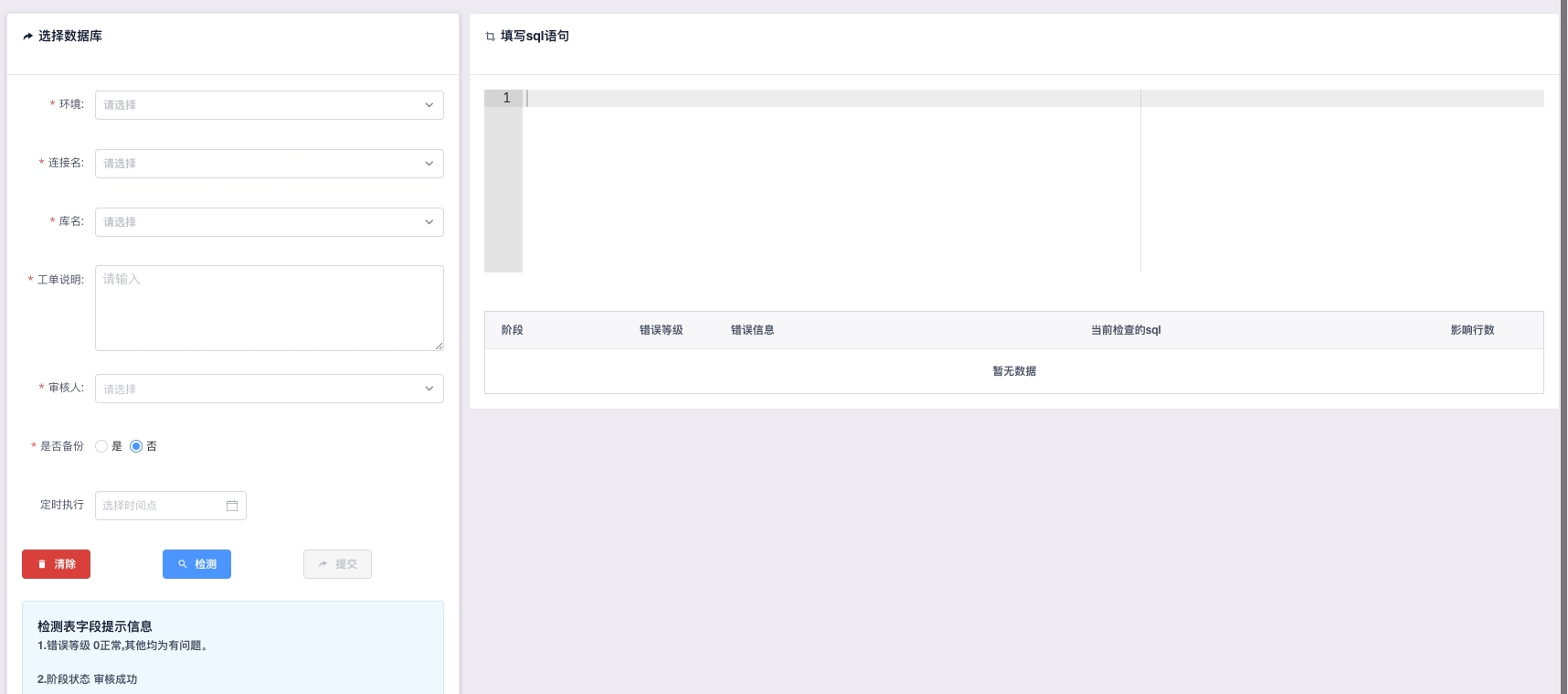
DML审核
DML相关SQL提交审核,SQL语法高亮/自动补全。所有的SQL只有在检测后错误等级为0时提
交按钮才会激活。
-
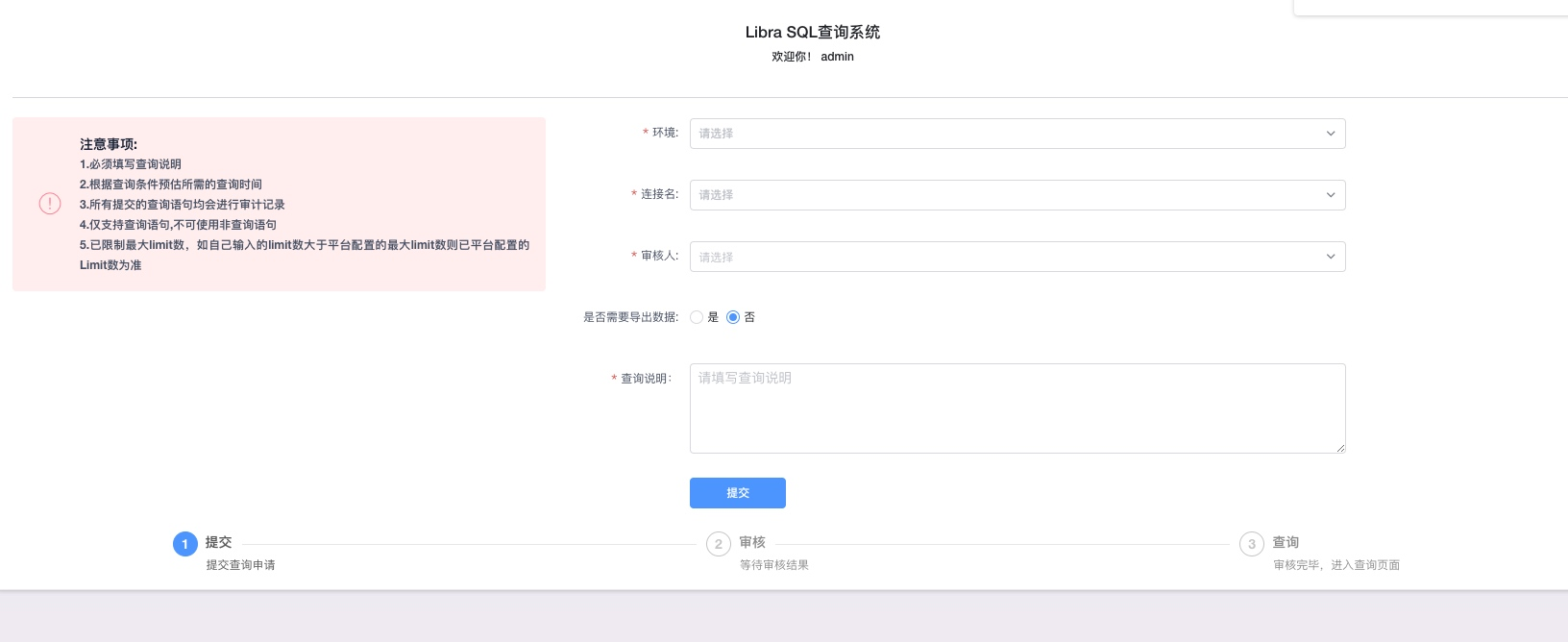
查询审核
查询/导出数据 SQL语法高亮/自动补全,快速DML语句提交。
-
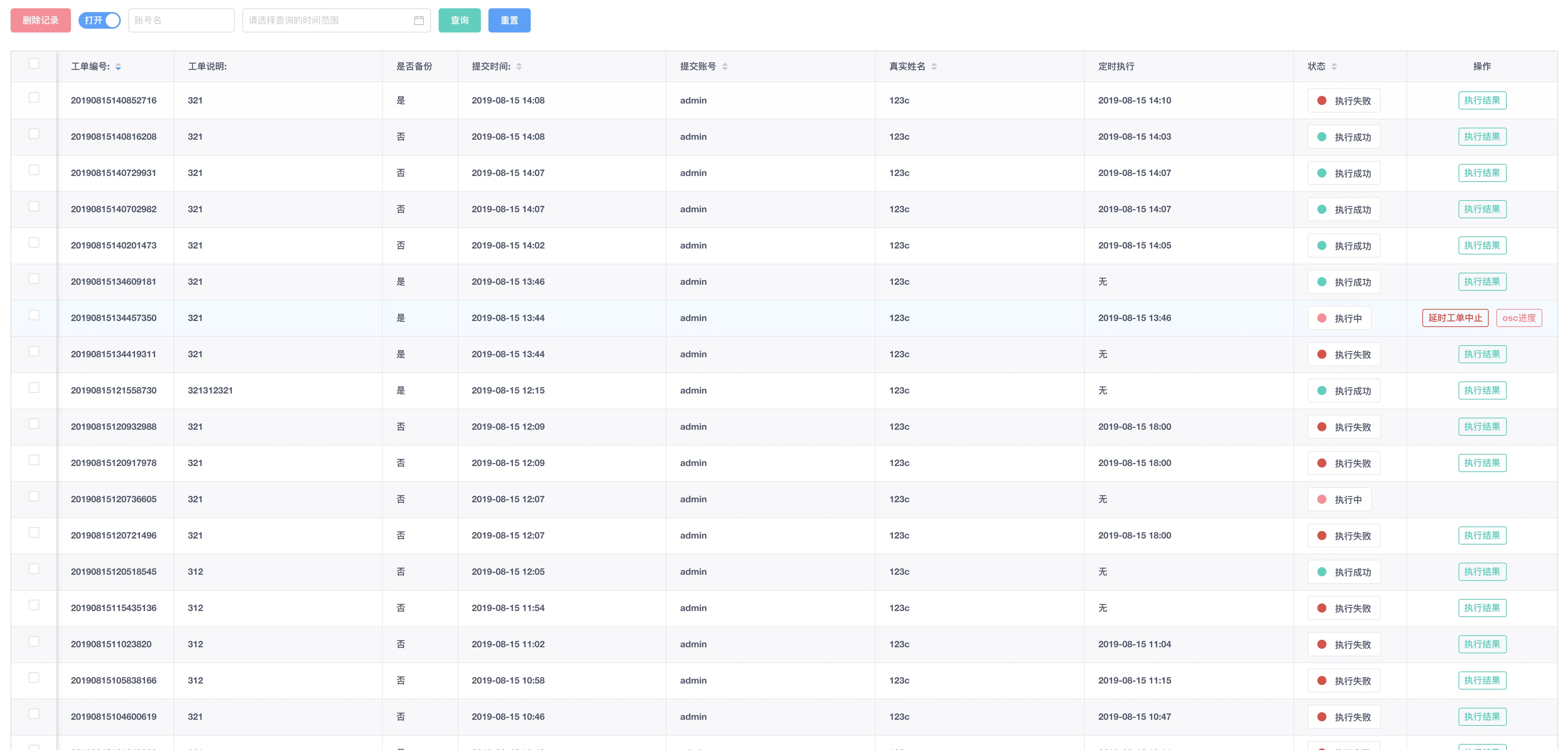
工单审核
DDL/DML管理员审核并执行。
-
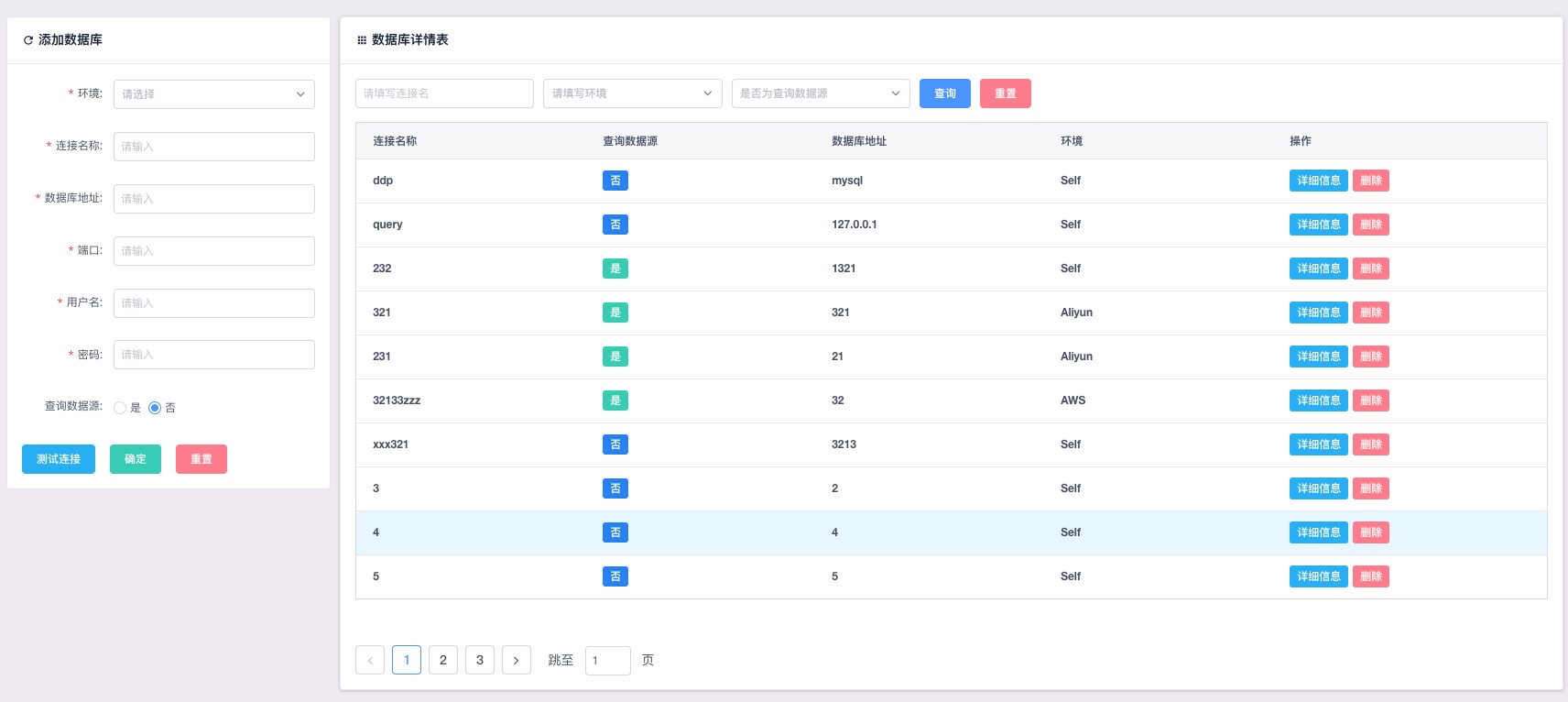
数据库管理
添加/编辑/删除 数据源。所有添加的数据源应在添加之前点击测试连接按钮进行连接性测试,
保证连接性。
数据源分为查询数据源/非查询数据源。查询数据源仅会出现在细粒度权限的查询数据源范围
内。非查询数据源同理。
-
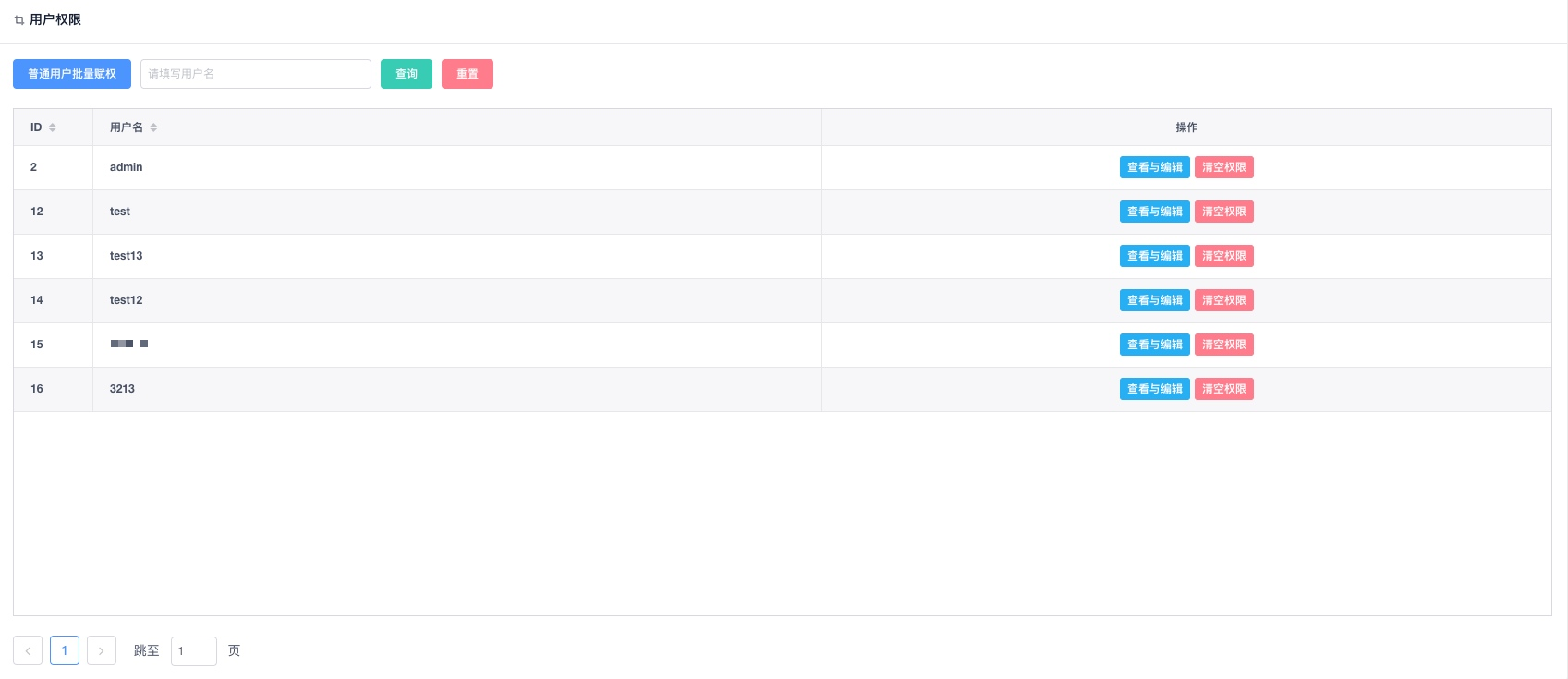
用户权限管理
用户权限修改。
-
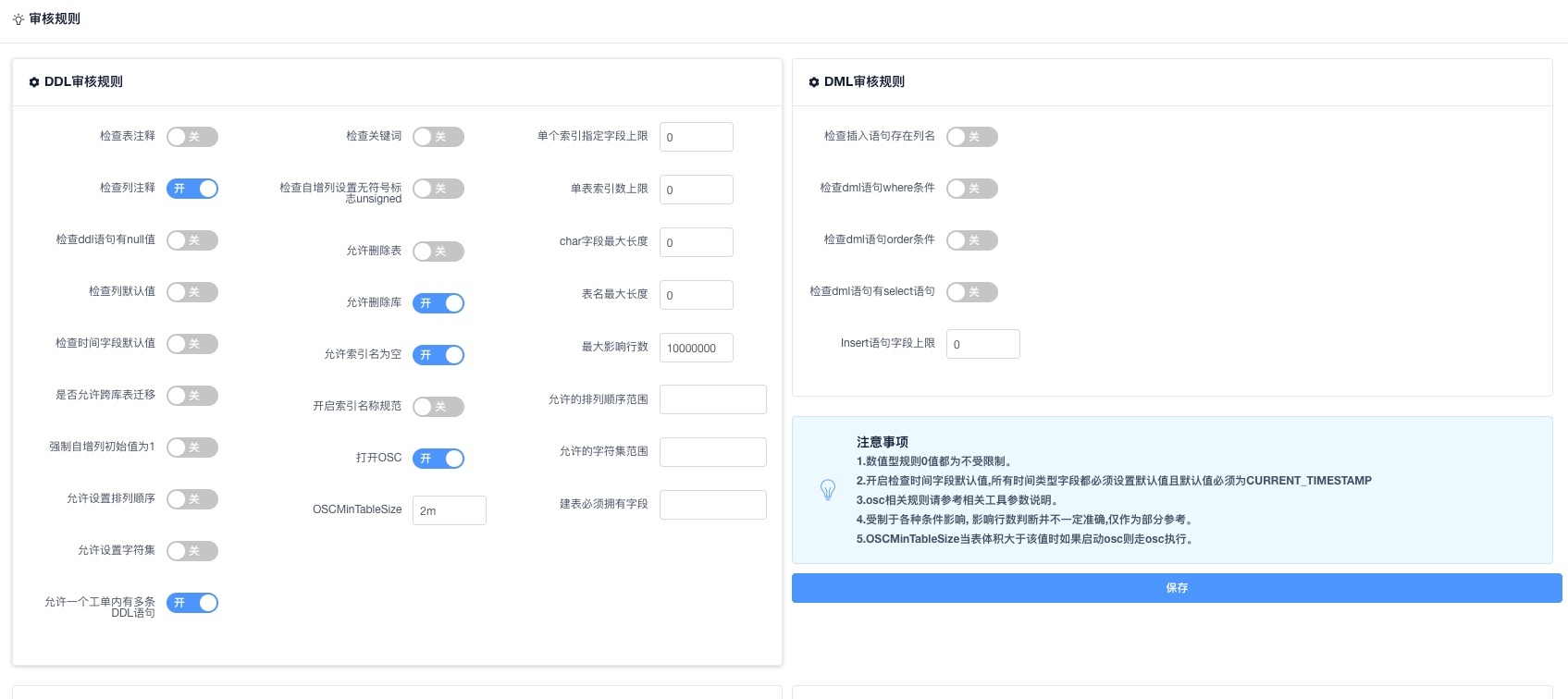
审核规则管理
设置SQL检测规则。数值型规则0值都为不受限制,保存后即时生效。
想了解更多Yearning工具安装和使用详情,可参考官网文档:https://guide.yearning.io/
1.2 canal
1.2.1 canal简介
canal 译意为水道/管道,主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务
trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍
生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括以下内容:
-
数据库镜像
-
数据库实时备份
-
索引构建和实时维护(拆分异构索引、倒排索引等)
-
业务 cache 刷新
-
带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.2.2 canal工作原理
MySQL主备复制原理
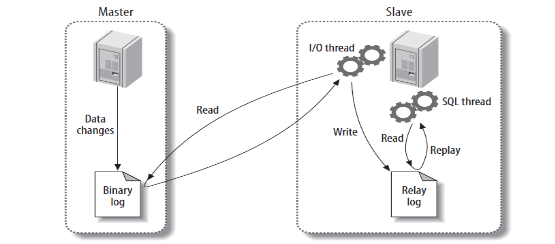
-
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log
events,可以通过 show binlog events 进行查看) -
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
-
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal的工作原理类似mysql主从同步原理:
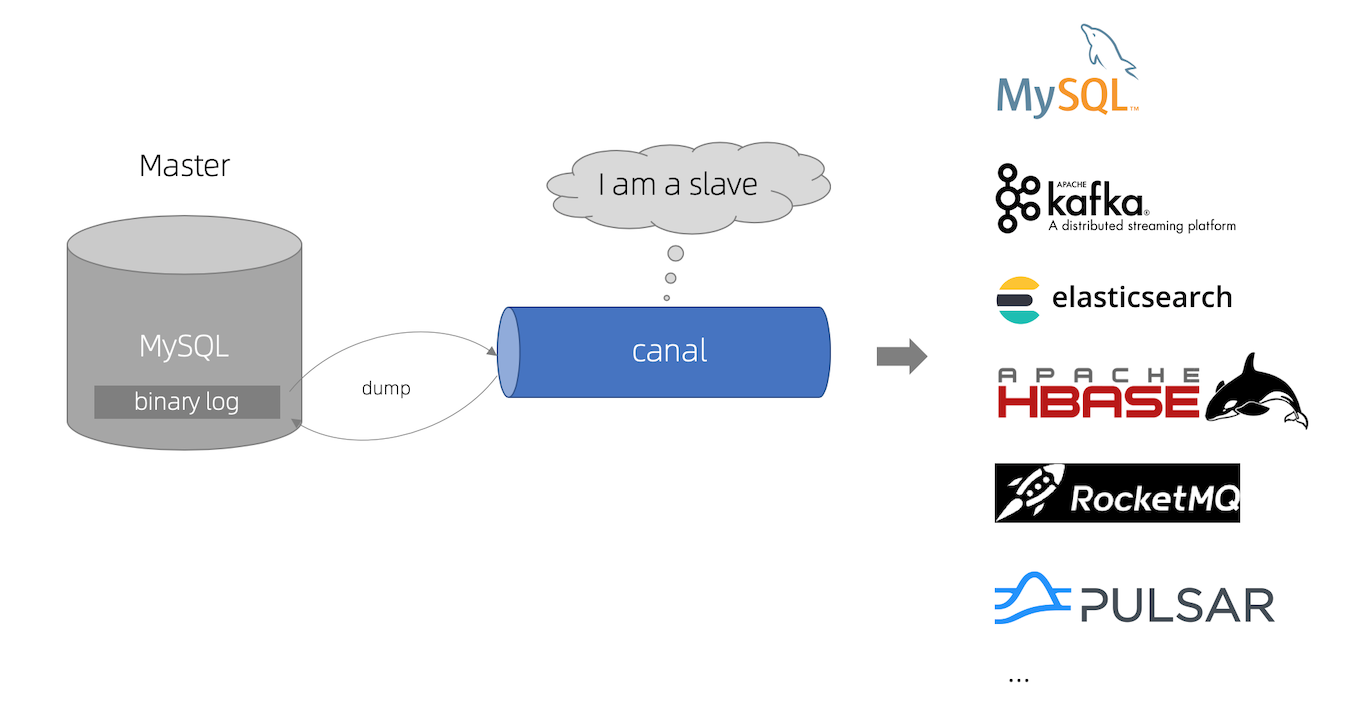
-
canal模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议
-
MySQL master收到dump协议请求,开始推送binary log 给canal
-
canal解析binary log对象(原始为byte流)
1.2.3 canal应用场景
该技术在拉勾网职位搜索业务中得到了采用,场景:在企业HR发布、更新或删除职位时,我们需要及
时更新职位索引,便于求职者能快速的搜索到。
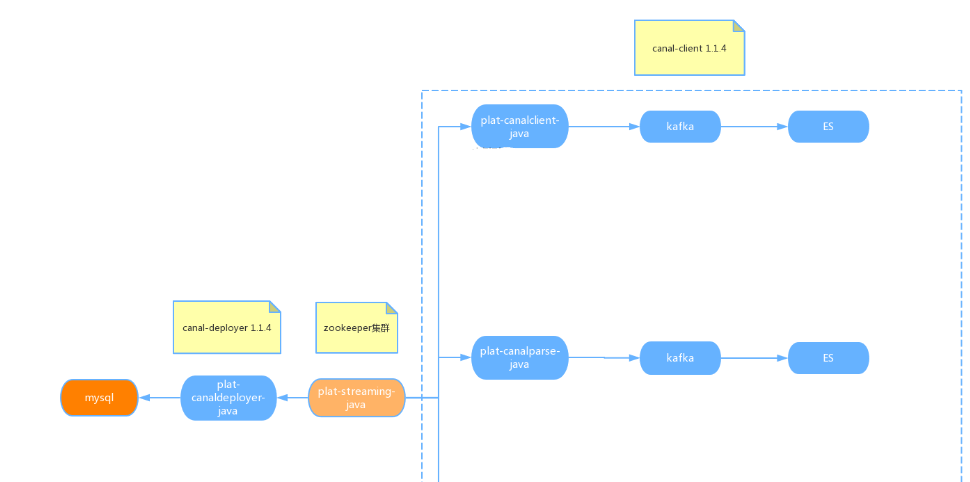
想了解更多cannal工具详情,可参考官网文档:https://github.com/alibaba/canal
1.3 DataX
1.3.1 DataX简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、
SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS
等各种异构数据源之间高效的数据同步功能。
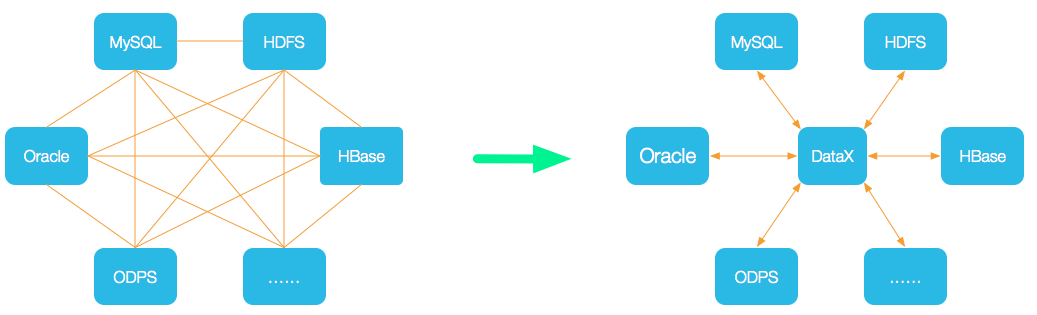
