https://www.cnblogs.com/yiwangzhibujian/p/7053840.html
为什么说Redis是单线程的以及Redis为什么这么快!
参考文章:https://blog.csdn.net/xlgen157387/article/details/79470556
redis简介
Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库、缓存和消息中间件。
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
(1)多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
注意点
1、我们知道Redis是用”单线程-多路复用IO模型”来实现高性能的内存数据服务的,这种机制避免了使用锁,但是同时这种机制在进行sunion之类的比较耗时的命令时会使redis的并发下降。因为是单一线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致并发的下降,不只是读并发,写并发也会下降。而单一线程也只能用到一个CPU核心,所以可以在同一个多核的服务器中,可以启动多个实例,组成master-master或者master-slave的形式,耗时的读命令可以完全在slave进行。
需要改的redis.conf项:
1、pidfile /var/run/redis/redis_6377.pid #pidfile要加上端口号
2、port 6377 #这个是必须改的
3、logfile /var/log/redis/redis_6377.log #logfile的名称也加上端口号
4、dbfilename dump_6377.rdb #rdbfile也加上端口号
2、“我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以手动地为其分配CPU核,而不会过多地占用CPU,或是让我们关键进程和一堆别的进程挤在一起。”。
CPU 是一个重要的影响因素,由于是单线程模型,Redis 更喜欢大缓存快速 CPU, 而不是多核
在多核 CPU 服务器上面,Redis 的性能还依赖NUMA 配置和处理器绑定位置。最明显的影响是 redis-benchmark 会随机使用CPU内核。为了获得精准的结果,需要使用固定处理器工具(在 Linux 上可以使用 taskset)。最有效的办法是将客户端和服务端分离到两个不同的 CPU 来高校使用三级缓存。
Redis 基础:
数据类型
| 数据类型 | 可以存储的值 | 操作 | 用法 |
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
可以对 String 进行自增自减运算,从而实现计数器功能。 Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息 不过最好使用 Kafka、RabbitMQ 等消息中间件。 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
Set 可以实现交集、并集等操作,从而实现共同好友等功能。 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
|
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
ZSet 可以实现有序性操作,从而实现排行榜等功能。 |
持久化:
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其它服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量很大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(Append Only File)的末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:
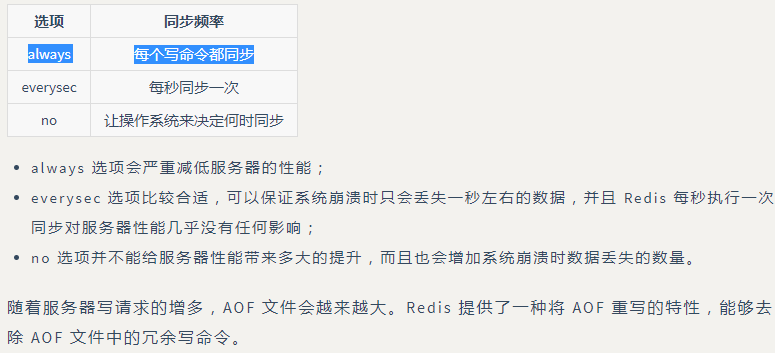
复制:
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
连接过程
主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
主服务器每执行一次写命令,就向从服务器发送相同的写命令。
哨兵模式:
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
分片:
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,... ,有不同的方式来选择一个指定的键存储在哪个实例中。
最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从 1001~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式:
客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
服务器分片:Redis Cluster。
Redis 和 Memcached 的差异:
https://www.cnblogs.com/loveincode/p/7411911.html
1、Redis 支持服务器端的数据操作:Redis 相比 Memcached 来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在 Memcached 里,你需要将数据拿到客户端来进行类似的修改再 set 回去。这大大增加了网络 IO 的次数和数据体积。在 Redis 中,这些复杂的操作通常和一般的 GET/SET 一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么 Redis 会是不错的选择。
2、内存使用效率对比:使用简单的 key-value 存储的话,Memcached 的内存利用率更高,而如果 Redis 采用 hash 结构来做 key-value 存储,由于其组合式的压缩,其内存利用率会高于 Memcached。
3、性能对比:由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。
4、Redis支持持久性