Abstract
惯例先说了一下原来的两种方法的优缺点
第一种
Gatys et al. recently introduced a neural algorithm that renders a content image in the style of another image, achieving so-called style transfer
Gatys等人最近带来了一种神经网络的算法,这个算法可以可以使一张图片用另一张图片的风格表达出来,即样式转换
优缺点:风格多样化程度自由,但训练过程比较漫长,原文里说:their frame-work requires a slow iterative optimization process
第二种
由于第一种的方法太慢了,提出了第二种前馈神经网络的的快速逼近方法(Fast approximations with feed-forward neural networks)用来加速风格转换的速度
优缺点:训练速度确实快了,但样式转换比较单一
接着引出自己的方法In this paper, we present a simple yet effective approach that for the first time enables arbitrary style transfer in real-time
在这篇文章中,我们提出了一种简单但是有效的方用来首次实现任意样式的实时风格转换
方法的核心是加入了一个adaptive instance normalization (AdaIN) layer,
这个层做的事情就是利用待转换风格图片的特征的均值和方差,用来改变原来图片的均值和方差
打个比方有x,y两张图片,想把y上的风格转移到x上去,首先吧x,y的encode后的特征提取出来求均值和方差,x做归一化,再用y的均值方差进行分布调整
然后就是我们的方法实在是太好了,又快又灵活,作者还用了fastest来修饰,可以说非常自信了
1. Introduction
还是在说前面abstract里的两种方法,只是比上面更清楚一点
第一种
从先前Gatys他们做的工作中可以发现神经网络不仅可以提取图片的内容信息,还可以提取样式信息,这也为保存内容的前提下改换样式提供了可能性
然后欲抑先扬:Gatys做的好啊,非常灵活,但是速度太慢了
第二种
因为前面速度比较慢,所以有些人尝试加速神经网络的训练速度,比如在24,31,51三篇里就提出了加速的方法,通过只执行一次的前项传播就可以实现样式的转换
但是问题就是只能局限于一个样式或者一组样式
好!重点来了 作者开始引出自己的方法,说自己解决了这种两难的困境(flexibility-speed dilemma)
作者说自己受到52,11两篇论文的启发,这两篇论文中的IN(instance normalization)的方法
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
大概说一下IN的方法:
IN也是提取出图片的特征均值和方差标准化公式为

x为输入的样本,减均值除标准差做标准化,然后通过gamma和beta来再调整x的分布,其中gamma和beta是需要训练的参数,叫仿射参数
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ok接着往下
作者结合了基于Gatys他们的框架所拥有的灵活性和上面所说的一次前项传播的速度