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间
传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,
便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了多年。
当年每天完成同步8w多道作业,每日传输数据量超过300TB。
1.3.2 DataX框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为
Reader/Writer插件,纳入到整个同步框架中。

Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流
控,并发,数据转换等核心技术问题。
1.3.3 DataX插件体系
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插
件,就能无缝对接其他数据源。经过几年积累,DataX目前已经有了比较全面的插件体系,主流的
RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
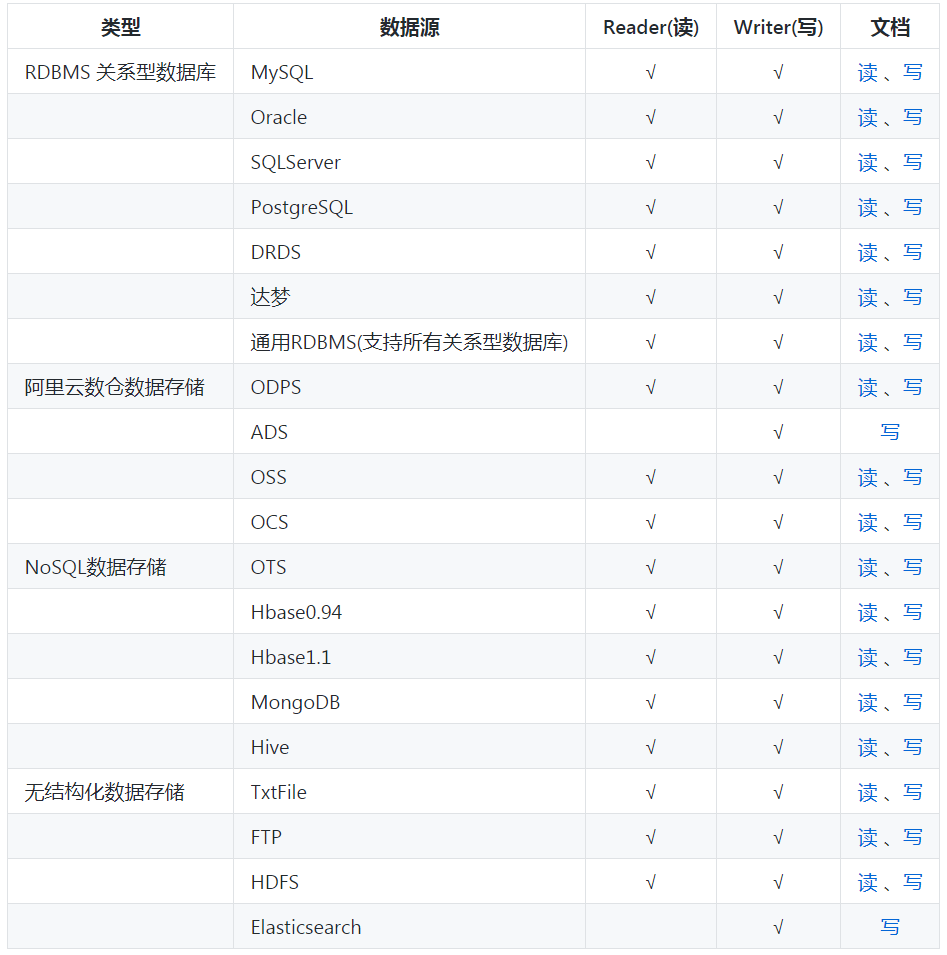
1.3.4 DataX核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序
图,从整体架构设计非常简要说明DataX各个模块相互关系。
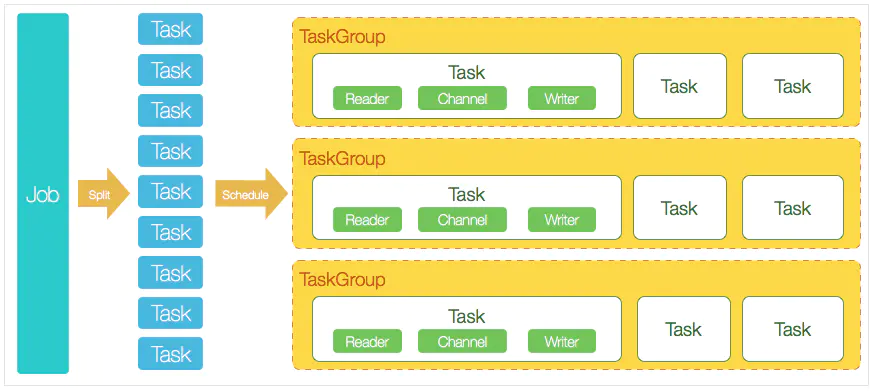
-
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来
完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切
分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。 -
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发
执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。 -
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task
重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所
有Task,默认单个任务组的并发数量为5。 -
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的
线程来完成任务同步工作。 -
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任
务完成后Job成功退出。否则,异常退出,进程退出值非0
想了解更多DataX工具详情,可参考官网文档:https://github.com/alibaba/DataX
1.4 percona-toolkit
1.4.1 percona-toolkit介绍
MySQL数据库是轻量级、开源数据库的佼佼者,因此有很多功能强大第三方的衍生产品,如perconatoolkit,XtraBackup等。percona-toolkit是一组高级命令行工具的集合,可以查看当前服务的摘要信
息,磁盘检测,分析慢查询日志,查找重复索引,实现表同步等等。
percona-toolkit工具是 MySQL一个重要分支产品percona的,它是一组命令的集合。下面给大家介绍
几个生产中常用的命令。
1.4.2 percona-toolkit安装
工具包的下载地址:https://www.percona.com/downloads/percona-toolkit/LATEST/
安装过程很简单,先解压:
tar -zxvf percona-toolkit-3.0.3_x86_64.tar.gz
