1. 逻辑地址、线性地址和物理地址
1.1 逻辑地址
例如:假定我们有一个简单的C程序Hello.c
#include <stdio.h>
void greeting()
{
printf("hello,world.
");
}
int main(void)
{
greeting();
}之所以把这样简单的程序写成两个函数,是为了说明指令的转移过程。我们用gcc编译之后用Linux的实用程序objdump对其进行反汇编:
$objdump –d hello
得到其中一段片段:
0000000000400526 <greeting>:
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
40052a: bf d4 05 40 00 mov $0x4005d4,%edi
40052f: e8 cc fe ff ff callq 400400 <puts@plt>
400534: 90 nop
400535: 5d pop %rbp
400536: c3 retq
0000000000400537 <main>:
400537: 55 push %rbp
400538: 48 89 e5 mov %rsp,%rbp
40053b: b8 00 00 00 00 mov $0x0,%eax
400540: e8 e1 ff ff ff callq 400526 <greeting>
400545: b8 00 00 00 00 mov $0x0,%eax
40054a: 5d pop %rbp
40054b: c3 retq
40054c: 0f 1f 40 00 nopl 0x0(%rax)其中像400526这样的地址就是我们常说的逻辑地址,也就是虚拟地址。(参考文献中说在elf格式的可执行代码中,ld总是从0x8000000开始安排程序的“代码段”,对每个程序都是这样。我也不知道为什么我是这个地址开始的,有知道的大神可以指出,大家互相学习!)
逻辑地址(Logical Address) 是指由程序产生的与段相关的偏移地址部分。例如,你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址,不和绝对物理地址相干。只有在Intel实模式下,逻辑地址才和物理地址相等(因为实模式没有分段或分页机制,Cpu不进行自动地址转换);逻辑也就是在Intel 保护模式下程序执行代码段限长内的偏移地址(假定代码段、数据段如果完全一样)。应用程序员仅需与逻辑地址打交道,而分段和分页机制对您来说是完全透明的,仅由系统编程人员涉及。应用程序员虽然自己可以直接操作内存,那也只能在操作系统给你分配的内存段操作。
如果是程序员,那么逻辑地址对你来说应该是轻而易举就可以理解的。我们在写C代码的时候经常说我们定义的结构体首地址的偏移量,函数的入口偏移量,数组首地址等等。当我们在考究这些概念的时候,其实是相对于你这个程序而言的。并不是对于整个操作系统而言的。也就是说,逻辑地址是相对于你所编译运行的具体的程序(或者叫进程吧,事实上在运行时就是当作一个进程来执行的)而言。你的编译好的程序的入口地址可以看作是首地址,而逻辑地址我们通常可以认为是在这个程序中,编译器为我们分配好的相对于这个首地址的偏移,或者说以这个首地址为起点的一个相对的地址值。
当我们双击一个可执行程序时,就是给操作系统提供了这个程序运行的入口地址。之后shell把可执行文件的地址传入内核。进入内核后,会fork一个新的进程出来,新的进程首先分配相应的内存区域。这里会碰到一个著名的概念叫做Copy On Write,即写时复制技术。这里不详细讲述,总之新的进程在fork出来之后,新的进程也就获得了整个的PCB结构,继而会调用exec函数转而去将磁盘中的代码加载到内存区域中。这时候,进程的PCB就被加入到可执行进程的队列中,当CPU调度到这个进程的时候就真正的执行了。