作者解释了一下为什么为什么IN能用
IN performs style normalization by normalizing feature statistics, which have been found to carry the style information of an image
因为feature statistics(后面翻译成特征统计量叭,也就是通道的均值和方差,毕竟笔者四级还没过找不到好翻译了)包含图片的样式信息,而IN是通过标准化特征统计量来使得样式标准化,
接着基于上面的这些讨论,作者提出了AdaIN这个方法,输入内容和样式,然后用内容的均值和方差去匹配样式的均值和方差
通过这个操作可以得到匹配后的编码,再把这个编码丢回训练好的decoder里生成图片
最后又说了一下这个方法比16里的快了三个数量级,并且非常灵活 (不忘初心了属于是)
2. Related Work
这段说了两个东西,sytle transfer和Deep generative image modeling已经做了哪些东西
style transfer
更加详细的介绍了原来的样式转换是怎么做到的,早期的一些方法无法捕获 semantic structures(个人理解是指图片除了色彩外的信息),例如采用linear filter responses and non-parametric sampling
在这之后Gatys引入的神经网络的概念到样式转换中,效果非常好,接着这几年又有一些改进:
Li和Wand等人在30里提出:在深层特征空间中引入一种基于马尔可夫随机场(MRF)的框架来增强局部模式
Gatys在16中也提出了一些可以控制色彩保留,空间位置和样式转移规模的方法
以上方法效果不错但是就是时间太慢了,所以不实用
接着有人提出用前馈神经网络去代替这个优化进程,加快了速度,但是不能适应训练期间未观察到的任意风格
Deep generative image modeling
这里说了一下目前生成图片的各种技术,variational auto-encoders,auto-regressive models,GAN,其中GAN是效果最好的,所以有了各种变种GAN(毕竟我也是看了nvidia的sytleGAN才来补课AdaIN的)
3. Background
3.1. Batch Normalization
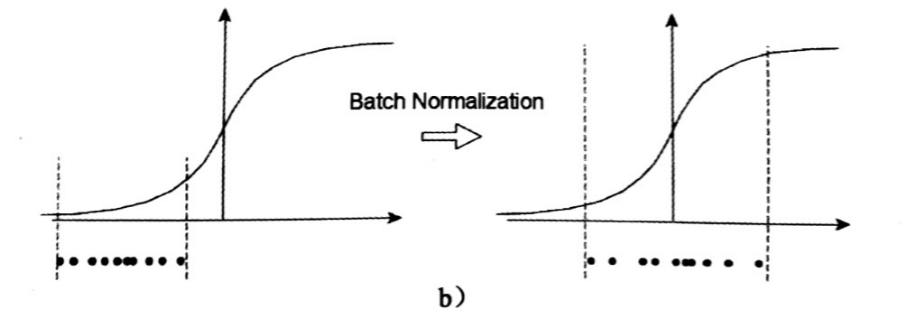
这段介绍了批标准化,其实批标准化我在前面的博客里写过,作用就是如果用sigmoid这样的激活函数,且样本点在没有尽量分布在0轴左右的话,就会导致整个训练过程非常缓慢,样本点越远离0轴,越缓慢,BN的操作使得每一层的输出都尽量较为分散的落在数轴0的两端,尽量使得数据处于梯度的敏感区域,加速梯度下降的过程,图如下
如果默认图像的格式为N*C*H*W(pytorch默认格式就是:批次大小*通道数(RGB)*高*宽),BN公式如下
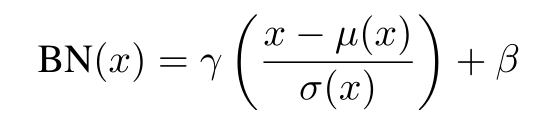
解释一下每个参数
gamma和beta:仿射参数,从输入的图片中训练获得(就是用这两个值调整标准化后的X)
mu(x):均值
sigma(x):标准差
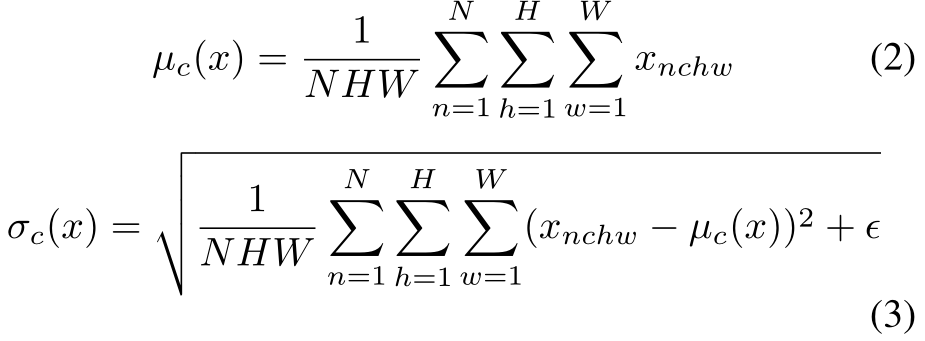
