性能测试的分类
其实,性能测试还是一个相当大的分类,里边会包含多种类型的性能测试,我们从几个最常用的来分析一下:
负载测试:通过逐步加压的方式来确定系统的处理能力,确定系统能够承受的各项阀值。举个例子来说,我呢自己开了一家咖啡馆,雇佣了一名服务员(咳咳,有点抠门),负载测试呢就是我不断的扩大经营,咖啡馆越来越大,从无人问津一直做到了最火爆的咖啡馆,同时会有 100 桌客人,这时候我要看看这个服务员,在不断增加的工作量下完成工作的情况。
压力测试:如果说负载测试,是要在一个合理范围内看完成工作的情况,那么压力测试则是要看服务的临界点。所以这时候我决定了,不让这个服务员休息,而且不断的增加客人数量,超出了他能承受的极限,那这样我看看这个服务员会不会累坏、罢工或者辞职。
容量测试:负载和压力测试,都是在一定压力条件下我们来看服务的性能,而容量测试相反,是在一定性能目标的前提下,系统能够处理的最大能力。通过前边的测试呢,我决定把这个服务员录用了,但是我这个人特别注重用户体验,所以我希望用户点完咖啡以后能够在十分钟内拿到他的咖啡;在这样的条件下,我想知道这个服务员最多能够同时接待多少桌客户。
配置测试:这是通过对被测试软件的软硬件配置的测试,找到系统各项资源的最优分配原则。所以服务员还是这个服务员,那么我开始尝试调整座位的摆放、吧台托盘的位置、服务员的行走路线等等,在这个基础上找到最适合的布置方式。
OK,到这里,我相信你已经明白了什么是性能测试、我们为什么要去做性能测试以及性能测试有几种场景分类,最后的最后,如果你决定要学习性能测试了,需要哪些方面的基础呢?
- 掌握接口测试
- 有简单的编程能力
- 对网络基础、HTTP 请求、操作系统有一定了解
- 能够理解并分析系统的架构
- 有中间件、数据库的知识积累
- 能进行接口的抓包操作
这是你要掌握的一些基础技能,接下来,对于性能测试的学习包括:
- 性能测试工具使用
- 性能场景分析
- 性能应该关注哪些指标及相应的监控方式
- 性能测试的结果和瓶颈分析
- 如何调优的手段
如果你能够把上边的都一一搞定,那么性能测试基本可以认为是有所大成了。在后边呢,我不会一一去讲解这些知识,而是对一些大家需要注意的、忽略的点给予一些指引。
接下来我们要聊的就是我认为性能测试过程中最重要的工作:场景分析。如果没有合理正确的场景分析,那么性能测试的执行其实是没有任何意义的。
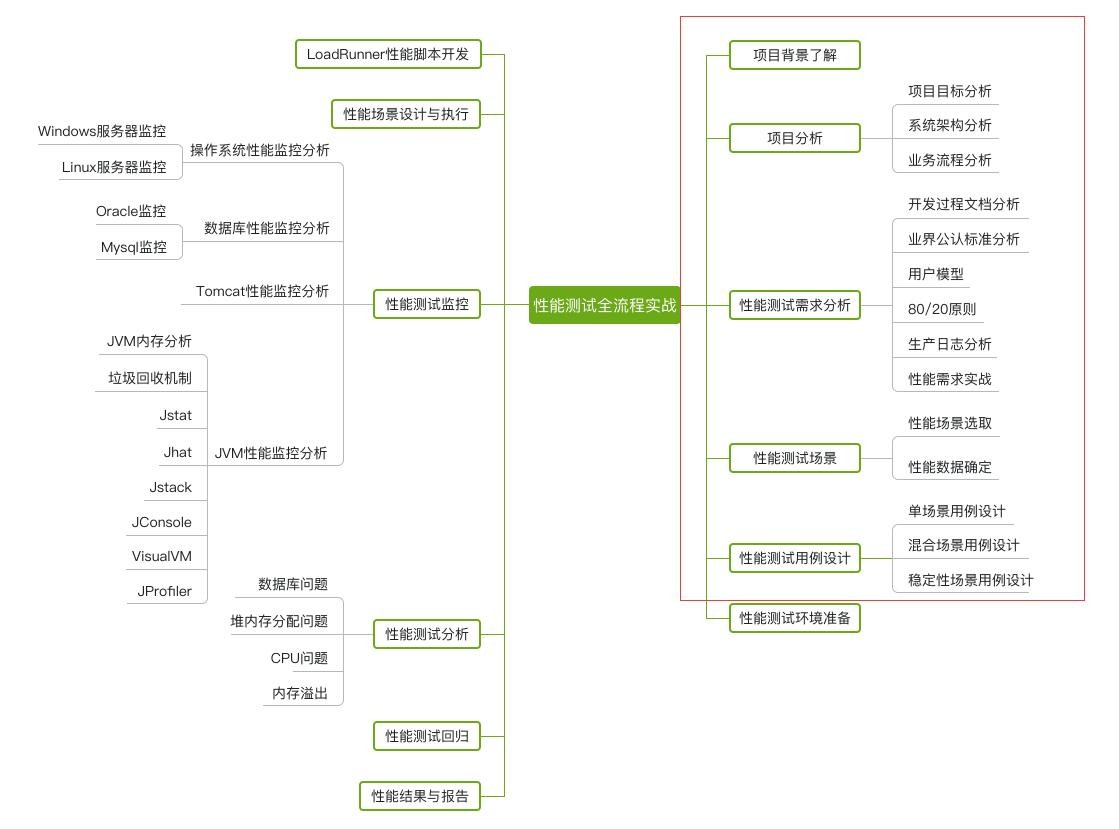
场景设计
有了前边的准备,对于厨师来说,要进行菜品的优化就显得相对简单了。重点在于到底哪些地方需要进行性能测试、这些场景操作的数据库中有没有存量数据要求、要求有多少、需求分析中需要的并发数、响应时间等指标又是多少。
先来确定下性能测试场景如何去选取:
- 用户量访问比较大的功能
- 与金钱相关比较重要的场景
- 影响业务主流程的场景
- 开发人员认为可能存在性能问题的场景
- 应该考虑综合场景,防止线程争用导致现场死锁以及数据库死锁
- 应该做稳定性场景测试,防止长时间运行导致的内存泄露情况发生