由于是二进制的包,解压完可以直接进到percona-toolkit-3.0.3/bin目录下使用。
1.4.3 pt-query-digest
pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也
可以通过showprocesslist或者mysqldumpslow命令来进行分析。可以把分析结果输出到文件中,分析
过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行
时间、次数、占比等,可以借助分析结果找出问题进行优化。
大家都知道数据库大多数的性能问题是 slow sql 语句造成的,需要及时做相关的优化处理。使用示例如
下:
-
直接分析慢查询文件:
pt-query-digest slow_OAK.log > slow_report.log -
分析最近24小时内的查询:
pt-query-digest --since=24h slow_OAK.log > slow_report.log -
分析只含有select语句的慢查询
pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i'slow_OAK.log> slow_report.log
查看SQL报告,总结慢语句有哪些,并可以看对应时间的消耗。分析结果如下所示:
cat slow_report.log
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ======= ===== ==============
# 1 0x040ADBE3A1EED0A2 16.8901 87.2% 1 16.8901 0.00 CALL insert_city
# 2 0x8E44F4ED46297D4C 1.3013 6.7% 3 0.4338 0.18 INSERT SELECT
lagou._city
# 3 0x12E7CAFEA3145EEF 0.7431 3.8% 1 0.7431 0.00 DELETE city
# MISC 0xMISC 0.4434 2.3% 3 0.1478 0.0 <3ITEMS>
# Query 1: 0 QPS, 0x concurrency, ID 0x040ADBE3A1EED0A2 at byte 19060 ____
# Scores: V/M = 0.00
# Time range: all events occurred at 2020-05-08 12:12:10
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 2 1
# Exec time 47 18s 18s 18s 18s 18s 0 18s
# Lock time 0 103us 103us 103us 103us 103us 0 103us
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 0 0 0 0 0 0 0 0
# Query size 0 21 21 21 21 21 0 21
# String:
# Databases lagou
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
call insert_city(50000)G
可以看到报告中,列举出了一些sql语句响应时间占比情况,以及SQL语句的执行时间情况。方便我们可
以很直观的观察哪些语句有问题。
1.4.4 pt-index-usage
pt-index-usage命令能够连接到MySQL数据库服务器,读取慢查询日志,并使用EXPLAIN询问MySQL
如何执行每个查询。分析完成时,它打印出一个关于查询没有使用的索引的报告。
对于我们已有的生产环境,随着系统运行的时间越长,DML操作越来越慢,这可能和我们最初设计的索
引是有关的(变慢的情况很多),项目一旦上线,很少会有人去关注索引的使用情况。某些索引是从
create开始就没使用过,这无形中就给MySQL增加了维护负担,任何对该表的DML操作,都要维护这些
