前面有写一篇——jmeter简单的压测案例,只能说是基础理论,跟实际应用还是有一点点差别。下面,从一个简单的实际应用中梳理思路。
测试对象:某个项目的订单号查询接口
压测目标:1分钟并发1000
准备工作:
1、先按照单个接口测试的模式写好要测试的接口,考虑到接口测试的完全覆盖,则包括查询成功和失败,也就是在脚本中一个线程组包含了两个接口的结果,分别是查询结果成功和查询结果失败(查询无记录)。

2、进行冒烟测试(执行这个线程组,确保脚本可正常使用)。
3、查询成功的请求参数,需让开发提供,根据开发提供的订单号,比如提供了9个有效的订单号,将这9个订单号复制到csv/txt文件中保存。脚本中的查询成功接口的请求参数“订单号”参数化,且在线程组添加一个csv数据文件设置,设置csv数据文件。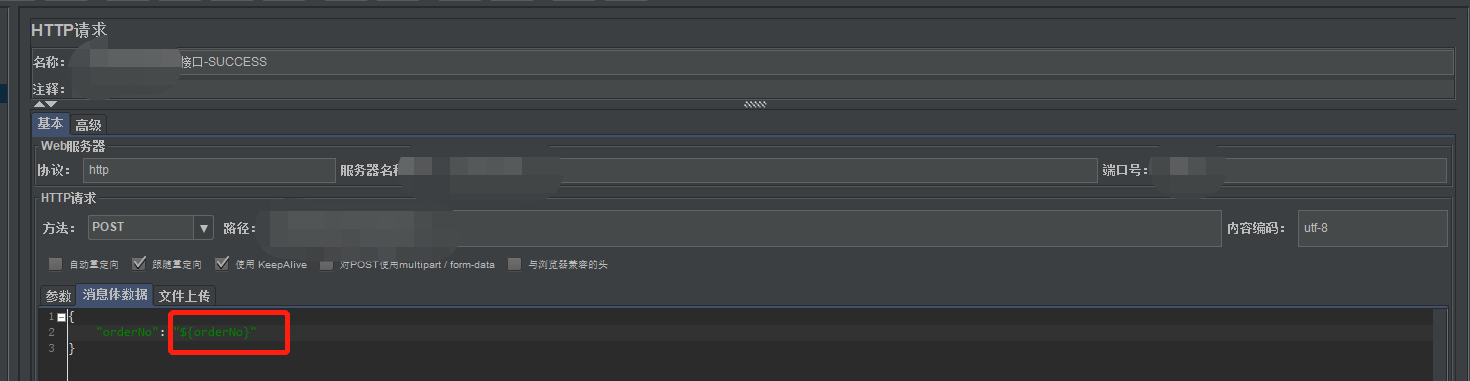
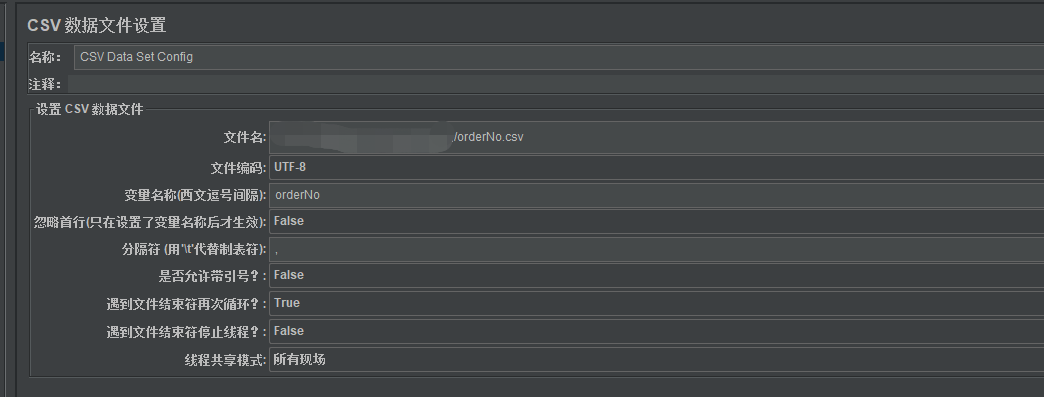