再来,是我们的性能数据量。这个比较简单,例如现有系统的用户量为 1w,我们需要系统支持未来的用户量为 10w,那么登录功能对应的用户数据表存量应为 10w 左右,在这个基础之上来规划我们的测试。同样,比如同一个网站的页面展示,对应现在的数据也进行 10 倍的放大来进行初始性能数据量的估算。
接下来就可以将三者结合起来,把场景、存量数据和性能需求合并起来,形成多个性能测试场景的用例设计。
OK,到这里,一个比较完整的性能场景分析过程就结束了。简单么?恐怕并不。性能的场景分析是我们面对一个性能测试最难以下手的一点,这里不仅仅是我在这里跟大家聊几句就可以的,而是需要大家不断在实践中积累自己的经验,逐步掌握性能测试最重要的一环:场景分析。
性能测试的本质
再说监控和调优之前,我们先来想一下我们进行性能测试的最终目的是什么?是给出性能结果么?
这当然是我们的目的之一,其实在我看来,本质上的目标主要分两个方面:
- 有没有足够的能力。这就是说我们来验证系统是不是符合我们想要的性能要求,比如我们预计的性能指标是 100w 存量用户、1w 同时在线、800 交易并发下能够控制响应时间在 3s 内,性能测试的目的,首先就是要看看现有情况下是否能够满足。
- 能力的规划。一般情况下很难一下子就满足,那么这就是怎么样才能让系统达到我们要求的性能能力。是不是可以通过增加服务器、修改配置、优化 SQL、修改程序等方式来提升系统能力,使性能达标。
在这两方面之中,更重要的就是后者,也就是通过监控调优的手段,让系统运行的更好,打破软件硬件方面的瓶颈。
系统可能存在的瓶颈
先来说说瓶颈,知己知彼方能百战不殆,再去监控它调试它之前我们先要做的就是了解它,知道什么地方可能出现问题。
从硬件的角度上说,一般可能存在瓶颈的点,包括磁盘空间不足,导致的运行速度下降、CPU、内存、磁盘 I/O 读写速率等方面。
软件的角度就包括多个方面,一方面是服务器方面的配置,比如由于 TOMCAT 或者 Weblogic 等中间件,连接池参数配置不合理会造成瓶颈;另一方面是应用自身,例如程序架构的不合理,代码不当引起的内存泄露、GC 不彻底等问题;最后一方面,应该算得上是性能测试里遇到瓶颈比较多的了,那就是数据库方面。包括数据库的索引、锁、不合理的表空间设计、慢 SQL 等等。
其实说起来应该还有一个地方,就是网络层面,但是由于我们的性能测试一般更多的是在局域网下进行,忽略网络影响,所以在测试过程中可以忽略。
性能测试的监控
由于上边提到的各方面的瓶颈,所以我们在进行性能测试的时候,一定要注意对软硬件方面的监控。我这里不去跟大家详细去说监控的细节,大体聊一下常用的监控点和工具。
- 操作系统监控:Windows 服务器 - Perfmon;Linux 服务器 - TOP / Nmon /netstat 等
- 数据库性能监控:Oracle - Spotlight on Oracle; Mysql - MySQLMTOP
- TOMCAT 监控:Lambda Probe
- JVM 监控: Jmap / Jstack / Jconsole / JProfiler 等
性能优化
