# *-* coding:utf-8 *-* __author__ = 'YS' import urllib2 import urllib import re import json import os import time #抓取淘女郎的图片,淘女郎地址:https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.22495f9f1lYEAb class MMSpider: def __init__(self, timeout=3, albumLimit=200, picLimit=500, sleepPicCount=100, savePath='pythonspider/'): self.__headers = { 'User-Agent':'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36' } #抓取时间超时设置 self.timeout = timeout #抓取的相册个数限制 self.albumLimit = albumLimit #获取MM列表的地址 self.__mmListUrl = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8' #获取相册列表的地址 self.__albumListUrl = 'https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20=:userId&page=:page' #获取相册具体相片的地址 self.__albumDetailUrl = 'https://mm.taobao.com/album/json/get_album_photo_list.htm?user_id=:userId&album_id=:albumId&page=:page' #MM详情页面地址 self.__personUrl = 'https://mm.taobao.com/self/aiShow.htm?userId=:userId' #抓取的文件存放路径 self.savePath = savePath #每个MM的照片最多抓多少张 self.picLimit = picLimit #抓取多少张图片时休息1秒 self.sleepPicCount = sleepPicCount self.__mkdir(self.savePath) #获取页面内容,python中的异常继承关系: https://docs.python.org/3/library/exceptions.html#exception-hierarchy def __getContents(self, url, data=None, encoding=None, isjson=None): try: request = urllib2.Request(url, data, self.__headers) response = urllib2.urlopen(request, timeout=self.timeout) if encoding: contents = response.read().decode(encoding).encode('utf-8') else: contents = response.read() return json.loads(contents,encoding='utf-8') if isjson else contents except urllib2.URLError,e: print '出错了' + e.reason return None except BaseException,e: print '其他错误' print e.args return None #获取MM列表 def __getMMList(self, pageIndex): url = self.__mmListUrl data = urllib.urlencode({ 'currentPage':pageIndex, 'pageSize':50 }) list = self.__getContents(url, data, encoding='gbk', isjson=True) if list is None: return None elif list['status'] != 1: return None return list['data']['searchDOList'] #获取相册列表 def __getAlbumList(self, mm): albumList = [] baseUrl = self.__albumListUrl.replace(':userId',str(mm['userId'])) indexUrl = baseUrl.replace(':page','1') pageCount = int(self.__getAlbumListPage(indexUrl)) pageCount = pageCount if pageCount<=self.albumLimit else self.albumLimit for i in range(1, pageCount+1): listUrl = baseUrl.replace(':page', str(i)) contents = self.__getContents(listUrl) if (contents is None): continue pattern = re.compile('<h4><a href=".*?album_id=(.*?)&album_flag', re.S) items = re.findall(pattern, contents) for item in items: albumList.append(item) return albumList #获取单个相册的相片 def __getPicList(self, album, mm): lists = [] baseUrl = self.__albumDetailUrl.replace(':userId', str(mm['userId'])).replace(':albumId',str(album)) indexUrl = baseUrl.replace(':page','1') totalPage = self.__getPicPage(indexUrl) if totalPage is None: return None pages = range(1, int(totalPage)+1) for page in pages: url = baseUrl.replace(':page', '1') res = self.__getContents(url, isjson=True) if res is not None and res['isError']=='0': for pic in res['picList']: lists.append('http:'+pic['picUrl']) else: print "获取结果失败,地址:"+url return lists #获取单个相册照片列表的总页数 def __getPicPage(self, indexUrl): albuminfo = self.