没有被使用的索引。我们可以使用pt-index-usage工具找出哪些索引一直没有被使用,然后进行删除。
pt-index-usage语法格式如下:
pt-index-usage [OPTION...] [FILE...]
打印报告:
pt-index-usage /path/to/slow_OAK.log --host localhost
也可以将报告写入到一个数据库表中,存入后方便我们的查看。如果在生产服务器上使用此功能,则应
该小心,它可能会增加负载。
pt-index-usage slow.log --no-report --save-results-database percona
1.4.5 pt-online-schema-change
pt-online-schema-change命令可以在线整理表结构,收集碎片,给大表添加字段和索引。避免出现锁
表导致阻塞读写的操作。针对 MySQL 5.7 版本,就可以不需要使用这个命令,直接在线 online DDL 就
可以了。
pt-online-schema-change --user=root --password=root --host=localhost --alter="ADD COLUMN city_bak VARCHAR(256)" D=lagou,t=city --execute
1.4.6 pt-table-checksum
pt-table-checksum命令可以检查主从复制一致性。pt table checksum通过在主机上执行校验和查询来
执行在线复制一致性检查。如果发现任何差异,或者出现任何警告或错误,则工具的“退出状态”为非0
该命令将连接到本地主机上的复制主机,对每个表进行校验和,并报告每个检测到的复制副本的结果:
比较lagou库的差异情况,在主库上面执行:
[root@node1 bin]# ./pt-table-checksum --no-check-binlog-format --nocheckreplication-filters --databases=lagou --replicate=lagou.checksums --
host=192.168.95.130 -uroot -proot
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
05-10T18:01:05 0 0 1 1 0 0.013
lagou.heartbeat
05-10T18:01:05 0 0 0 1 0 0.015 lagou.city
05-10T18:01:05 0 0 0 1 0 0.011 lagou.position
上述结果显示diff都为0,证明主从的lagou库没有差异情况。
比较lagou库哪些表有差异(需要添加replicate-check-only),在主库上面执行:
[root@node1 bin]# ./pt-table-checksum --no-check-binlog-format
--nocheck-replication-filters --databases=lagou --replicate=lagou.checksums
--replicate-check-only --host=192.168.95.130 -uroot -proot
Differences on node1
TABLE CHUNK CNT_DIFF CRC_DIFF CHUNK_INDEX LOWER_BOUNDARY UPPER_BOUNDARY
lagou.position_detail 1 1 1
上述结果显示lagou库下面position_detail表主从数据不一致。
除了上述命令外,还有很多,例如pt-ioprofile可以命令方便定位IO问题;pt-slave-restart可以监
控主从错误,尝试重启MySQL主从。想了解更多percona-toolkit工具详情,可参考官网文档:htt
ps://www.percona.com/doc/percona-toolkit/3.0/index.html
1.5 MySQLMTOP
