简单介绍下flink、spark和storm的backpressure机制。
1、storm 反压
实现原理
Storm 是通过监控 Bolt 中的接收队列负载情况来实现反压:
- 如果一个executor发现recv queue负载超过高水位值(high watermark)就会通知反压线程(backpressure thread)。
- 反压线程将反压信息写到 Zookeeper。
- Zookeeper 上的 watch 会通知该拓扑(topo)的所有 Worker,该拓扑出现反压。
- Spout 减缓发送 tuple的速率。
问题:停止发送,等待系统回复,再次高速生产,然后再次停止发送,造成往数据流颠簸

2、spark 反压
spark streaming 是以微批次模拟流式处理,设置batch interval时间:
val ssc = new StreamingContext(sparkConf, Seconds(3))
如果batch process time大于batch interval time=3s,程序的处理能力不足,积累的数据越来越多,最终会造成Executor的OOM。
解决办法
静态限速 (spark 1.5 以前)
sparkConf.set("spark.streaming.kafka.maxRatePerPartition","10")
动态反压(spark 1.5 以后)
sparkConf.set("spark.streaming.backpressure.enabled","true")
实现原理
通过在Driver端进行速率估算,并将速率更新到Executor端的各个Receiver,从而实现反压。
速率控制:
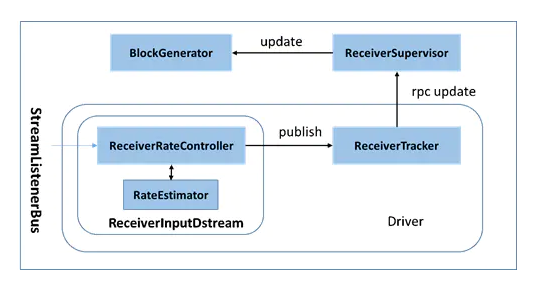
整个背压机制的核心,就是Drvier端的RateContoller,它作为控制核心,继承自StreamingListener,监听Batch的完成情况,记录下它们的关键延迟,然后传递给computeAndPublish方法,遍历Executor并进行速率估算和更新。
速率估算:
PIDRateEstimator是目前RateEstimator的唯一官方实现。PID(Proportional Integral Derivative,比例积分差分控制算法)是工控领域中,经过多次的验证是一种非常有效的工业控制器算法。Spark Streaming将它引入,作为根据最新的Rate,以及比例(Proportional) 积分(Integral)微分(Derivative)这3个变量,来确定最新的Rate。
速率更新:
计算完新Rate,就该把它发布出去了。
RateController通过ReceiverTracker,利用RPC消息,发布Rate到Receiver所在的Executor节点上,该节点上的ReceiverSupervisorImpl会接收消息,并把速率更新到BlockGenerator上,从而以控制每个批次的数据生成。
每个子任务都有自己的本地缓存池,收到的数据以及发出的数据,都会序列化之后,放入到缓冲池里。然后,两个TaskManager之间,只会建立一条物理链路(底层使用Netty通讯),所有子任务之间的通讯,都由这条链路承担。
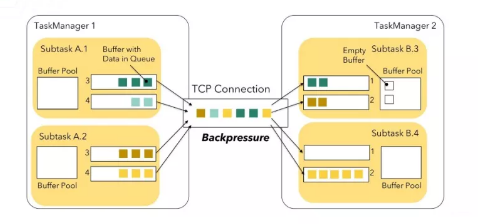
当任何一个子任务的发送缓存(不管是子任务自己的本地缓存,还是底层传输时Netty的发送缓存)耗尽时,发送方就会被阻塞,产生背压;同样,任何任务接收数据时,如果本地缓存用完了,都会停止从底层Netty那里读取数据,这样很快上游的数据很快就会占满下游的底层接收缓存,从而背压到发送端,形成对上游所有的任务的背压。
很显然,这种思路有个明显的问题,任务一个下游子任务的产生背压,都会影响整条TaskManager之间的链路,导致全链路所有子任务背压。比如上图的B.3子任务,此时还有处理能力,但也无法收到数据。
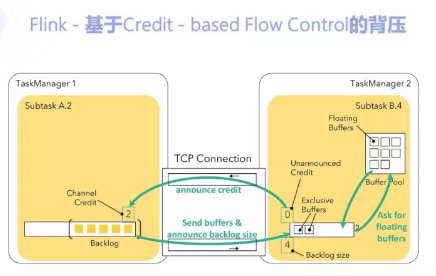
为了解决上节的单任务背压影响全链路的问题,在Flink 1.5之后,引入了Credit-based Flow Control,基于信用点的流量控制。
这种方法,首先把每个子任务的本地缓存分为两个部分,独占缓存(Exclusive Buffers)和浮动缓存(Floating Buffers);
然后,独占缓存的大小作为信用点发给数据发送方,发送方会按照不同的子任务分别记录信用点,并发送尽可能多数据给接收方,发送后则降低对应信用点的大小;
当信用点为0时,则不再发送,起到背压的作用。在发送数据的同时,发送方还会把队列中暂存排队的数据量发给接收方,接收方收到后,根据本地缓存的大小,决定是否去浮动缓存里请求更多的缓存来加速队列的处理,起到动态控制流量的作用。整个过程参考上图。
通过这样的设计,就实现了任务级别的背压:任意一个任务产生背压,只会影响这个任务,并不会对TaskManger上的其它任务造成影响。