1.简介:
大型深度神经网络是非常强大的,但其损耗巨大的内存以及对对抗样本的敏感性一直不太理想。作者提出的mixup是一个简单地减缓两种问题的方案。本质上,mixup在成对样本及其标签的凸组合(convex combinations)上训练神经网络。这样做,mixup规范神经网络增强了训练样本之间的线性表达。作者分别在ImageNet-2012、CIFAR-10、CIFAR-100等数据集上进行试验,研究结果表明,mixup可以改进当前最先进的神经网络架构的泛化能力。我们还发现,mixup能够减少对错误标签的记忆,增加对抗样本的鲁棒性,并能够稳定对生成对抗网络的训练过程。
2.背景:
大规模深度神经网络近年来取得了重大的突破,他们具有两点共性:
首先,它们进行训练以将其训练数据的平均误差最小化,这种学习规则也被称为经验风险最小化(Empirical Risk Minimization,ERM)原则(Vapnik于1998年提出);其次,这些当前最先进的神经网络的大小与训练样本的数量呈线性关系。
冲突的地方在于,经典机器学习理论告诉我们,只要学习机(如神经网络)的规模不随着训练数据数量的增加而增加,那么ERM的收敛性就是可以得到保证的。其中,学习机的规模由参数数量,或其VC复杂度(Harvey等人于2017年提出)来衡量。
这一矛盾挑战了ERM方法在当前神经网络训练中的适应性。
一方面,即使在强正则化情况下,或是在标签随机分配的分类问题中,ERM 也允许大规模神经网络去记忆(而不是泛化)训练数据。
另一方面,神经网络使用ERM 方法训练后,在训练分布之外的样本(对抗样本)上验证时会极大地改变预测结果。
这一证据表明,在测试分布与训练数据略有不同时,ERM 方法已不具有良好的解释和泛化性能。
因而,数据增强方法(Simard et al., 1998),在简单但不同的样本中去训练数据以及 Vicinal Risk Minimization( VRM)领域风险最小化原则被提出。在VRM中,需要专业知识描述训练数据中每个样本的邻域,从而可以从训练样本邻域中提取附加的虚拟样本以扩充对训练分布的支持。数据增强可以提高泛化能力,但这一过程依赖于数据集,而且需要专门知识。其次,数据增强假定领域内样本都是同一类,且没有对不同类不同样本之间领域关系进行建模。
3.贡献:
受这些问题启发,作者提出了一种简单且数据无关的数据增强方式,被称作 mixup 。简而言之,mixup 构建了虚拟的训练样本。
其中,(xi,yi)和(xj,yj)是从训练数据中随机抽取的两个样本,且λ∈[0,1]。因此,mixup通过结合先验知识,即特征向量的线性插值应导致相关标签的线性插值,来扩展训练分布。mixup仅需要几行代码即可实现,且引入了最小计算开销。
方法:
论文的贡献在于提出了一种通用的领域分布,称作 mixup:
其中,λ∼Beta(α,α),α∈(0,∞)。
mixup超参数α控制了在特征-目标向量之间插值的强度,当α→0时恢复为 ERM 原则。
上图展示了使用PyTorch 实现 mixup 训练的几行必要代码。