1.5.1 MySQLMTOP简介
MySQLMTOP 是一个由Python+PHP开发的开源MySQL企业监控系统。该系统由Python实现多进程数
据采集和告警,PHP实现Web展示和管理,优点如下:
-
MySQL服务器无需安装任何Agent,只需在监控WEB界面配置相关数据库信息
-
启动监控进程后,即可对上百台MySQL数据库的状态、连接数、QTS、TPS、数据库流量、复制、
性能慢查询等进行实时监控。 -
可以在数据库偏离设定的正常运行阀值(如连接异常,复制异常,复制延迟) 时发送告警邮件通知到
DBA进行处理。 -
可以对历史数据归档,通过图表展示数据库近期状态,以便DBA和开发人员能对遇到的问题进行分
析和诊断。
MySQLMTOP 发展历史如下:
2014年01月,开源MySQLMTOP企业MySQL监控系统正式上线并开源
2014年06月,MySQLMTOP进行重构,加入了Oracle、Mongodb、Redis的支持,正式更名为Lepus
2014年08月,Lepus 成功取得商业软件著作权
2015年01月,开源MySQLMTOP被评为2014优秀开源软件
2015年01月,Lepus正式开源,并建立官方网站向大家免费提供服务
2015年06月,Lepus网站软件下载总数量统计超过10000+,并广泛应用于各大互联网企业生产数据库的
监控
2017年01月,Lepus代码托管至github,网站软件下载总数量统计超过30000+
1.5.2 MySQLMTOP功能
MySQLMTOP主要功能如下:
-
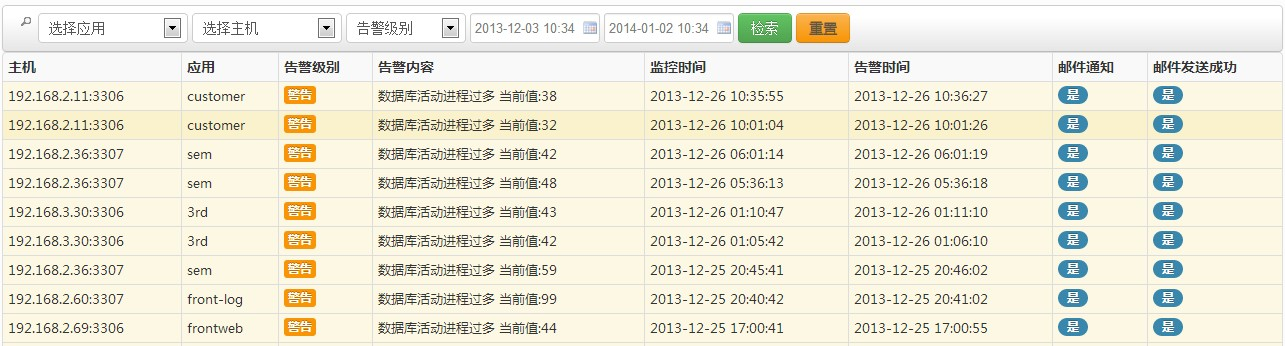
实时 MySQL 状态监控和警报
MySQLMTOP 持续监视 MySQL 的基本状态和性能信息,包括数据库连接状态,启动时间,数据
库版本,总连接数,活动进程,QPS,TPS,进出MySQL数据库的流量信息。在数据库状态异常或
偏离正常基准水平时发出报警邮件通知。
-
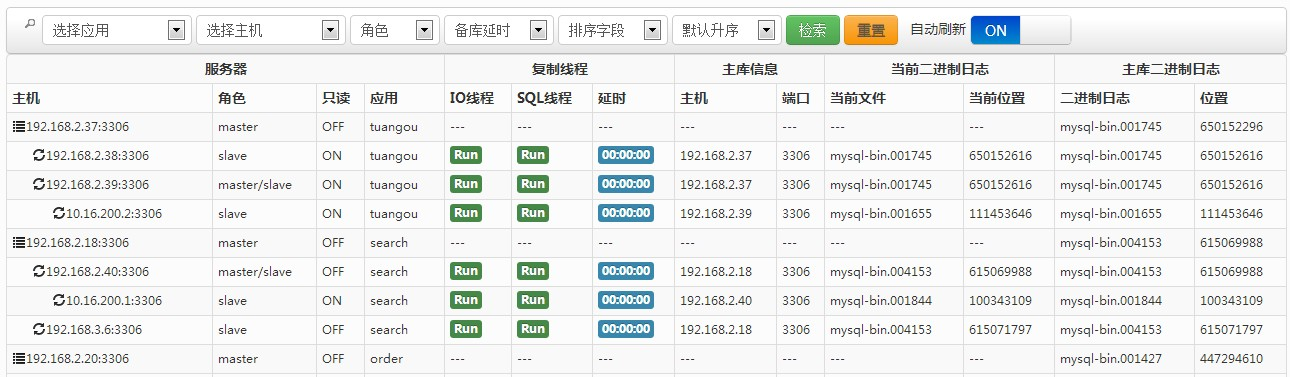
实时 MySQL复制监控
MySQLMTOP自动发现 MySQL 复制拓扑结构,自动监视数据库的延时和binlog信息,可以了解所
有 MySQL 主服务器和从服务器的性能、可用性和运行状况。并在问题(如从服务器延迟)导致停
机前向管理员提供改正建议。 -
远程监控云中的 MySQL
适合于云和虚拟机的设计,能远程监视MySQL服务器不需要任何远程代理器。 -
直观管理所有 MySQL
MySQLMTOP提供一个基于 Web 的界面,可令全面深入地了解数据库性能、可用性、关键活动
等;直观地查看一台服务器、自定义的应用组或所有服务器。一组丰富的实时图形和历史图形将帮
助您深入了解详细的服务器统计信息。
-
可视化MySQL慢查询分析
监视实时查询性能,查看执行统计信息,筛选和定位导致性能下降的 SQL 代码。结合使用
Information Schema 可直接从 MySQL 服务器收集数据,无需额外的软件或配置。 -
性能监控
监视影响 MySQL 性能的主要指标。如Key_buffer_read_hits、Key_buffer_write_hits、
Thread_cache_hits、Key_blocks_used_rate、Created_tmp_disk_tables_rate等信息,根据相关
性能指标可以对服务器核心参数进行调整优化。
想了解更多MySQLMTOP工具详情,可参考官网文档:http://www.lepus.cc/
1.6 ELK
1.6.1 为什么用ELK
在简单应用中,直接在日志文件中 grep就可以获得自己想要的信息。但在规模较大分布式系统中,此
方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中
化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点
上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分