BN在训练的时候使用minibatch中数据,而在测试的时候使用总体的数据,这就导致在训练和测试的时候因为BN里取值不同,会导致有差异出现,所以后来提出了一种批重标准化,在训练的过程中逐渐加入全部的数据来解决这个问题
3.2. Instance Normalization
在卷积网络中,每次卷积后都会加一个BN层,但是在52中发现,如果吧BN换成IN(instance normalization)效果就会好很多,作者也说明了IN在他们的实验中确实效果不错
接着是IN的公式
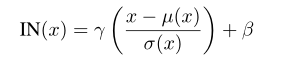
其中gamma,beta和上面的BN是一样的,但是在计算mu(x)和sigma(x)时和BN不同
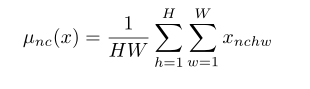

csdn里有一篇文章对这几种标准化画了直观的图有助于理解
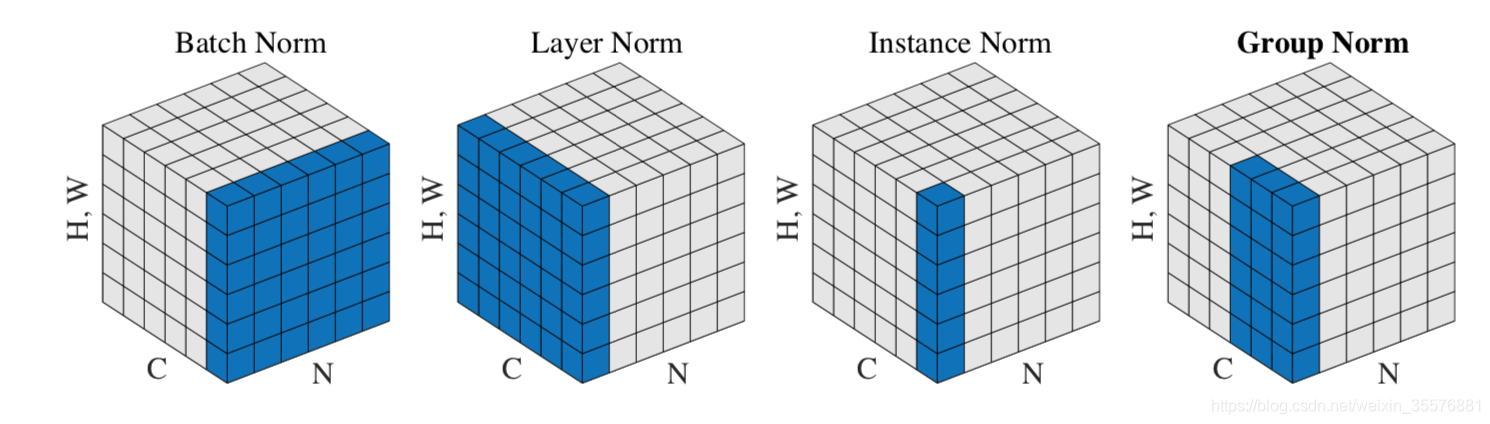
和BN层不一样,IN层即使是在测试时,也是使用minibatch的取值进行测试
3.3. Conditional Instance Normalization
Dumoulin在11里提出了修改gamma和beta而不是mu(x)和sigma(x)的方案(炼丹我疯狂的炼丹),在训练过程中,从一组固定的样式中随机选择样式图像及其索引s,s∈{1,2, ..., S}用来改变仿系数,
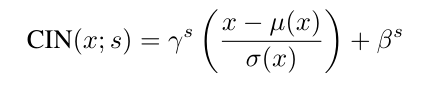
将内容图片输入到网络里,网络里有CIN层,利用选出来的样式得到gamma和beta两个参数控制CIN层
在这个网络中,使用相同的conv层参数,不同的仿射参数,可以获得完全不同的样式的图像
Dumoulin等人的方法迁移有限种的风格,想迁移新的的风格则需要训练新的模型。
4. Interpreting Instance Normalization
这里就开始更加详细的介绍为什么IN及其变种的操作在样式转移上能用,Ulyanov认为是因为IN对内容图像的对比对不变性(IN to its invariance to the contrast of the content image),但是,由于IN是在操作图片的feature space,所以应该比直接对像素里的对比度标准化有更加深远的影响,而且只需要改变仿射参数就可以使得完全改变输出图片的样式。
作者接着说了以前是怎么来得到并操作样式特征的
在16中Gatys用二阶统计量作为优化的手段
在33中Li发现其他的一些数据例如通道的均值和方差也对样式转换有影响
于是作者认为,IN通过标准化特征的统计量(例如均值和方差),来实现标准化样式。并且作者还相信除了DNN的结构,利用GAN中的Generator的特征统计量也可以控制图像生成
接着开始试验,他们跑了改善纹理的网络代码,增加了BN或者IN层,效果如下

作者这里做了三次试验
· 第一次是发现BN的效果确实不如IN
第二次是为了去证明Ulyanov在52里的猜想,利用了已经对比度标准化后的图跑,结果发现IN和BN依旧有效,证明在52中的猜想并不完全正确,且BN的损失收敛还是不如IN
第三次试验是用已经样式标准化后的图片来做,这次IN带来的改变更小,小到可以用样式规范化并不是完美的来解释(The remaining gap can be explained by the fact that the style normalization with [24] is not perfect.)