可替换的设计选择:
1).作者观察了三个和三个以上从Dirichlet分布采样的权重样本的凸组合的性能表现也不错,但计算成本增加;
2).当前实现使用单个数据加载获取一个最小批量,然后 mixup 被用于随机打乱后的同一最小批量。作者发现,减少 I/O 请求仍然能取得相同的效果;
3).仅在标签相同的输入中插值,并不能带来 mixup 后续讨论中的性能提升。
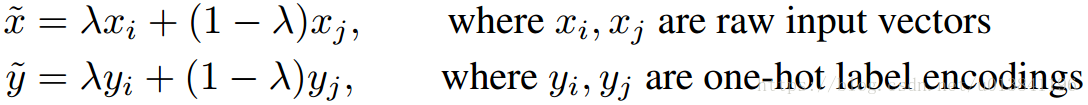

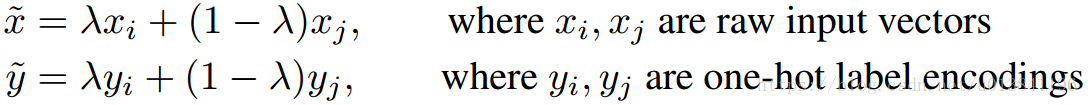

4.理解:
mixup究竟做了什么?mixup邻域分布可以**被理解为一种数据增强方式,它令模型在处理样本和样本之间的区域时表现为线性。我们认为,这种线性建模减少了在预测训练样本以外的数据时的不适应性。**从奥卡姆剃刀的原理出发,线性是一个很好的归纳偏见,因为它是最简单的可能的几种行为之一。图1显示了mixup导致决策边界从一个类到另一个类线性的转变,提供了一个更平滑的不确定性估计。图2显示了在CIFAR-10数据集上用mixup和ERM两个方法训练的两个神经网络模型的平均表现。两个模型有相同的结构,使用相同的训练过程,在同一个从训练数据里随机抽样而来的样本上来评估。用mixup训练的模型在预测训练数据之间的数据时更稳定。 (对离散样本空间进行连续化,提高邻域内的平滑性)
Figure 1b 显示了mixup 在类与类之间提供了更平滑的过渡线来估计不确定性。Figure 2 显示了两个神经网络(using ERM and mixup)在训练CIFAR-10 数据集上的平均表现。两个模型有着同样的结构,使用同样的步骤训练,在同样的训练数据中采样相同的点进行评估。使用mixup训练的模型在训练样本之间的模型预测和梯度模值更加稳定。
5.实验结果:
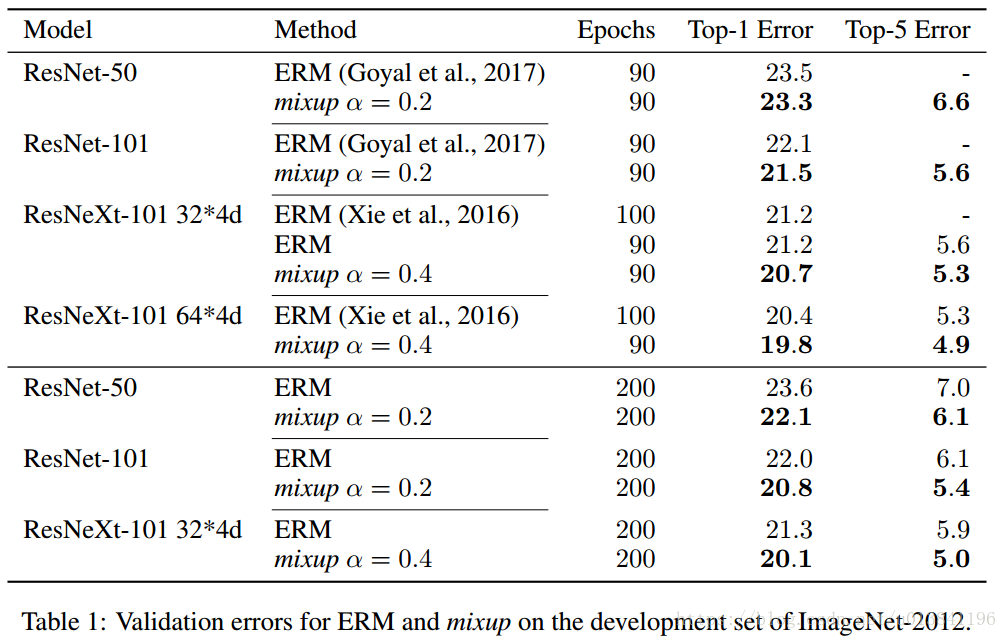
ERM 和 mixup 方法在ImageNet-2012 数据集上验证错误。
ERM 和 mixup 方法在CIFAR-10 数据集上测试错误。
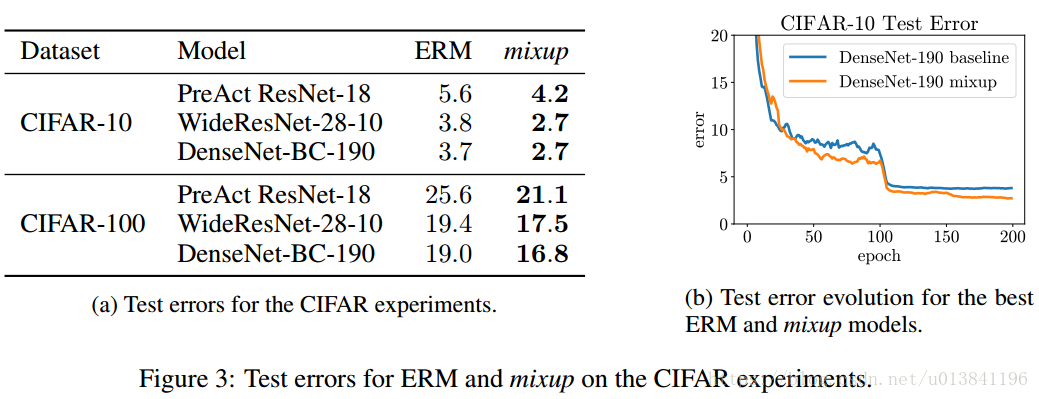
6.讨论:
在作者的实验中,有以下一贯的趋势:随着α的增加,在真实数据中的训练错误增加,同时泛化差距减小。这证明了作者的一个假设,mixup可以隐式地控制模型的复杂度。然而,作者并没有找到一个很好的方法在偏差-方差的平衡中找到最佳位置。举例来说,在CIFAR-10训练中,即使当α→∞时,在真实数据上的训练误差会非常低。然而在ImageNet 分类任务中,真实数据的训练误差在α→∞时会有明显上升。基于作者在ImageNet 和 Google commands 上使用不同网络结构做的实验,发现增大网络容量,可以使训练误差对大的α值敏感性降低,这给mixup 带来更多的优势。
mixup 对更加深入研究还有一些可能性。
1)可不可能在其他类型的监督学习问题,比如回归和结构化预测得到相似的理想效果?