我们大可以把程序运行的入口地址理解为逻辑地址的起始地址,也就是说,一个程序的开始的地址。以及以后用到的程序的相关数据或者代码相对于这个起始地址的位置(这是由编译器事先安排好的),就构成了我们所说的逻辑地址。逻辑地址就是相对于一个具体的程序(事实上是一个进程,即程序真正被运行时的相对地址)而言的。尽管我们这样理解可能有一些细节上的偏差,但是比起网上一些含糊其辞,让人不知所云的描述要好得多,实用得多,等到自己对这个地址有更加深刻的理解的时候,再对上面的理解进行一些补充或者纠正。
总之一句话,逻辑地址是相对于应用程序而言的。
逻辑地址产生的历史背景:
追根求源,Intel的8位机8080CPU,数据总线(DB)为8位,地址总线(AB)为16位。那么这个16位地址信息也是要通过8位数据总线来传送,也是要在数据通道中的暂存器,以及在CPU中的寄存器和内存中存放的,但由于AB正好是
DB的整数倍,故不会产生矛盾!但当上升到16位机后,Intel8086/8088CPU的设计由于当年IC集成技术和外封装及引脚技术的限制,不能超过40个引脚。但又感觉到8位机原来的地址寻址能力2^16=64KB太少了,但直接增加到16的整数倍即令AB=32位又是达不到的。故而只能把AB暂时增加4条成为20条。则 2^20=1MB的寻址能力已经增加了16倍。但此举却造成了AB的20位和DB的16位之间的矛盾,20位地址信息既无法在DB上传送,又无法在16位的CPU寄存器和内存单元中存放。于是应运而生就产生了CPU段结构的原理
1.2 线性地址
线性地址(Linear Address) 是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或者说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址可以再经变换以产生一个物理地址。若没有启用分页机制,那么线性地址直接就是物理地址。Intel 80386的线性地址空间容量为4G(2的32次方即32根地址总线寻址)。
我们知道每台计算机有一个CPU(我们从单CPU来说吧。多CPU的情况应该是雷同的),最终所有的指令操作或者数据等等的运算都得由这个CPU来进行,而与CPU相关的寄存器就是暂存一些相关信息的存储记忆设备。因此,从CPU的角度出发的话,我们可以将计算机的相关设备或者部件简单分为两类:一是数据或指令存储记忆设备(如寄存器,内存等等),一种是数据或指令通路(如地址线,数据线等等)。线性地址的本质就是“CPU所看到的地址”。如果我们追根溯源,就会发现线性地址的就是伴随着Intel的X86体系结构的发展而产生的。当32位CPU出现的时候,它的可寻址范围达到4GB,而相对于内存大小来说,这是一个相当巨大的数字,我们也一般不会用到这么大的内存。那么这个时候CPU可见的4GB空间和内存的实际容量产生了差距。而线性地址就是用于描述CPU可见的这4GB空间。我们知道在多进程操作系统中,每个进程拥有独立的地址空间,拥有独立的资源。但对于某一个特定的时刻,只有一个进程运行于CPU之上。此时,CPU看到的就是这个进程所占用的4GB空间,就是这个线性地址。而CPU所做的操作,也是针对这个线性空间而言的。之所以叫线性空间,大概是因为人们觉得这样一个连续的空间排列成一线更加容易理解吧。其实就是CPU的可寻址范围。
对linux而言,CPU将4GB划分为两个部分,0-3GB为用户空间(也可以叫核外空间),3-4GB为内核空间(也可以叫核内空间)。操作系统相关的代码,即内核部分的代码数据都会映射到内核空间,而用户进程则会映射到用户空间。至于系统是如何将线性地址转换到实际的物理内存上,那是另外的话题了。
1.3 物理地址
物理地址(Physical Address) 是指出现在CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。说白了就是内存地址。
1.4 逻辑地址转换线性地址(分段机制)
机器语言指令中出现的内存地址,都是逻辑地址,需要转换成线性地址,再经过MMU(CPU中的内存管理单元)转换成物理地址才能够被访问到。
我们写个最简单的hello world程序,用gccs编译,再反编译后会看到以下指令:
mov 0x80495b0, %eax
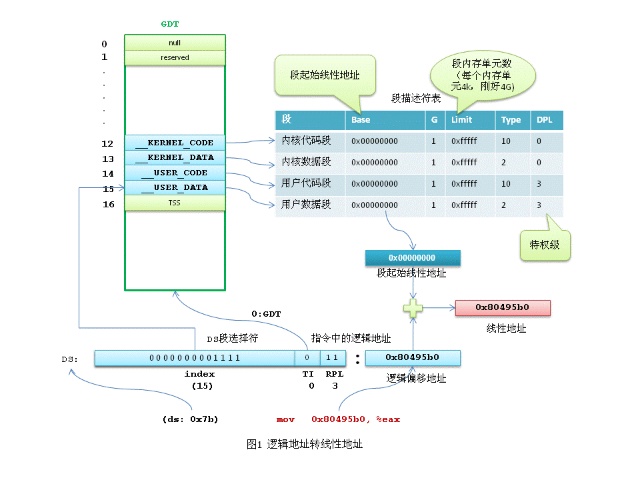
这里的内存地址0x80495b0 就是一个逻辑地址,必须加上隐含的DS 数据段的基地址,才能构成线性地址。也就是说0x80495b0 是当前任务的DS数据段内的偏移。
在x86保护模式下,段的信息(段基线性地址、长度、权限等)即段描述符占8个字节,段信息无法直接存放在段寄存器中(段寄存器只有2字节)。Intel的设计是段描述符集中存放在GDT或LDT中,而段寄存器存放的是段描述符在GDT或LDT内的索引值(index)。
Linux中逻辑地址等于线性地址。为什么这么说呢?因为Linux所有的段(用户代码段、用户数据段、内核代码段、内核数据段)的线性地址都是从 0x00000000 开始,长度4G,这样 线性地址=逻辑地址+ 0x00000000,也就是说逻辑地址等于线性地址了。
虽然都说linux不使用分段机制,但是分段机制属于CPU的一个功能,即使linux不使用,也要通过代码想办法绕过它,况且linux也使用到了分段机制中的某些功能。
分段机制主要功能只有两点:
1.将物理内存划分为多个段,让操作系统可以使用大于其地址线对应的物理内存(比如正常情况下32位地址线可以访问4G大小的内存,但是有分段后则可访问大于4G的内存)。
2.权限控制,将每个段设置权限位,让不同的程序访问不同的段。
对于linux内核来说,它仅仅只使用了分段机制中的权限控制功能
这样的情况下Linux只用到了GDT,不论是用户任务还是内核任务,都没有用到LDT。GDT的第12和13项段描述符是__KERNEL_CS 和__KERNEL_DS,第14和15项段描述符是 __USER_CS 和__USER_DS。内核任务使用__KERNEL_CS 和__KERNEL_DS,所有的用户任务共用__USER_CS 和__USER_DS,也就是说不需要给每个任务再单独分配段描述符。内核段描述符和用户段描述符虽然起始线性地址和长度都一样,但DPL(描述符特权级)是不一样的。__KERNEL_CS 和__KERNEL_DS 的DPL值为0(最高特权),__USER_CS 和__USER_DS的DPL值为3。
用gdb调试程序的时候,用info reg 显示当前寄存器的值:
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
可以看到ds值为0x7b, 转换成二进制为 00000000 01111011,TI字段值为0,表示使用GDT,GDT索引值为 01111,即十进制15,对应的就是GDT内的__USER_DATA 用户数据段描述符。
从上面可以看到,Linux在x86的分段机制上运行,却通过一个巧妙的方式绕开了分段。
1.5 线性地址转换物理地址(分页机制)
前面说了Linux中逻辑地址等于线性地址,那么线性地址怎么对应到物理地址呢?这个大家都知道,那就是通过分页机制,具体的说,就是通过页表查找来对应物理地址。
准确的说分页是CPU提供的一种机制,Linux只是根据这种机制的规则,利用它实现了内存管理。
在保护模式下,控制寄存器CR0的最高位PG位控制着分页管理机制是否生效,如果PG=1,分页机制生效,需通过页表查找才能把线性地址转换物理地址。如果PG=0,则分页机制无效,线性地址就直接做为物理地址。
分页的基本原理是把内存划分成大小固定的若干单元,每个单元称为一页(page),每页包含4k字节的地址空间(为简化分析,我们不考虑扩展分页的情况)。这样每一页的起始地址都是4k字节对齐的。为了能转换成物理地址,我们需要给CPU提供当前任务的线性地址转物理地址的查找表,即页表(page table)。注意,为了实现每个任务的平坦的虚拟内存,每个任务都有自己的页目录表和页表。
为了节约页表占用的内存空间,x86将线性地址通过页目录表和页表两级查找转换成物理地址。
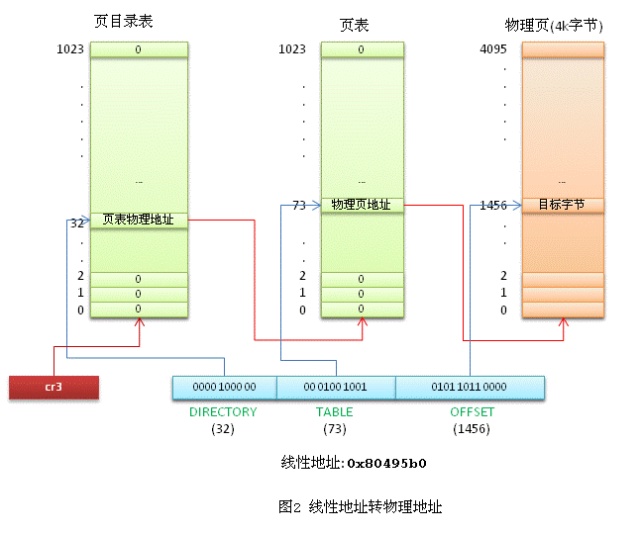
32位的线性地址被分成3个部分:
最高10位 Directory 页目录表偏移量,中间10位 Table是页表偏移量,最低12位Offset是物理页内的字节偏移量。
页目录表的大小为4k(刚好是一个页的大小),包含1024项,每个项4字节(32位),项目里存储的内容就是页表的物理地址。如果页目录表中的页表尚未分配,则物理地址填0。
页表的大小也是4k,同样包含1024项,每个项4字节,内容为最终物理页的物理内存起始地址。
每个活动的任务,必须要先分配给它一个页目录表,并把页目录表的物理地址存入cr3寄存器。页表可以提前分配好,也可以在用到的时候再分配。
还是以 mov 0x80495b0, %eax 中的地址为例分析一下线性地址转物理地址的过程。
前面说到Linux中逻辑地址等于线性地址,那么我们要转换的线性地址就是0x80495b0。转换的过程是由CPU自动完成的,Linux所要做的就是准备好转换所需的页目录表和页表(假设已经准备好,给页目录表和页表分配物理内存的过程很复杂,后面再分析)。
内核先将当前任务的页目录表的物理地址填入cr3寄存器。
线性地址 0x80495b0 转换成二进制后是 0000 1000 0000 0100 1001 0101 1011 0000,最高10位0000 1000 00的十进制是32,CPU查看页目录表第32项,里面存放的是页表的物理地址。线性地址中间10位00 0100 1001 的十进制是73,页表的第73项存储的是最终物理页的物理起始地址。物理页基地址加上线性地址中最低12位的偏移量,CPU就找到了线性地址最终对应的物理内存单元。
我们知道Linux中用户进程线性地址能寻址的范围是0 - 3G,那么是不是需要提前先把这3G虚拟内存的页表都建立好呢?一般情况下,物理内存是远远小于3G的,加上同时有很多进程都在运行,根本无法给每个进程提前建立3G的线性地址页表。Linux利用CPU的一个机制解决了这个问题。进程创建后我们可以给页目录表的表项值都填0,CPU在查找页表时,如果表项的内容为0,则会引发一个缺页异常,进程暂停执行,Linux内核这时候可以通过一系列复杂的算法给分配一个物理页,并把物理页的地址填入表项中,进程再恢复执行。当然进程在这个过程中是被蒙蔽的,它自己的感觉还是正常访问到了物理内存。
1.6 总结
作者:龚黎明
链接:https://www.zhihu.com/question/41431386/answer/91115537
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
逻辑地址是给操作系统之上的软件看的。他们不需要知道硬件是怎么设计的,只需要一台理想的虚拟机就可以了。这样是为了同样的软件应用于不同的硬件上。
线性地址是给CPU看的。CPU不需要知道有多少外设,什么种类的外设,反正它都是用地址来访问。打印机也好,硬盘也好,游戏手柄也好,内存也好,任何乱七八糟的外设也好,它都是分配个地址来访问。这叫做统一编址,也属于线性编址。让所有的外设,都可以像访问内存一样,线性访问。目的是为了让CPU可以接各种外设,不需要知道外设是怎么实现的。比如说硬盘,根本就不是线性地址,其有多个扇面,扇面又被划分成很多小块,磁头的移动绝对不是线性的。你不需要知道硬盘是怎么样的物理结构,你只需要把它想象成一排格子,每一格是一个sector。你甚至不需要知道硬盘只能以sector读写,你也可以只读写一字节,硬盘控制器会帮你搞定你想要的。简言之,线性地址能让CPU把任何设备当成内存。
物理地址是给实际的硬件看的。光驱控制器给读写头的控制信号,硬盘控制器给磁头发出的读写地址,内存总线上的地址是物理地址。硬件只对这个地址做响应。
2. Linux进程空间地址
2.1 概述
Linux的虚拟地址空间范围为0~4G,Linux内核将这4G字节的空间分为两部分,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF)供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF)供各个进程使用,称为“用户空间。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。