__getContents(indexUrl, encoding='gbk', isjson=True) if albuminfo is None: print '获取相册照片失败0,照片地址:'+indexUrl return None if albuminfo['isError'] != '0': print '获取相册照片失败1,照片地址:'+indexUrl return None totalPage = int(albuminfo['totalPage']) return totalPage #下载保存单个相册的照片,album表示相册id def __savePics(self, album, mm): print "正在保存"+mm['realName'].encode('utf-8')+'的相册,相册id为:'+album.encode('utf-8') pics = self.__getPicList(album, mm) if pics is None: return index = 1 for pic in pics: print "正在保存"+mm['realName'].encode('utf-8')+'的相册,相片地址为:'+pic.encode('utf-8') if index % self.sleepPicCount == 0: print "休息一秒" time.sleep(1) if index >= self.picLimit: print mm["realName"].encode('utf-8') + ":已经保存"+str(self.picLimit)+"张辣" return saveDir = self.savePath + mm['realName'].encode('utf-8') + '/img' self.__mkdir(saveDir) fileName = saveDir + '/'+str(index)+'.jpg' self.__saveImg(pic, fileName) index +=1 #获取相册的总页数 def __getAlbumListPage(self, url): contents = self.__getContents(url) if contents: pattern = re.compile('id="J_Totalpage" value="(.*?)"', re.S) return re.search(pattern, contents).group(1) else: return None #保存MM的基本信息至本地的text文件夹 def __saveMM(self, mm): print '正在保存'+mm['realName'].encode('utf-8')+'的信息' saveDir = self.savePath + mm['realName'] + '/text' self.__mkdir(saveDir) fileName = saveDir + '/info.txt' personUrl = self.__personUrl.replace(':userId', str(mm['userId'])) contents = "姓名:%s 城市:%s 体重:%s 身高:%s 喜欢:%s 个人主页:%s "%(mm['realName'].encode('utf-8'),mm['city'].encode('utf-8'),str(mm['weight']).encode('utf-8'),str(mm['height']).encode('utf-8'),str(mm['totalFavorNum']).encode('utf-8'),personUrl.encode('utf-8')) self.__saveTxtFile(contents, fileName) ##保存MM的头像到本地img文件夹 def __saveMMAvatar(self, mm): print '正在保存'+mm['realName'].encode('utf-8')+'的头像' saveDir = self.savePath + mm['realName'] + '/img' self.__mkdir(saveDir) fileName = saveDir + '/avatar.jpg' imgUrl = 'http:'+mm['avatarUrl']+'_240x240xz.jpg' #获取小图 self.__saveImg(imgUrl, fileName) #写入文本文件 def __saveTxtFile(self, contents, fileName): handler = open(fileName, 'w') handler.write(contents) handler.close() #写入图片 def __saveImg(self, imgUrl, fileName): contents = self.__getContents(imgUrl) if contents: handler = open(fileName, 'wb') handler.write(contents) handler.close() else: print '获取图片失败,图片地址:'+imgUrl.encode('utf-8') #创建存放图片或者文本文件的文件夹 def __mkdir(self, saveDir): if os.path.exists(saveDir): return False else: os.makedirs(saveDir) return True #主入口方法 def start(self, startPage, endPage): pages = range(startPage, endPage+1) for i in pages: mmlist = self.__getMMList(i) if not mmlist: print "第%s页无数据 "%(str(i)) break for mm in mmlist: self.__saveMM(mm) self.__saveMMAvatar(mm) albumList = self.__getAlbumList(mm) for album in albumList: self.__savePics(album, mm) if __name__ == '__main__': mmspider = MMSpider() mmspider.start(2, 3)
效果:
保存的图片:
保存的文本内容:
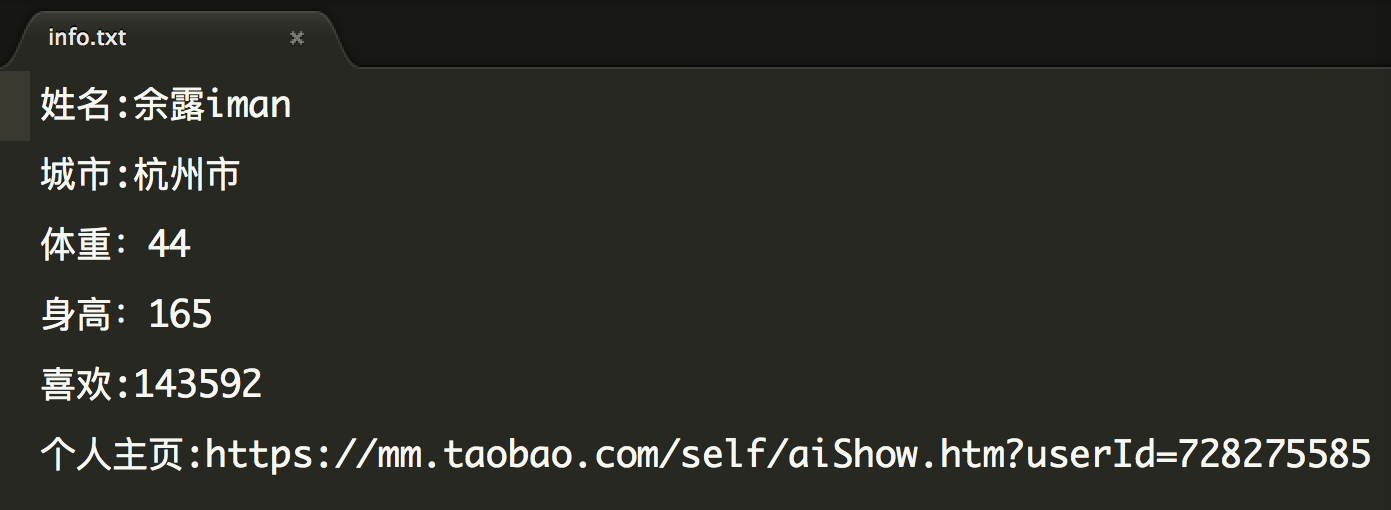
源码链接:https://github.com/yunshu2009/pythonspiders/blob/master/Taobaomm/Taobaomm.py