问题描述,对于很多的新手rails lover来说,搞定db是件头疼的事情,当建立了一个model,测试了半天发现我草列名写错了,再过一会儿发现association里面竟然没有xxx_id,这下子shit啦,头脑一片混乱,okay,删了从来吧,这种方法其实是最好的,因为你又可以复习一边啦!哈哈哈,不过正常人应该不太喜欢这种方式,比如说我,我不喜欢复习,所以,here comes the 解决办法,其实不是解决办法了,而是我们来学习一下rake 的db操作吧!让我们从头来叙述一边,这样新手估计更会弄明白这之间到底发生了什么,少说屁话了,开工,新建一个rails应用,第一步,建立一个model吧!
 新建一个模型呢,通常会得到如图所示的几个文件,那么点开来看了,发现跟我们关心的数据库有关的东东都在xxxxxx_create_users.rb里面,
新建一个模型呢,通常会得到如图所示的几个文件,那么点开来看了,发现跟我们关心的数据库有关的东东都在xxxxxx_create_users.rb里面,
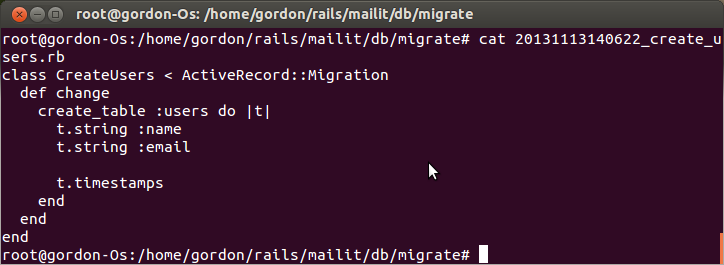
OKay, 看上去还不错,一切都正常,哦,shit,竟然忘记了加部门id,这可怎么办,删掉model 吗?这是一种方法,在没有rake db:migrate操作执行之前,一切还很来得及,

可以看出,这个操作只是把之前generate的操作生成的文件全部都去掉,所有我们需要做的只是再来一次,okay,如果你喜欢dos窗口的,可以这么做,但是,另一种方法可能会更好一些吧,现在让我们来解释一下这个rails g model User name email, 这会生成一个模型,包含string类型的name 和email, 请记住,这部是cache,生成的只是文件,既然是文件,那么必然可以改咯,但是到哪里改呢? 还好只有四个文件,逐一打开发现只有两个文件当中涉及到了字段,一个是刚才我们打开的xxxxxxxxx_create_users.rb,另一个是users.yml,实施上,test_unit用的很少,你可以忽略,但是,作为一个追求完美主义的程序员来说,不要为后面的开发留下任何bug,既然知道了那就加呗,


搞定,现在就像跟使用rails g model User name email department_id:integer一模一样啦!结束手工!啊,不对,另外一个问题来了,rake db:migrate以后想改怎么办?如果在这个时候,已经在数据库里面有一个表了,如果更改了,如果你更改了字段再来rake db:migrate的话,会出现:

既然有表了,那就删除呗,holy crap,我google了半天就是没有找到rake db:drop table users这样子的指令,只有rake db:drop,这会把其他的表也都给删了,那么,当然里面的数据也全都没了,这肯定是大家不想看到的,为了一张表删了其他所有的表,当然,这些表的结构不用重建,rake以后都会有,开发开始阶段可以,但是后面有了很多测试数据就不推荐了,相关的命令一大堆,言归正转,那么怎么办呢,可以生成一个新的migration, 使用rails g migration xxx,


在change里面可以加drop_table :users,但是,rake db:migrate在执行的时候是有时间先后顺序,那怎么将这个提前呢,只有一个很扯淡的方法,那就是将前面的timestamp提前,这时候执行rake db:migrate就okay了,那有没有更好的办法呢,当然有,在之前加drop_table :users不就好了吗?looks like this:

这样一来,命令可以执行了,而且,注意了哦,其他的表由于没有改变,是不会发生变化的!nice,这就是我觉得最好的方法了!这只是举例了最简单的,还有好多的操作,上个link吧:http://guides.rubyonrails.org/migrations.html,仔细琢磨吧!
在最后,总结一下rails在执行rake db系列操作的时候的顺序与规则,每次执行,都会将上次操作的记录存放到.schema的一个文件中去,在.schema文件中,有一个数字,它其实代表时间,每次执行都只会执行db/migration/ 文件夹下面的时间戳比这个时间延后的文件,也就是说,每执行一次一个rake db:migration后,都有一个或多个文件的时间戳被写入到.schema中,那么下次再次执行rake db:migration时,只有数字比这个大的时间戳会被执行,其他的全部都会跳过。把握住了这一点,基本上你就知道怎么去处理了!