Linux使用两级保护机制:0级供内核使用,3级供用户程序使用,每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的,最高的1GB字节虚拟内核空间则为所有进程以及内核所共享。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。
现代的操作系统都处于32位保护模式下。每个进程一般都能寻址4G的物理空间。但是我们的物理内存一般都是几百M,进程怎么能获得4G 的物理空间呢?这就是使用了虚拟地址的好处,通常我们使用一种叫做虚拟内存的技术来实现,虚拟内存(Virtual Memory) 是指计算机呈现出要比实际拥有的内存大得多的内存量。因此它允许程序员编制并运行比实际系统拥有的内存大得多的程序。这使得许多大型项目也能够在具有有限内存资源的系统上实现。一个很恰当的比喻是:你不需要很长的轨道就可以让一列火车从上海开到北京。你只需要足够长的铁轨(比如说3公里)就可以完成这个任务。采取的方法是把后面的铁轨立刻铺到火车的前面,只要你的操作足够快并能满足要求,列车就能象在一条完整的轨道上运行。这也就是虚拟内存管理需要完成的任务。
Linux系统对自身进行了划分,一部分核心软件独立于普通应用程序,运行在较高的特权级别上,它们驻留在被保护的内存空间上,拥有访问硬件设备的所有权限,Linux将此称为内核空间。
相对地,应用程序则是在“用户空间”中运行。运行在用户空间的应用程序只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,也不能直接访问内核空间和硬件设备,以及其他一些具体的使用限制。
将用户空间和内核空间置于这种非对称访问机制下有很好的安全性,能有效抵御恶意用户的窥探,也能防止质量低劣的用户程序的侵害,从而使系统运行得更稳定可靠。
内核空间在页表中拥有较高的特权级(ring2或以下),因此只要用户态的程序试图访问这些页,就会导致一个页错误(page fault)。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存,内核代码和数据总是可寻址的,随时准备处理中断和系统调用。与之相反,用户模式地址空间的映射随着进程切换的发生而不断的变化。
2.2 Linux内核空间
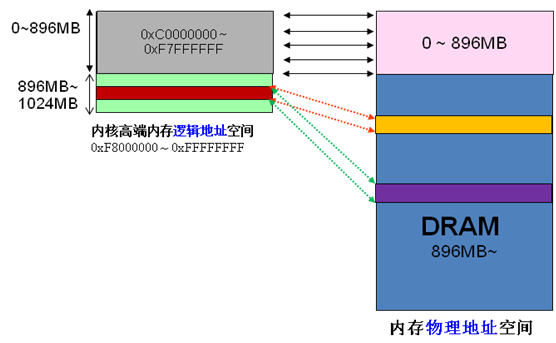
在x86结构中,Linux内核虚拟地址空间划分0~3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。内核虚拟空间(3G~4G)又划分为三种类型的区:
ZONE_DMA 3G之后起始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
由于内核的虚拟和物理地址只差一个偏移量:物理地址 = 逻辑地址 – 0xC0000000。所以如果1G内核空间完全用来线性映射,显然物理内存也只能访问到1G区间,这显然是不合理的。HIGHMEM就是为了解决这个问题,专门开辟的一块不必线性映射,可以灵活定制映射,以便访问1G以上物理内存的区域。映射关系如下图:
内核空间具体1GB内存分配如下图:
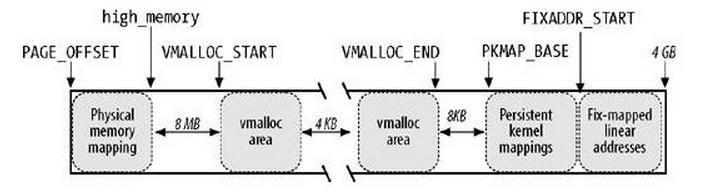
先说明图中符号的含义:
PAGE_OFFSET:0XC0000000,即3GB
high_memory:这个变量的字面含义是高端内存,到底什么是高端内存,Linux内核规定,RAM的前896为所谓的低端内存,而896~1GB共128MB为高端内存。如果你的内存是512M,那么high_memory是多少?是3GB+512,也就是说,物理地址x<=896M,就有内核地址0xc0000000+x,否则,high_memory=0xc0000000+896M
或者说high_memory最大值为0xc0000000+896M ,实际值为0xc0000000+x