最后总结说在未处理(只样式标准化)的图像上使用IN和在已经处理过的图像上使用BN的收敛速度差不多快,以此证明IN确实是可以做到样式规范化
这段我没太读懂,希望以后能有更好的理解:接着说了一下BN这个操作,BN是标准化了一批样本的特征量信息,使得这批样本以某一个样式作为中心,但是毕竟每个样本的样式可能不同,这样标准化下去的样本和在中心的那个样本进行同样的样式转换时,会导致效果不好。虽然卷积层会尽量找补一些这种操作下产生的差异,但是还是比较困难的。回到IN,IN可以专注于处理样式特征,而其他网络可以专注与处理图片的内容特征,同时舍弃样式特征。同理CIN通过操作仿射参数来使得标准化后的特征统计量来改变成需要的特征,从而达成样式转换的目的。
5. Adaptive Instance Normalization
重点来了,作者在这部分提出了一个一个问题
If IN normalizes the input to a single style specified by the affine parameters, is it possible to adapt it to arbitrarily given styles by using adaptive affine transformations?
如果IN可以通过仿射参数来进行输入的标准化,那是否可以通过使用自适应的仿射参数来达到自适应任何一个给定的样式?
于是他们根据这个关于IN的讨论进行延展,提出了AdaIN
AdaIN是输入一个内容图片x,和一个风格图y,然后用x的通道的均值和方差去匹配y的均值和方差。和前面的BN,IN,CIN不同,这次的AdaIN里的仿射参数是不需要进行训练的,他会根据样式的输入自动设定仿射参数

从直觉上看来,单独考虑一个特征的通道,这个通道检查样式的brushstrokes特征。拥有这个stroke的样式图片将会对这种特征探测产生一个高平均激活度响应?(这句话不太读懂)
通过AdaIN生成的输出图片对于上述的特征将会有相同的高平均激活度(响应?),同时保留内容图片的空间结构。
通过decoder,可以将brushstrokes特征解码成一张图片。作者认为这种特征通道的方差可以更精细的encoder样式信息,也最终会影响到AdaIN的输出和最后的结果输出。
总的来说,AdaIN在特征空间中通过转换特征统计量(通道的均值和方差)来执行转换样式
接着继续说了一下自己和6的样式交换层(style swap layer)做的工作相同,但是AdaIN比他更快,且内存消耗更少,和IN相同,AdaIN基本不增加计算成本。
6. Experimental Setup
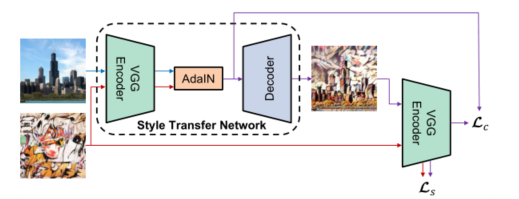
上图展示了作者他们自己写出的样式转换算法,使用固定下来的VGG-19的网络的前面几层去encoder内容和样式图片,接着使用AdaIN层在特征空间中进行样式转换。再利用decoder将AdaIN输出解码回图像。这里设计了两个loss,都是利用decoder输出出来的图片再用一个encoder编码回去
第一个Lc计算和AdaIN输出的loss,这一步用来训练decoder是否正确解码了AdaIN的输出
第二个Ls计算了原始图片的编码loss,这一步用来训练encoder是否可以正确编码信息
6.1 Architecture
作者的样式转换网络T输入两张图片,一张内容图片c,一张样式图片s,最后输出一张图片,这张输出的图片具有c的内容和s样式。在网络中还加入了一个简单的encoder-decoder结构,其中encoder是利用了预训练的VGG19的网络固定前几层得到的。将内容图片和样式图片输入到网络里后,encoder会将这两个图片在特征空间进行编码,再将这两个特征进行结合,输入到AdaIN层中,这层会将内容特征的均值、方差以及样式特征的均值、方差进行对齐,产生如下的目标映射:
t=AdaIN(f(c), f(s))
再将一个随机初始化的decoder g(generator)进行训练,这个g的作用就是为了将他特征编码再转换回图片
T(c, s) =g(t)
decoder尽可能的镜像encoder,通过nearest的插值方式做池化层上采样,减少棋盘效应
----------------------------------------------------------------------------------------------------------------------------------------------------------------
说一下棋盘效应,因为卷积核无法整除步长,就会导致在重复上采样绘图的部分不均匀
----------------------------------------------------------------------------------------------------------------------------------------------------------------
在f和g中使用反射填充(torch.nn.ReflectionPad2d)来避免边界伪影
作者接着讨论了他认为另外一个重要的问题,就是该不该在decoder里添加标准化比如是BN还是IN,或者不添加
接着引用了4里说的IN normalizes each sample to a single style while BN normalizes a batch of samples to be centered around a single style.
但是我们希望decoder可以生成各种图像,所以作者在decoder的选择是都不加,在7.1节会证明这个观点
6.2. Training
作者使用MS-COCO数据集做内容图片,风格图片是来自