然后将线程组中的线程属性“线程数”设置为9。

查询失败接口的请求参数中的订单号写一个即可。(也就是订单号固定为一个无效的订单号即可)
进行冒烟测试(执行线程组,确保查询成功的脚本可正常使用(确保开发提供的订单号可用)),执行结果为:线程组总共执行9次,查询成功、查询失败各9次。
执行压测:
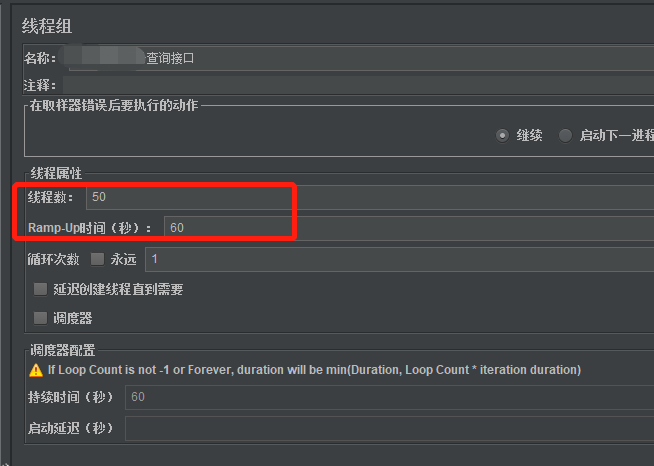
1、根据压测目标(1分钟并发1000),先执行1分钟并发50试试水。
跑压测脚本有2种方式:一种是GUI模式,即界面模式(在jmeter界面点击运行);一种是CLI模式(Command Line),即命令行模式(通过命令行执行压测脚本)。两者的区别是在生成的性能报告不同,通过命令行执行,所生成的报告可视化一些,而且命令行生成的性能数据更符合实际一点。推荐用CLI模式压测,GUI模式仅用于创建测试计划和调试脚本。
CLI模式压测:
执行脚本:jmeter -n -t mail_checking.jmx -l test.jtl
生成报告:jmeter -g test.jtl -e -o ./output
第一步,执行脚本前,先打开跑脚本的电脑的任务管理器,点击【性能】,查看本机cpu利用率。
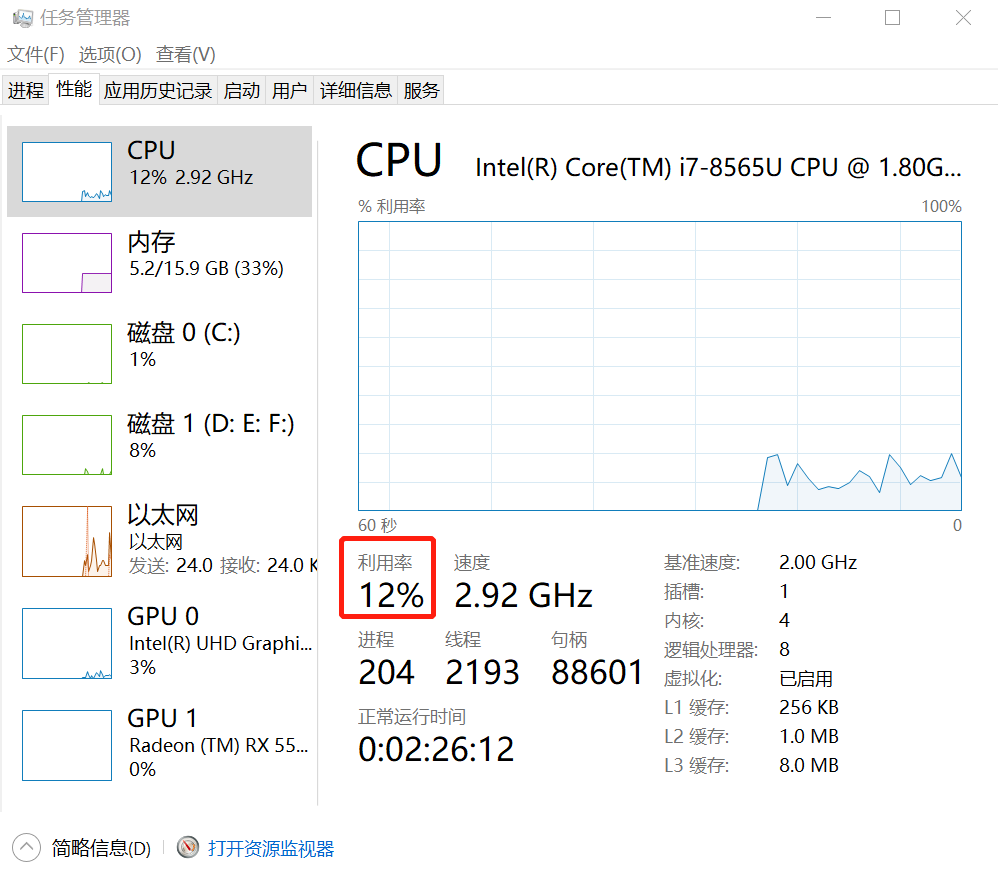
第二步,应用服务器的命令行输入:top -d1即可实时查看cpu信息。一般看第一行的%CPU数值。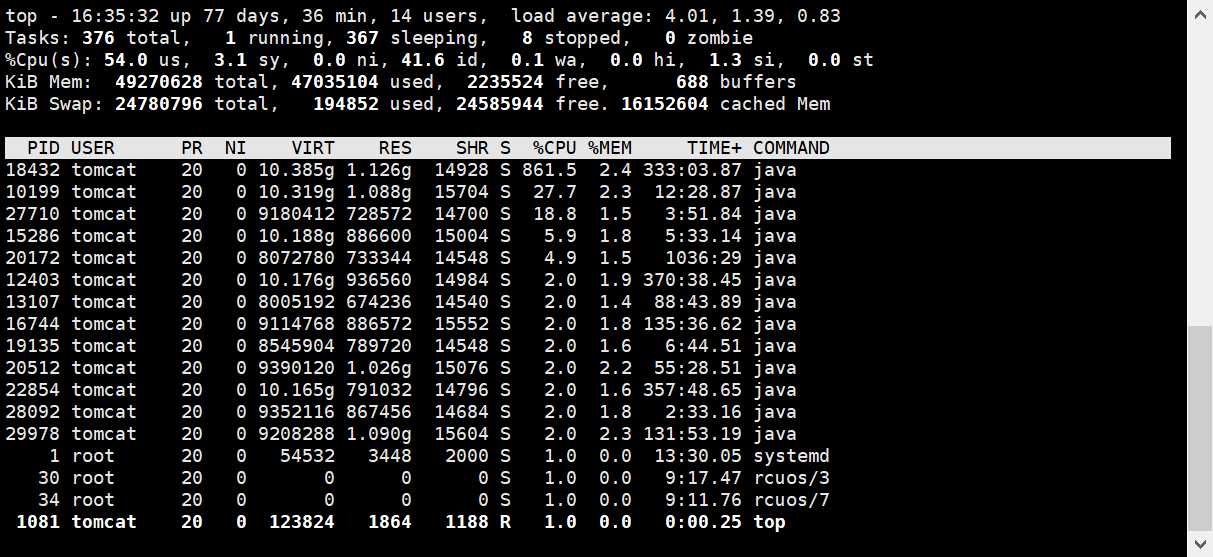
但由于top -d1拿到的是实时的,看不出脚本执行过程中的应用服务器的cpu占用率,所以需要安装监控工具。由于该项目的服务器是linux环境,我安装的是nmon。因为压测脚本是1分钟并发50,那么nmon需要监控的是1分钟的应用服务器的数据:./nmon -s10 -c60 -f -m /home/wechat/report,但建议监控的分钟数比1分钟大几秒,这样抓取到的数据才完整(因为要先执行nmon命令,再去操作压测脚本的执行,期间存在至少几秒钟的间隔):./nmon -s10 -c63 -f -m /home/wechat/report。
第三步,执行nmon命令后(不需要等nmon命令结束,因为我们要拿的就是跑压测脚本时,这个期间内应用服务器的信息),立即执行压测脚本。
在jmeter安装目录bin文件夹下,输入cmd,命令行输入:jmeter -n -t D:jmeter estProjectxxx.jmx -l D:jmeter estProject est.jtl,执行结束会生成2个文件。
第四步,压测脚本执行过程中,观察跑脚本的电脑的任务管理器中cpu利用率的变化和趋势。
第五步,压测脚本执行结束,命令行输入:jmeter -g D:jmeter estProject est.jtl -e -o D:jmeter estProjectoutput,此时会多一个文件夹,里面有个index.html文件,双击打开,这个就是可视化的jmeter报告了。

(由于之前做的压测已经结束了,不能随意操作应用服务器,所以下面这张图用的是之前做压测的jmeter报告,这个是并发200的,将就看下,大概知道个意思就可以)

第六步,查看服务器的nmon抓取数据的命令(./nmon -s10 -c63 -f -m /home/wechat/report)是否执行完毕,可通过ps -ef|grep nmon查看进程是否结束。如已结束,则将所生成的文件拉取到本地。并使用 将该文件转换为localhost_210105_1028.nmon.xlsx。
将该文件转换为localhost_210105_1028.nmon.xlsx。
第七步,分析报告中是否有报错,没报错且应用服务器没超过80%的话,可以继续加并发。
2、增加并发数,直到满足压测目标。压测报告后续再补。
需要注意的是:
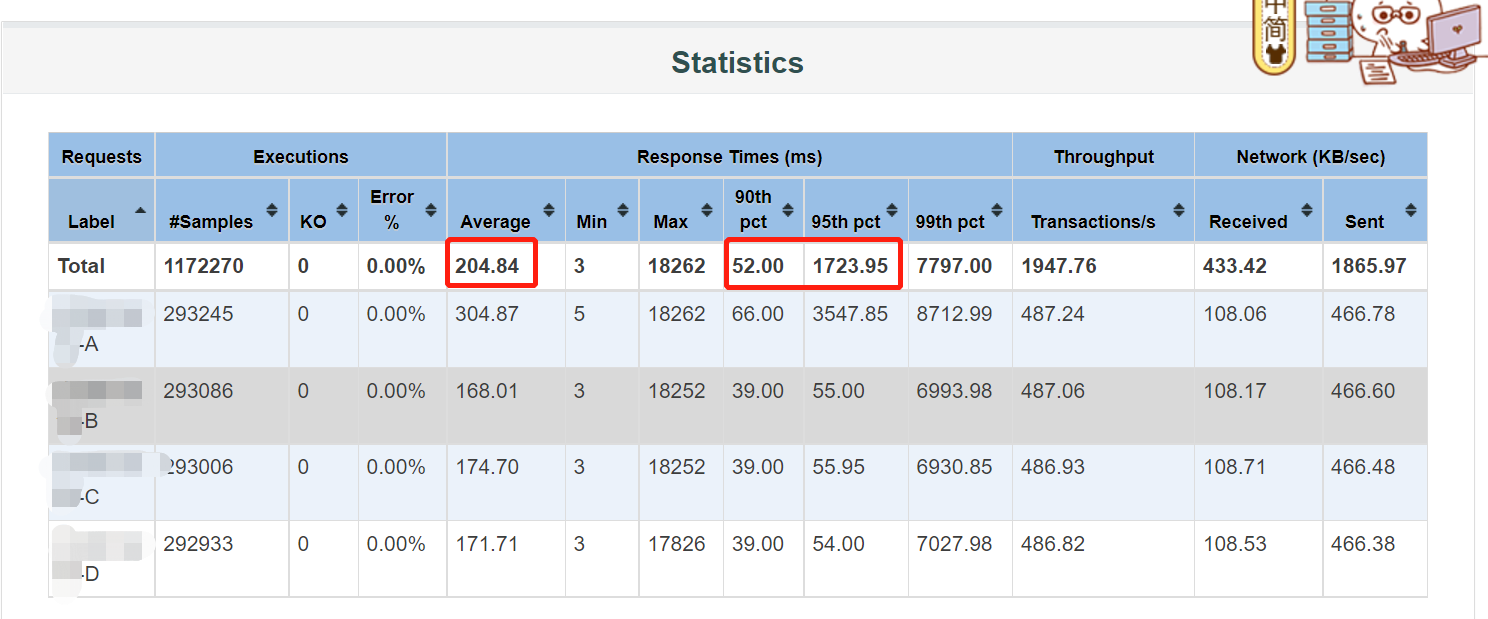
1、用命令行执行压测,生成的报告中,样本数(#Sample)是总请求数(包括了请求成功和请求失败的),假设压测结果有失败的请求,那么请求成功的数量=总数(#Sample)-错误数(KO)。
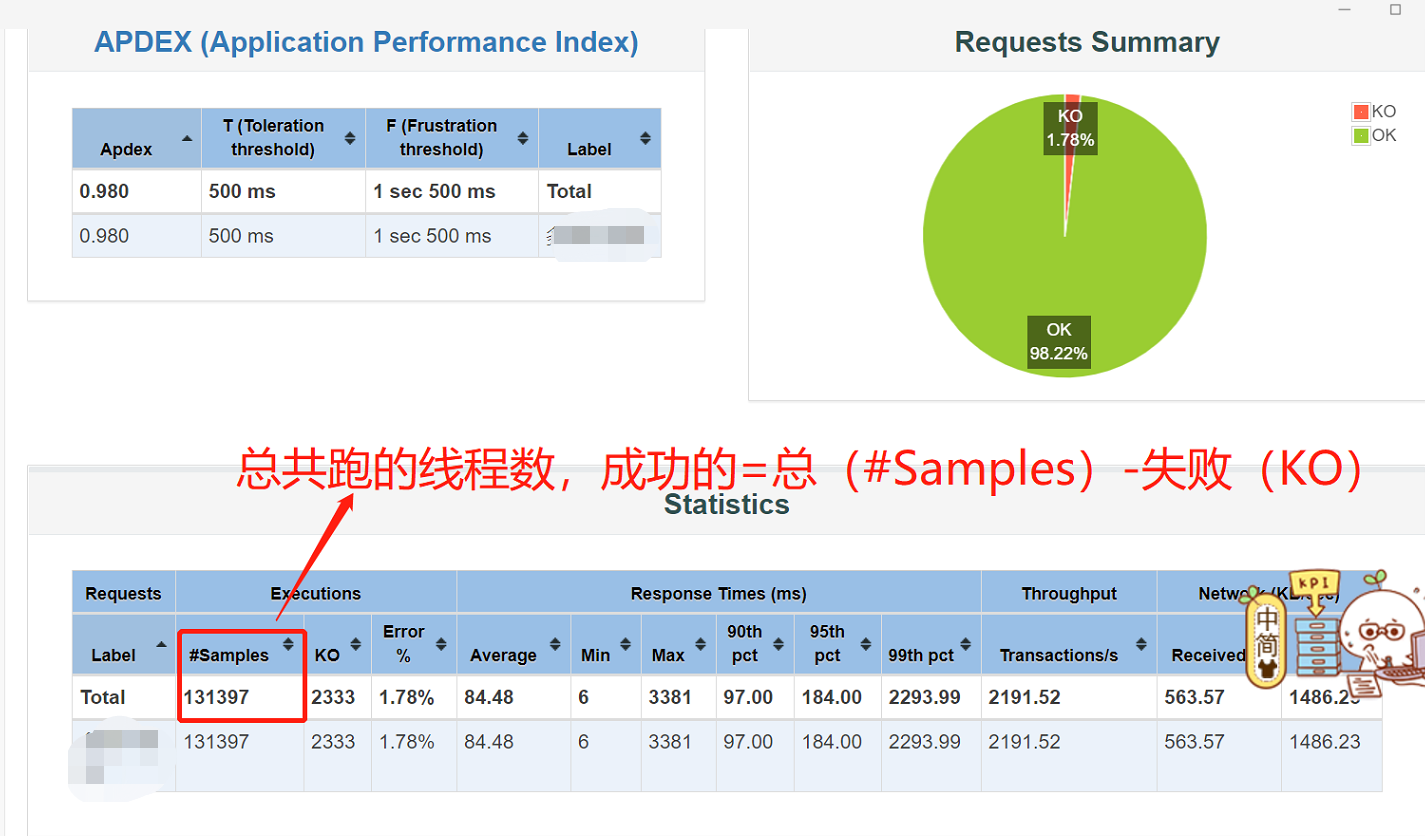
2、每次用命令行执行压测,可以将生成的test.jtl和output单独放一个文件夹,比如200_1s_5min,方便区分是在什么压测条件下执行的。或者每次执行前,将test.jtl和output删除。如果没有将每次执行的结果放一个文件夹,也没有将test.jtl和output删除,你会发现第一次执行的结果(比如并发了100个线程)生成的报告中的sample是100,第二次执行的结果(比如并发了25个线程),生成的报告中的sample是125。也就是不删除的话,报告生成的数据是错误的,它自动将上一次执行结果也统计进去了。