在源代码中函数mem_init中,有这样一行:
high_memory = (void ) __va(max_low_pfn PAGE_SIZE);
其中,max_low_pfn为物理内存的最大页数。
所以在图中,PAGE_OFFSET到high_memory之间就是所谓的物理内存映射。只有这一段之间,物理地址与虚地址之间是简单的线性关系。还要说明的是,要在这段内存分配内存,则调用kmalloc()函数。反过来说,通过kmalloc()分配的内存,其物理页是连续的。
高端内存的划分,又如下图:
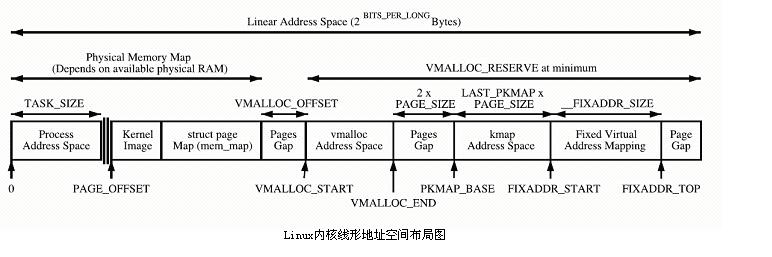
内核直接映射空间 PAGE_OFFSET~VMALLOC_START,kmalloc和__get_free_page()分配的是这里的页面。二者是借助slab分配器,直接分配物理页再转换为逻辑地址(物理地址连续)。适合分配小段内存。此区域 包含了内核镜像、物理页框表mem_map等资源。
内核动态映射空间 VMALLOC_START~VMALLOC_END,被vmalloc用到,可表示的空间大。
内核永久映射空间 PKMAP_BASE ~ FIXADDR_START,kmap
内核临时映射空间 FIXADDR_START~FIXADDR_TOP,kmap_atomic
vmalloc()与 kmalloc()都是在内核代码中用来分配内存的函数,但二者有何区别?
从前面的介绍已经看出,这两个函数所分配的内存都处于内核空间,即从3GB~4GB;但位置不同,kmalloc()分配的内存处于3GB~high_memory之间,这一段内核空间与物理内存的映射一一对应,而vmalloc()分配的内存在VMALLOC_START~4GB之间,这一段非连续内存区映射到物理内存也可能是非连续的。
vmalloc()工作方式与kmalloc()类似,其主要差别在于前者分配的物理地址无需连续,而后者确保页在物理上是连续的(虚地址自然也是连续的)。
尽管仅仅在某些情况下才需要物理上连续的内存块,但是,很多内核代码都调用kmalloc(),而不是用vmalloc()获得内存。这主要是出于性能的考虑。vmalloc()函数为了把物理上不连续的页面转换为虚拟地址空间上连续的页,必须专门建立页表项。还有,通过vmalloc()获得的页必须一个一个的进行映射(因为它们物理上不是连续的),这就会导致比直接内存映射大得多的缓冲区刷新。因为这些原因,vmalloc()仅在绝对必要时才会使用——典型的就是为了获得大块内存时,例如,当模块被动态插入到内核中时,就把模块装载到由vmalloc()分配的内存上。
3. 外部设备存储地址映射
随着计算机技术的发展,人们发现单纯的I/O映射方式是不能满足要求的。此种方式只适合于早期的计算机技术,那时候一个外设通常都只有几个寄存器,通过这几个寄存器就可以完成对外设的所有操作了。而现在的情况却不大一样。例如,在PC机上可以插上一块图像卡,带有2MB的存储器,甚至还可能带有一块ROM,里面装有可执行代码。所以要将外设卡上的存储器映射到内存空间,实际上是虚拟空间的手段。在Linux内核中,这样的映射是通过函数ioremap()来建立的。
对于内存页面的管理,通常我们都是先在虚拟空间分配一个虚拟空间,然后为此区间分配相应的物理内存页面并建立起映射。而且这样的映射也并不是一次就建立完毕,可以在访问这些虚拟页面引起页面异常时逐步地建立。
但是,ioremap()则不同,首先我们先有一个物理存储区间,其地址就是外设卡上的存储器出现在总线的地址(不是存储单元在外设卡上局部的物理地址)。在Linux系统中,CPU不能按物理地址来访问存储空间,而必须使用虚拟地址,所以必须”反向“地从物理地址出发找到一片虚拟空间并建立起映射。其次,这样的需求只发生于对外部设备的操作,而这是内核的事,所以相应的虚拟空间是在系统空间(3GB以上)。
参考:(干货!!)
Linux内存管理原理
Linux进程地址空间 && 进程内存布局
Linux内核情景分析.毛德操