情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块。构建一套集中式日志系统,可以
提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
-
收集-能够采集多种来源的日志数据
-
传输-能够稳定的把日志数据传输到中央系统
-
存储-如何存储日志数据
-
分析-可以支持 UI 分析
-
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场
合的应用。目前主流的一种日志系统。
1.6.2 ELK实现架构
ELK 最早是 Elasticsearch(简称ES)、Logstash、Kibana 三款开源软件的简称,三款软件后来被同一
公司收购,并加入了Xpark、Beats等组件,改名为Elastic Stack,成为现在最流行的开源日志解决方
案,虽然有了新名字但大家依然喜欢叫ELK,现在所说的ELK就指的是基于这些开源软件构建的日志系
统。
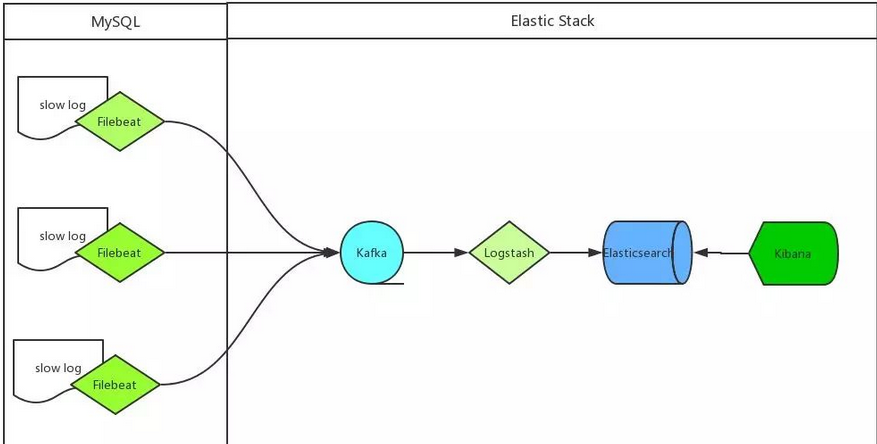
上述架构中,各技术作用如下
-
MySQL 服务器安装 Filebeat 作为 agent 收集 slowLog
-
Filebeat 读取 MySQL 慢日志文件做简单过滤传给 Kafka 集群
-
Logstash 读取 Kafka 集群数据并按字段拆分后转成 JSON 格式存入 ES 集群
-
Kibana 读取ES集群数据展示到web页面上
1.6.3 慢查询日志收集展示
Filebeat日志收集
filebeat读取收集slow log,处理后写入kafka。收集日志时需要解决以下问题:
-
日志行合并
-
获取SQL执行时间
-
确定SQL对应的DB名
-
确定SQL对应的主机
Filebeat示例
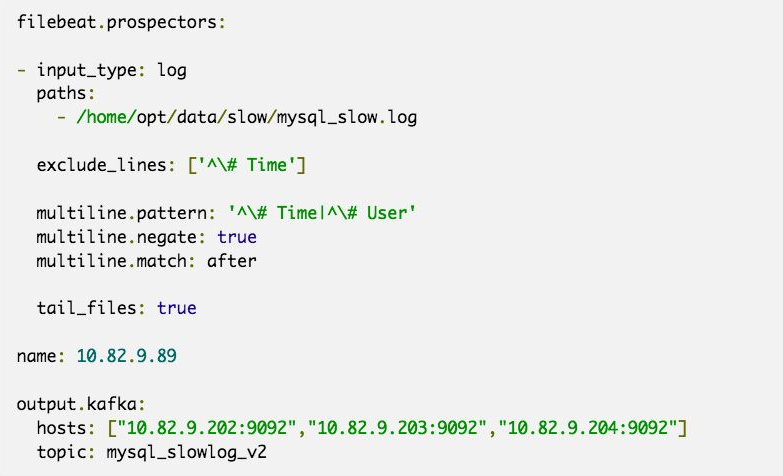
重要参数解释:
-
input_type:指定输入的类型是log或者是stdin
-
paths:慢日志路径,支持正则,比如/data/*.log
-
exclude_lines:过滤掉#Time开头的行
-
multiline.pattern:匹配多行时指定正则表达式,这里匹配以# Time或者# User开头的行,
Time行要先匹配再过滤 -
multiline.negate:定义上边pattern匹配到的行是否用于多行合并,也就是定义是不是作为日志
的一部分 -
multiline.match:定义匹配的行日志作为日志元素的开始还是结束。
-
tail_files:定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存
在的不管 -
name:设置filebeat的名字,如果为空则为服务器的主机名,这里我们定义为服务器IP
-
output.kafka:配置要接收日志的kafka集群地址可topic名称
Kafka 接收示例:
{"@timestamp":"2020-05-08T09:36:00.140Z","beat":
{"hostname":"oak","name":"10.63.144.71","version":"5.4.0"},"input_type":"log","m
366458
SET timestamp=1533634557;
SELECT DISTINCT(uid) FROM common_member WHERE
hideforum=-1 AND uid !=
0;","offset":1753219021,"source":"/data/slow/mysql_slow.log","type":"log"}
Logstash示例
Logstash消费kafka消息,可以利用kafka consumer group实现集群模式消费保障单点故障不影响日志
处理,grok正则处理后写入elasticsearch。

重要参数解释:
-
input:配置 kafka 的集群地址和 topic 名字
-
filter:过滤日志文件,主要是对 message 信息(前文 kafka 接收到的日志格式)进行拆分,拆