3、并发数1000以下,ramp-up时间一般设置为5s或10s,一般设置为5s。后续并发数是否超出1000,其实都不需要更改ramp-up的值。ramp-up主要跟跑脚本的电脑性能有关,判断该电脑的性能是否支持在xx秒内执行完规定的并发数。
4、我们从性能测试报告中,查看到平均响应时间、90%响应时间、95%响应时间都很正常,但99%响应时间比这三个值大很多,此时,去观察其响应时间图表的时候,发现响应时间在95%-100%之间飙高,这个现象是因为jmeter的机制导致。在规定的持续时间快结束时,jmeter还有一些快跑完或还没跑完的线程,一下子都堆在一起执行(也就导致了实际jmeter运行的时长会比设置的持续时间长一点点),导致在临近结束期间,跑脚本的电脑的cpu升高,响应时间也就飙升了,这是正常现象,可以不用理会。
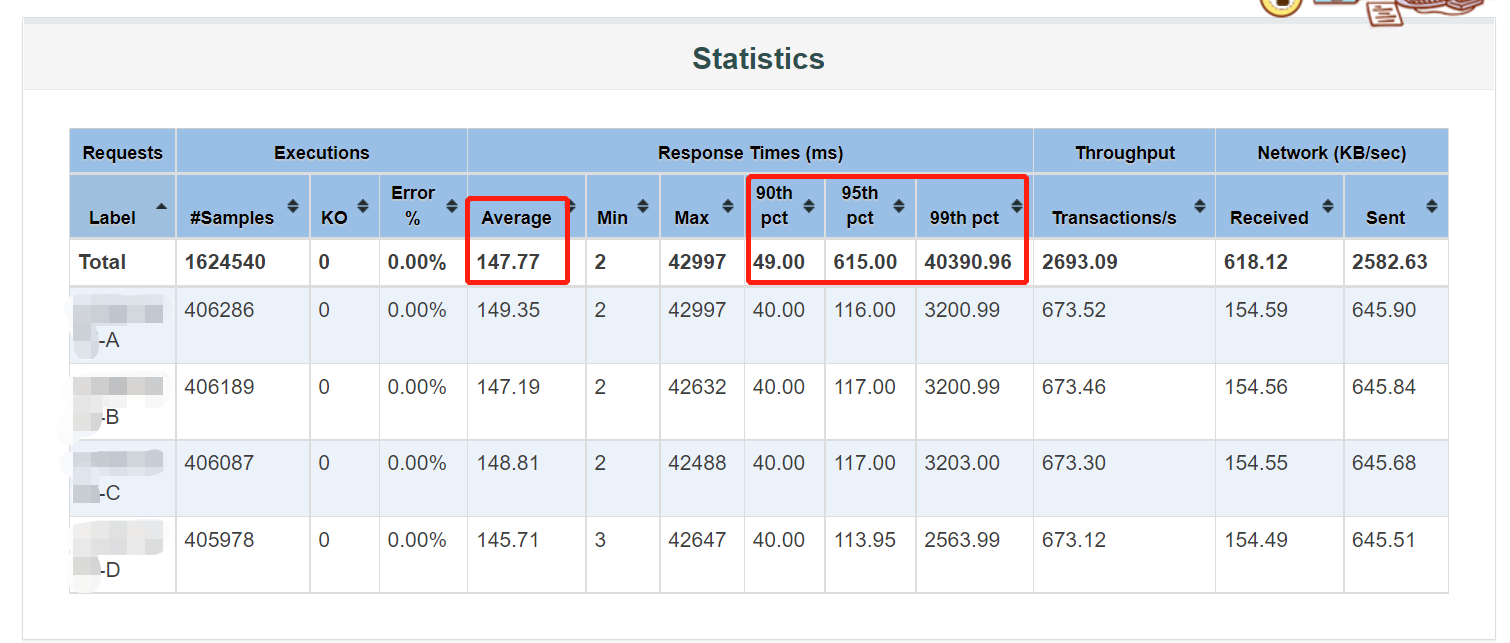
