目录
为什么会有map
array和slice优点
- 可以存储相同类型的的数据比如: s1 := []int{1,1,1,1,1,1}
- 在知道下标的情况下访问数据速度贼快: s2 := []string{"v0", "v1", "v2"} 访问: s2[1]
缺点
- 如果想判断某个值是否存在或者不知道数据的下标怎么办?一个一个找效率就不高了
map
它是一个: key: value的集合例如: map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
他可以通过key去直接访问某个值,效率也很高,也可以通过key判断是否存不像array或者slice下标没啥特殊意义
map定义
标准定义声明
func main() {
// map[KeyType]ValueType
// KeyType:表示键的类型
// ValueType:表示键对应的值的类型
// map是引用类型需要使用make初始化: make(map[KeyType]ValueType, cap)
// 其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量
m1 := make(map[int]int, 10)
}
注意事项
- key不能重复
- 无序的(值不变但是,不像array和slice的顺序不变永远下标都是顺序的,每次输出值得顺序可能是不相同的)
map增加元素
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
m1["意大利"] = "Italy"
fmt.Printf("%v", m1)
}
map判断元素是否存在
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
// 直接取值会返回两个值
// 第一个值是: key的value, 第二个值: 如果key存在返回true否则返回false
value, isTrue := m1["意大利"]
fmt.Printf("%v,%v,
", value, isTrue)
map删除元素通过delete
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
// delete(map, key)
delete(m1, "美国")
// 如果要删除的key不存在什么都不做
fmt.Printf("%v
", m1)
map修改元素
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
m1["美国"] = "USA"
fmt.Printf("%v
", m1)
}
map查询元素
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
// 直接取值会返回两个值
// 第一个值是: key的value, 第二个值: 如果key存在返回true否则返回false
value, isTrue := m1["意大利"]
fmt.Printf("%v,%v,
", value, isTrue)
if isTrue {
fmt.Printf("意大利已经存在了")
} else {
m1["意大利"] = "Italy"
}
}
map元素的循环
func main() {
m1 := map[string]string{"中国": "China", "英国": "Britain", "美国": "America"}
// for range
for key, value := range m1 {
fmt.Printf("key: %v, value: %v
", key, value)
}
}
map元素的嵌套
func main() {
// 列表包含map
smap1 := []map[string]string{{"name": "eson", "addr": "hebei"}, {"name": "eric", "addr": "xian"}}
smap1 = append(smap1, map[string]string{"name": "doudou", "addr": "beijing"})
fmt.Printf("%v
", smap1)
// map包含列表
maps1 := map[string][]string{"hebei": {"邯郸市", "保定市"}, "henan": {"新郑市", "林州市"}}
maps1["shanxi"] = []string{"太原市", "长治市"}
fmt.Printf("%v
", maps1)
// map包含map
mapm1 := map[string]map[string]string{"eson": {"age": "18", "home": "hebei"}}
mapm1["erice"] = map[string]string{"age": "20", "home": "beijing"}
fmt.Printf("%v
", mapm1)
}
map扩容策略
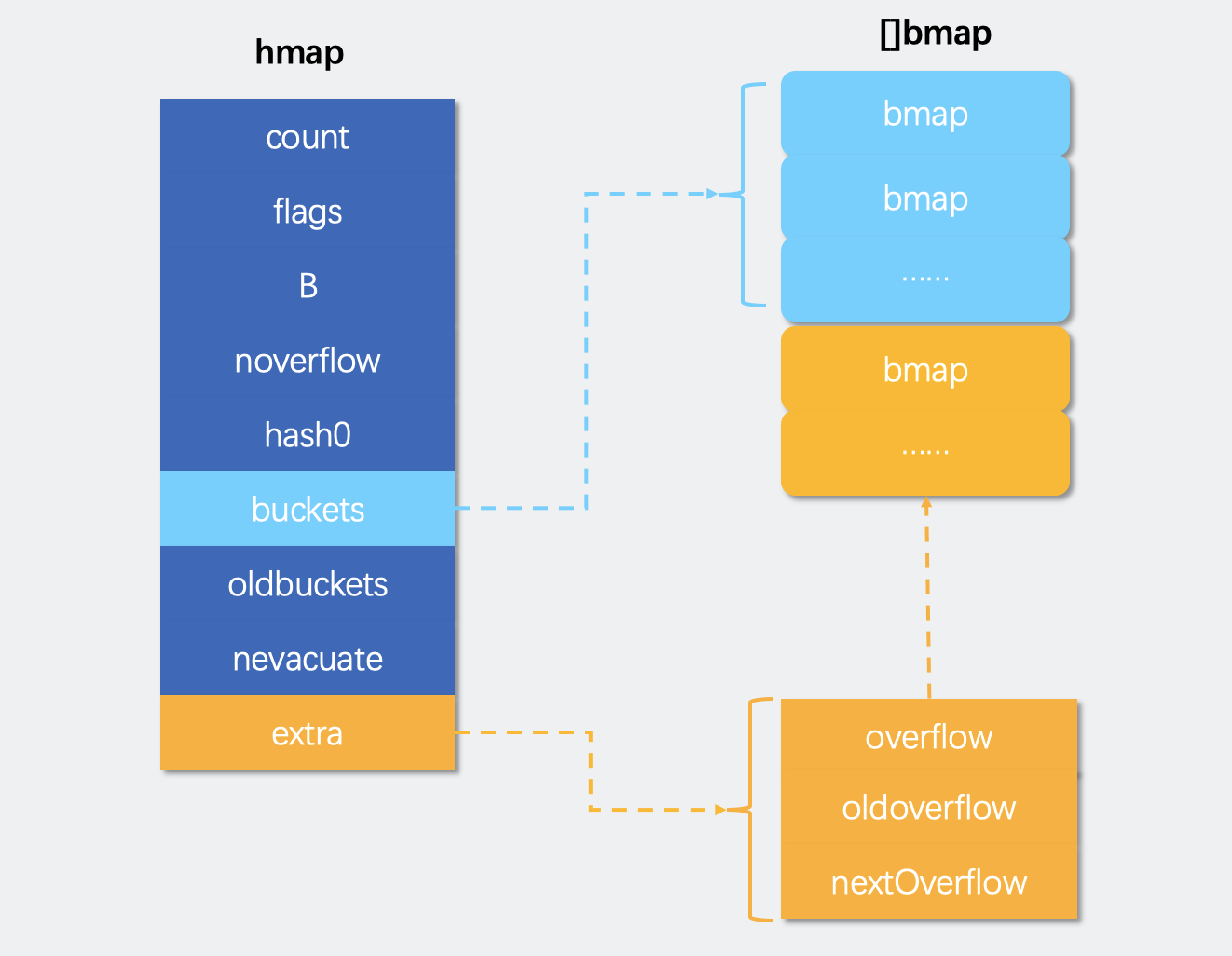
- count 表示当前哈希表中的元素数量;
- B 表示当前哈希表持有的 buckets 数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是 len(buckets) == 2^B;
- hash0 是哈希的因子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;
- oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
它的扩容触发条件:
- 数据个数/桶的个数 > 6.5 触发翻倍扩容
- 哈希使用了太多溢出桶,触发等量扩容,触发条件
- 桶的数量 <=15,溢出桶>=2B
- 桶的数量>=15,溢出桶>=215