分成一个一个易读的字段,例如User、Host、Query_time、Lock_time、timestamp等。 -
grok:MySQL版本不同,慢查询日志格式有些差异,grok可以根据不同的慢查询格式写不同的正
则表达式去匹配,当有多条正则表达式存在时,logstash会从上到下依次匹配,匹配到一条后边的
则不再匹配。 -
date:定义让SQL中的timestamp_mysql字段作为这条日志的时间字段,kibana上看到的实践排
序的数据依赖的就是这个时间 -
output:配置ES服务器集群的地址和index,index自动按天分割
Elasticsearch部分略过,默认设置即可达到需求。
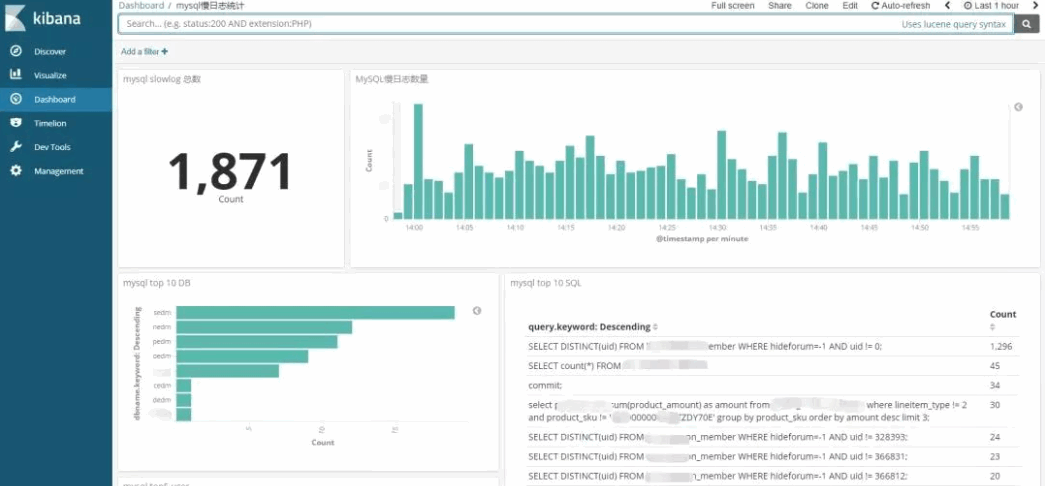
Kibana示例
打开Kibana添加 mysql-slowlog-* 的Index,并选择timestamp,创建Index Pattern。进入Discover
页面,就可以很直观的看到各个时间点慢日志的数量变化,可以根据左侧Field实现简单过滤,搜索框也
方便搜索慢日志。
1.7 Prometheus
1.7.1 Prometheus简介
Prometheus于2012年由SoundCloud创建,目前已经已发展为最热门的分布式监控系统。
Prometheus完全开源的,被很多云厂商(架构)内置,在这些厂商(架构)中,可以简单部署
Prometheus,用来监控整个云基础架构设施。比如DigitalOcean或Docker都使用普罗米修斯作为基础
监控。
Prometheus是一个时间序列数据库,它涵盖了可以绑定的整个生态系统工具集及其功能。
Prometheus主要用于对基础设施的监控,包括服务器、数据库、VPS,几乎所有东西都可以通过
Prometheus进行监控。
Prometheus主要优点如下:
-
提供多维度数据模型和灵活的查询方式。通过将监控指标关联多个tag,来将监控数据进行任意维
度的组合,并且提供简单的PromQL,还提供查询接口,可以很方便地结合等GUI组件展示数据。 -
在不依赖外部存储的情况下,支持服务器节点的本地存储。通过Prometheus自带的时序数据库,
可以完成每秒千万级的数据存储。 -
定义了开发指标数据标准,以基于HTTP的pull方式采集时序数据。只有实现了Prometheus监控数
据格式的监控数据才可以被Prometheus采集、汇总。 -
支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。Prometheus目前已经
支持Kubernetes、etcd、consul等多种服务发现机制,可以减少运维人员的手动配置环节。 -
易于维护,可以通过二进制文件直接启动,并且提供容器化部署镜像。
-
支持数据的分区采集和联邦部署,支持大规模集群监控。
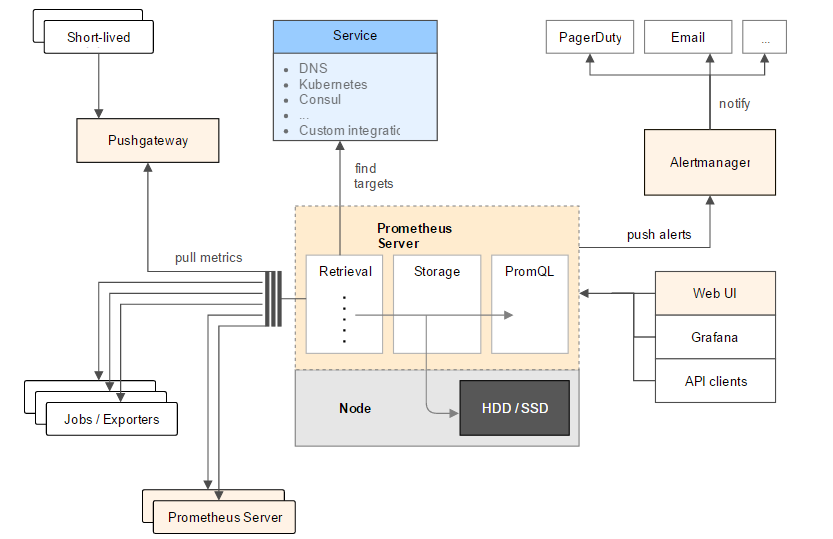
1.7.2 Prometheus生态系统
Prometheus生态系统有功能丰富工具集:
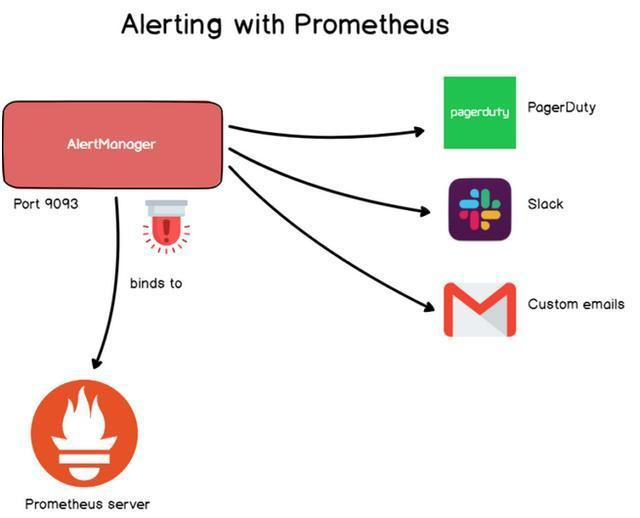
Alertmanager:Prometheus通过配置文件定义规则将告警信息推送到Alertmanager。Alertmanager
可以将其导出到多个端点,例如Pagerduty或Email等。
数据可视化:在Web UI中可视化时间序列数据,轻松过滤查看监控目标的信息,与Grafana、Kibana等
类似。
服务发现:Prometheus可以动态发现监控目标,并根据需要自动废弃目标。这在云架构中使用动态变
更地址的容器时,非常方便。
1.7.3 Prometheus实现原理
数据存储
Prometheus指标数据支持本地存储和远程存储。

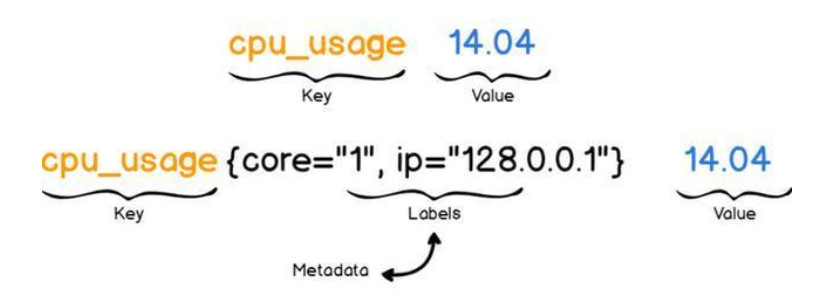
指标数据
Prometheus使用键-值对存储监控数据。键描述了测量值时将实际测量值存储为数字的值。
Prometheus并不会存储原始信息,如日志文本,它存储的是随时间汇总的指标。
