spark on yarn
yarn client :适用于交互和调试
1.Driver在任务提交机器上执行
2.ApplicationMaster只负责向ResourceManager申请executor需要的资源
3.基于yarn时,spark-shell和pyspark必须要使用yarn-client模式
yarn cluster:适用于生产环境
spark核心
1.Spark基于弹性分布式数据集(RDD)模型,具有良好的通用性、容错性与并行处理数据的能力
2.RDD(ResilientDistributedDataset):弹性分布式数据集(相当于集合),它的本质是数据集的描述(只读的、可分区的分布式数据集),而不是数据集本身
3.RDD的关键特征:
- RDD使用户能够显式将计篇结果保存在内存中,控制数据的划分,并使用更丰富的操作集合来处理
- 使用更丰富的操作来处理,只读(由一个RDD变换得到另一个RDD,但是不能对本身的RDD修改)
- 记录数据的变换而不是数据本身保证容错(lineage)
- 通常在不同机器上备份数据或者记录数据更新的方式完成容错,但这种对任务密集型任务代价很高
- RDD采用数据应用变换(map.filter.join),若部分数据丟失,RDD拥有足够的信息得知这部分数据是如何计算得到的,可通过重新计算来得到丟失的数据
- 这种恢复数据方法很快,无需大量数据复制操作,可以认为Spark是基于RDD模型的系统
- 懒操作,延迟计算,action的时候才操作
- 瞬时性,用时才产生,用完就释放
官网文档练习
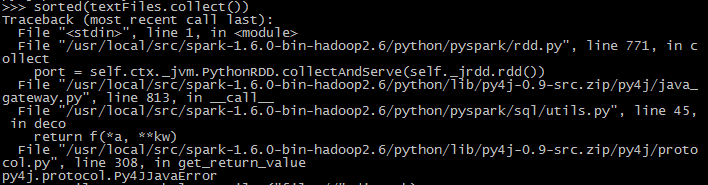
由于spark默认从hdfs读取文件,所以官方实例中会报错:
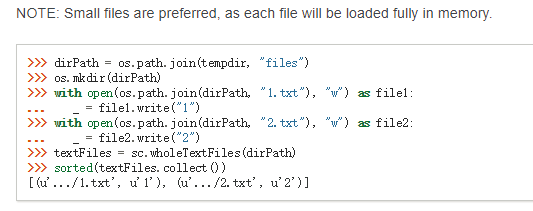
解决办法,在读取文件的时候指定从本地文件路径读取:

还有读取多文件的api是wholeTextFiles。
textFile与wholeTextFiles