优化其实是很难说清楚的一个点,也是在性能测试里很需要经验的地方,我们聊几种常见的场景:
Round 1 : 响应时间慢
这恐怕是我们遇到最多的场景,直观上看过去就是响应的非常慢。这个时候我们的调优方式就是把整个的 Response Time(RT)通过日志进行不断的分解,例如,我们现在是把一个 RPC(Dubbo)的服务部署在 Tomcat 中,上游用 Nginx 做反向代理。在这样的架构下,一个完整的 RT 就会包括前端 RT、网络传输时间、Nginx RT、Tomcat RT、Dubbo 服务 RT 和数据库 RT。如果存在问题,我们可以请开发配合在各个局部增加日志,观察具体响应时间慢的点,从而进行后续的优化动作。
Round 2 : TPS 波动大
一般来说,性能测试的 TPS 应该随着并发量的上升而呈跟随上升趋势直至稳定,但是有时候我们会发现,被测系统的 TPS 非常不稳定,上下波动非常大。排除网络可能造成的影响,在实际测试过程中可能遇到最大的可能就是:被压测服务器上存在其他运行的服务争抢资源或者垃圾回收的问题。
其中后者的可能性居多,一般都是出现有频繁的 FGC。这就是需要我们结合着对 JVM 监控的数据来进行分析,修改 JVM 内存参数或代码逻辑,达到优化的目的。
Round 3 : 开始加压正常,到某一个点突然开始出现错误,并越来越多
这种情况多数可能是由于服务器、中间件等配置的线程数、超时时间造成的影响,线程数过小,服务端同时可以处理的请求就少,自然到达一定的并发就会等待,最终超时错误。
Round 4 : 并发数增加,TPS 不增加,CPU 内存利用率都不高
这类问题我遇到过的更多时候是由于 数据库的慢 SQL 或者不恰当的代码或数据库锁机制造成的。 一般优先排查数据库 SQL 问题,通过数据库日志判断 SQL 执行时间,查看是否需要优化;如果 SQL 没有问题,那么就需要与开发同学一起沟通确认代码中是否有不恰当的同步锁等等。
当然,这都是经过不断总结到的经验来分析出来的常见的性能优化场景。那么如果你碰到一个性能问题,却不知道问题出在哪儿,一般情况下,我们排查问题的顺序是从上到下:先查服务器硬件瓶颈(CPU、内存、I/O),再看是否由于配置问题引起,接下来查看数据库、SQL 是否存在瓶颈,最后是应用代码逻辑、JVM。
同时,一定不要忘记另外一个点:前端性能。当你发现后端请求响应时间一切正常,但是通过前端访问仍然存在性能瓶颈的时候,一定不要忘记前端加载过程带来的影响,而针对前端性能的测试使用 YSlow 是比较方便的。
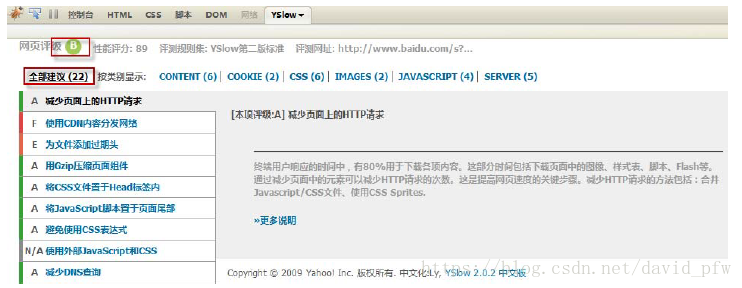
顺便也介绍一下,前端性能问题最常见的一些优化方式:
- 合并 HTTP 请求,减少请求数量
- 资源压缩
- 使用浏览器缓存
- 图片的优化:雪碧图等方式
当然,这里边只是介绍了一些性能监控与调优要关注的东西和一部分要点,并没有详细去跟大家说到底怎么监控、用什么命令、怎么去看,也没有去细节的讲每个部件到底怎么调优,所以,如果想要真正掌握性能测试,还需要真正上手去实验、去探索、“遇事不决找百度 ",这样才能搞定” 性能 “这座大山。