一般来说键也就监控指标,如果想要获得有关指标的更多详细信息,Prometheus有一个标签的概念。
标签旨在通过向键添加其他字段来为指标提供更详细信息。
度量类型
Prometheus监控指标有Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)和Summary(摘要)四种
度量类型。
-
Counter
计数器Counter是我们使用的最简单的度量标准形式。计数器的值只能增加或重置为0,比如,要
计算服务器上的HTTP错误数或网站上的访问次数,这时候就使用计数器。 -
Gauges
Gauges用于处理随时间减少或增加的值。比如温度、内存变化等。Gauge类型的值可以上升和下
降,可以是正值或负值。 -
Histogram
直方图Histogram是一种更复杂的度量标准类型。它为我们的指标提供了额外信息,例如观察值的
总和及其数量,常用于跟踪事件发生的规模。其值在具有可配置上限的存储对象中聚合。比如,为
了监控性能指标,我们希望得到在有20%的服务器请求响应时间超过300毫秒发送警告。对于涉及
比例的指标就可以考虑使用直方图。 -
Summary
摘要Summary是对直方图的扩展。除了提供观察的总和和计数之外,它们还提供滑动窗口上的分
位数度量。分位数是将概率密度划分为相等概率范围的方法。直方图随时间汇总值,给出总和和计
数函数,使得易于查看给定度量的变化趋势。而摘要则给出了滑动窗口上的分位数(即随时间不断
变化)。
PromQL
对于Prometheus数据,我们可以通过HTTP来查询,如果是复杂的数据查询,则还可以使用PromQL进
行。和关系型数据库实现SQL解析一样,Prometheus实现了一套自己的数据库语言解析器,最大的区
别是支持查询。
使用Prometheus的PromQL,会处理两种向量:
- 即时向量:表示在最近时间戳中跟踪的指标。
- 时间范围向量:用于查看度量随时间的演变,可以使用自定义时间范围查询Prometheus。
PromQL API公开了一组方便查询数据操作的函数。用它可以实现排序,数学函计算(如导数或指数函
数),统计预测计算(如Holt Winters函数)等。
Instrumentation仪表化
仪表化是Prometheus的一个重要组成部分。在从应用程序检索数据之前,必须要仪表化它们。
Prometheus术语中的仪表化表示将客户端类库添加到应用程序,以便它们向Prometheus吐出指标。
可以对大多数主流的编程语言进行仪表化。
在仪表化操作时,需要创建内存对象(如仪表盘或计数器),然后选择指标公开的位置。Prometheus
将从该位置获取并存储到时间序列数据库。
Exporters模板
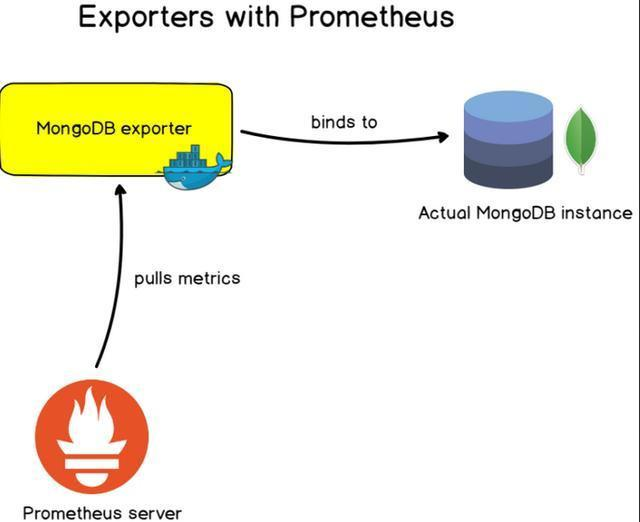
Exporter是一个采集监控数据样本的组件。除了官方实现的Exporter,还有很多第三方实现如 Redis
exporter 和RabbitMQ exporter等。这些Exporters通过HTTPS/HTTP方式、TCP方式、本地文件方式
或标准协议方式访问。
常见的Exporters模版有:
数据库模版:用于MongoDB数据库,MySQL服务器的配置。
HTTP模版:用于HAProxy,Apache或Nginx等Web服务器和代理的配置。
Unix模版:用来使用构建的节点导出程序监视系统性能,可以实现完整的系统指标的监控。
Alertmanager告警
在处理时间序列数据库时,我们希望对数据进行处理,并对结果给出反馈,而这部分工作由告警来实
现。
告警在Grafana中非常常见,Prometheus是通过Alertmanager实现完成的告警系统。Alertmanager是
一个独立的工具,可以绑定到Prometheus并运行自定义Alertmanager。告警通过配置文件定义,定义
由一组指标规则组成,如果数据命中这些规则,则会触发告警并将信息发送到预定义的目标。
Prometheus的告警,可以通过email,Slack webhooks,PagerDuty和自定义HTTP目标等。