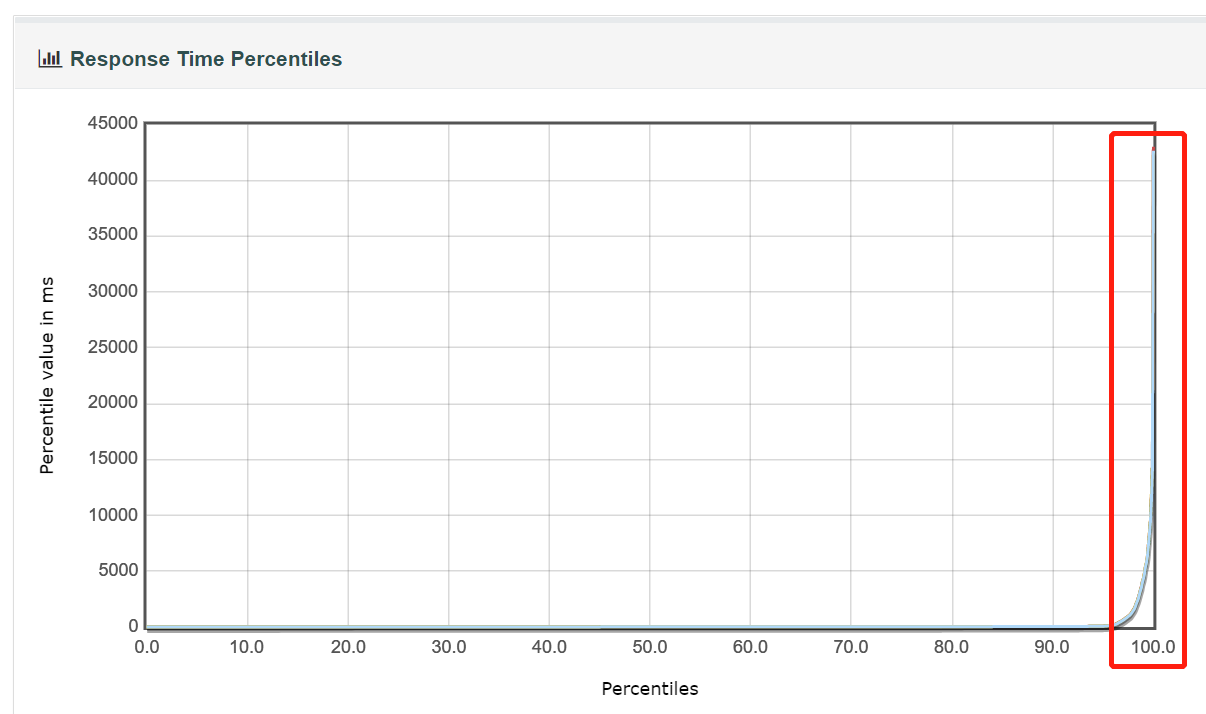
5、如果平均响应时间与90%响应时间、95%响应时间的差距较大,且其数值都达到3位数(响应时间单位为ms),那么平均响应时间不可作为主要参考,一般是以95%或90%作为一个主要参考值。我们需要观察响应时间的趋势图作进一步分析。
分2种情况考虑:
1)平均响应时间比90%响应时间或95%响应时间小很多,我们可以查看响应时间趋势图,观察其趋势是否平缓,若平缓上升,则考虑加大持续时间(一般这种情况只考虑加大持续时间,不会考虑加并发数),以拉长图表的横轴便于观察趋势。

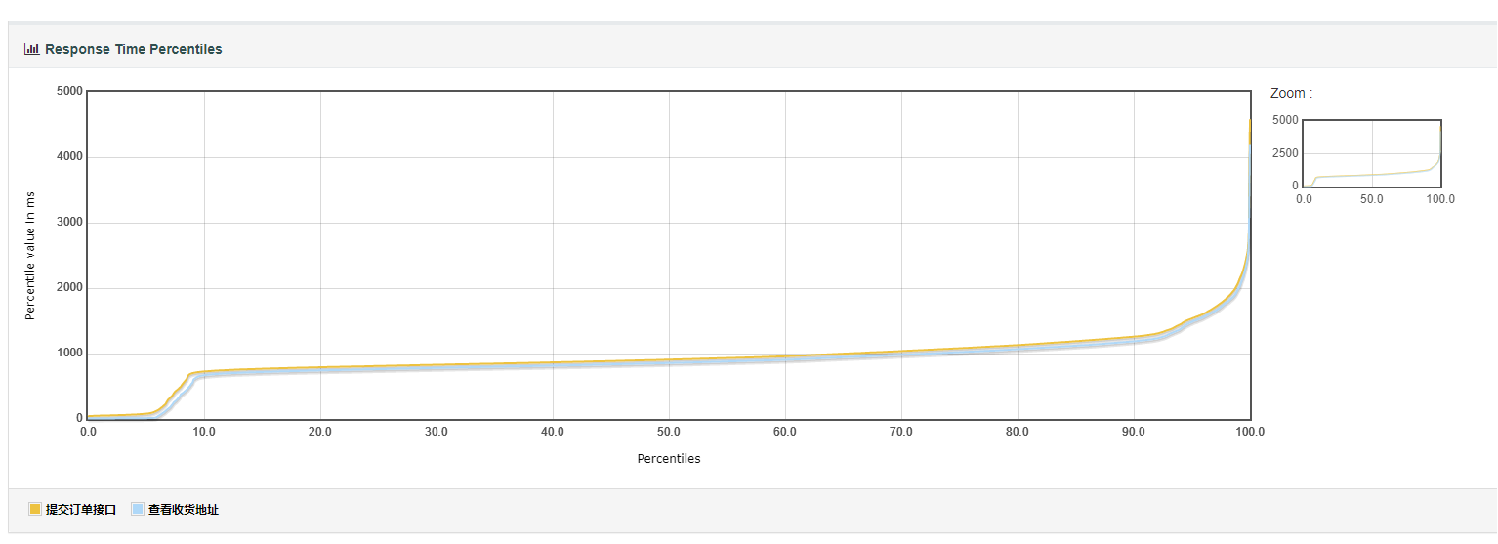
2)平均响应比 90%响应时间或95%响应时间大很多,我们可以查看响应时间趋势图,观察其趋势是否平缓。若前面平缓,快结束的时候突然上升,可能是跑jmeter脚本的电脑的性能问题,可考虑换一台性能更好的电脑,或者考虑分布式压测(多台电脑跑jemter脚本)。