2)能不能证明有相似的方法在监督学习(半监督,强化学习)之外也是很有效的?
7.总结:
在此研究中,作者提出了mixup,一个和数据无关的、简单的数据增强原则。研究结果表明,mixup是邻域风险最小化的一种形式,它在虚拟样本(即构建为训练集中的两个随机样本及其标签的线性插值)中进行训练。将mixup集成到现有的训练管道中仅需要几行代码,并且很少或几乎没有计算开销。在广泛的评估中,结果已经表明,mixup改进了当前最先进的模型在ImageNet、CIFAR、语音和表格数据集中的泛化误差。此外,mixup有助于有助于消除对错误标签的记忆、对对抗样本的敏感性以及对抗训练的不稳定性。
作者回答的一些问题:
作者:张宏毅
链接:https://www.zhihu.com/question/67472285/answer/256651581
来源:知乎
Q: 为什么data augmentation是理解为控制模型复杂度?
A: 准确地说,我觉得data augmentation既不能简单地理解为增加training data,也不能简单地理解为控制模型复杂度,而是两种效果兼而有之。考虑图像识别里常用的改变aspect ratio做data augmentation的方法,生成的图像虽然和真实图像相似,但是并不是来自于data distribution,更不是它的i.i.d.抽样。而经典的supervised learning以及统计学习理论的基本假设就是训练集和测试集都是data distribution的i.i.d.抽样,所以这并不是经典意义上的增加training data。这些合成的training data的作用,流行的解释是“增强模型对某种变换的invariance”。这句话反过来说,就是机器学习里经常提到的“减少模型估计的variance”,也就是控制了模型的复杂度。需要注意的是,L2正则化、dropout等等也都是在控制模型复杂度,只不过它们没有考虑数据本身的分布,而data augmentation属于更加机智的控制模型复杂度的方法。
其实反过来看,L2正则化和dropout也各自等价于某种data augmentation。参考Vicinal Risk Minimization 和 [1506.08700] Dropout as data augmentation。
Q: label线性加权后,不是得到了这两个样本中间的类别了吗?
A: label用的是one-hot vector编码,可以理解为对k个类别的每个类给出样本属于该类的概率。加权以后就变成了"two-hot",也就是认为样本同时属于混合前的两个类别。
另一种视角是不混合label,而是用加权的输入在两个label上分别计算cross-entropy loss,最后把两个loss加权作为最终的loss。由于cross-entropy loss的性质,这种做法和把label线性加权是等价的,大家可以自行思考一下。
mixup使用的x是raw input。在机器学习的语境里,进入分类器的输入x通常称为feature,这里feature并不是指神经网络隐藏层的activation,抱歉给一些读者造成了误会。有朋友想到对神经网络的中间层做插值,还想到在无标签的数据上预测标签然后进行混合——这都是非常吸引人的想法,我们其实也想到了而且进行了一些尝试,但是实验的效果不如mixup好。期待感兴趣的朋友继续探索。
意料之外但情理之中的尝试。大道至简。
让 NN 学到一个复杂度更低的函数一直是一个提高 generalization 的方式。重要的就是在训练数据中没有覆盖的空间上加上复杂度控制。这篇文章的想法直接做到了这一点,通过 data-augmentation 来让 NN 在“空白区域”学到一个简单的线性插值函数,大大降低了无数据覆盖空间的复杂度,简单有效的 idea,该点赞!
虽然是极其简单的想法,但恰恰非常合适的完成降低复杂度的目标。
从统计学习理论的角度看,generalization error就是training error(在没有经过data augmentation的训练集上的错误率)和generalization gap两部分。无论data augmentation还是regularization,都是通过控制模型复杂度减小generalization gap。如果同时又不明显增大training error,那就有望减小generalization error。我们在CIFAR-10 corrupt label实验上的结果表明,与dropout相比,mixup在random label上的training error相近(即overfitting或者说model complexity相近);但同时mixup可以比dropout在real label上达到明显更低的training error。这或许是mixup有效的本质原因。
至于为什么mixup可以在control overfitting的同时达到更低的training error,这是一个非常有价值的问题,我目前还不知道答案。
如果单看错误率,和Google的NASNet、Momenta的SE-Net相比,我们的结果确实“好像没有太惊艳”。如果想要得到惊艳的结果,可以尝试把以上工作中使用的各种方法也加进来。比如说,以上结果基于320320或者331331的输入(而我们的所有ImageNet实验都使用了224*224的输入),使用了更大的网络、label smoothing、dropout,NASNet使用了auxiliary classifier和running average of parameters,SE-Net使用了random rotation的data augmentation等等。
而我们在所有的实验中,只对baseline做了mixup这一个改动,而且采用了尽可能少的trick,目的是排除其他干扰因素,简单直接地展示mixup本身的效果。
参考:https://blog.csdn.net/ly244855983/article/details/78938667
https://blog.csdn.net/sumangshang/article/details/78675724