1. 卷积后的图像的大小为 (w+2p-f)*3 / s W为图像的宽,p为padding的大小, f为卷积核大小, 3 为图像的通道数, s为步长
2. 卷积层和池化层的区别?
卷积层是窗口滑动卷积, 池化层是取最大值
3. sigmod 函数和 relu函数的区别 ??
sigmoid函数,
sigmoid函数在在两段接近饱和区是,变换的很缓慢,导数趋近于0,在反向传播时,容易出现梯度消失的现象,造成信息的丢失。同时因为sigmoid函数是指数运算,计算量较大,导致反向传播求误差梯度是,计算量相对于relu会大很多,而采用relu激活函数,计算量会小很多。同样还有一个好处,relu函数会使得一部分神经元的输出为0,这样会使网络稀疏,减少了参数的依赖关系,缓解了过拟合的发生。
4. 特征提取 尽量提取和需要识别的物体的相关的特征,不然容易过拟合
- sobel算子

5. 什么时候使用Relu函数,
每次迭代后都需要使用Relu函数;
6. 如果是10个 32*32*1 的特征图, 需要的参数为 10*5*5*3 + 10 = 760 个参数;
7. caffe 参数含义
epoch batch batch_size 含义
所以图片训练完叫一次epoch, 由于图片太多,无法将他们一次性训练完,所以要分很多个batch, 一个batch有batch_size张图片
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
inner_product_layer :全连接层

weight_filter 权值初始化方法 xavier 使用xavier方法初始化
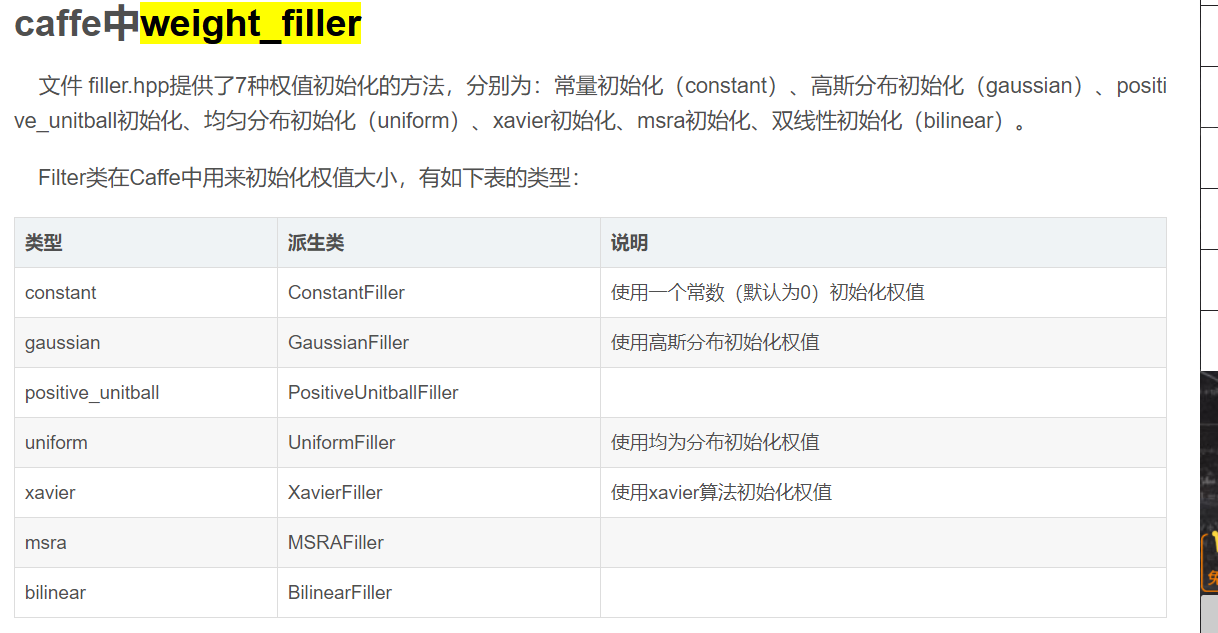
bias_filler 偏置项初始化
accuracy层:就是计算准确度的层
accuracy层是通过对比预测的结果与输入的label,通过统计预测正确的数量与总共要预测的数量的比值得到的。
accuracy层需要两个输入源,一个是经过网络预测的数值,另一个是最开始输入的label至,分别对应了bottom[0]和bottom[1].
SoftmaxWithLoss层 : 计算归一化概率和loss

8. 向量化
没有使用向量化的逻辑回归

使用了向量化的逻辑回归
9 梯度下降

10 逻辑回归中的代价函数

其中 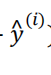 是未知的, y(i) 是已知的, 我们的目的就是求得
是未知的, y(i) 是已知的, 我们的目的就是求得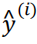 的表达式, 即求得wT 和b
的表达式, 即求得wT 和b