BM25算法的全称是 Okapi BM25,是一种二元独立模型的扩展,也可以用来做搜索的相关度排序。
Sphinx的默认相关性算法就是用的BM25。Lucene4.0之后也可以选择使用BM25算法(默认是TF-IDF)。如果你使用的solr,只需要修改schema.xml,加入下面这行就可以
- <similarity class="solr.BM25Similarity"/>
BM25也是基于词频的算分公式,分词对它的算分结果也很重要
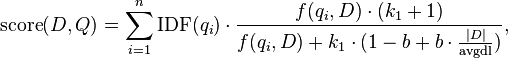
IDF公式
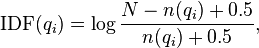
- f(qi,D):就是词频
- |D|:[给定文档]D长度。
- avgdl:索引中所有文档长度。
抽象点看,BM25的公式其实和TF-IDF公式大同小异,可以也可以当做 = ∑ idf(q) * fx(tf),
只不过,BM25的idf和tf都做了一些变形,特别是tf公式,还加入了两个经验参数k1和b,K1和b用来调整精准度,一般情况下我们取K1=2,b=0.75
至于BM25和TF-IDF 哪种相关性算法更更好,我认为依赖于搜索质量评估标准