前言:
两天不写就感觉生疏了,写写接口自动化的一些基础知识汇总。前提:对抓包工具fiddler有基础的了解
1.发送get请求
用禅道登录页面为例(刷新即可)
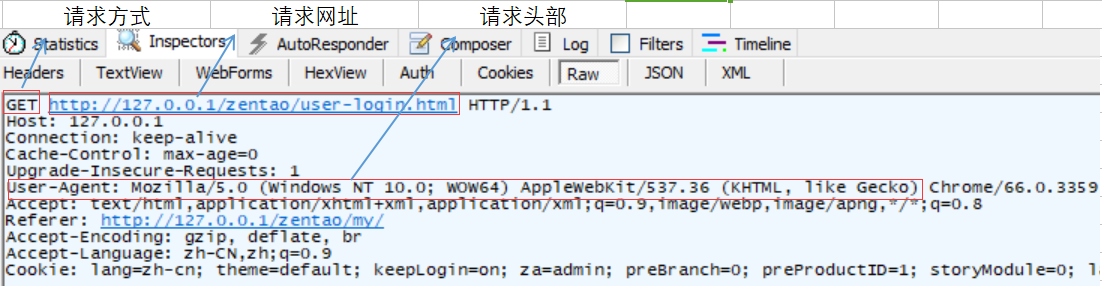
具体代码:
#coding:utf-8 import requests url='http://127.0.0.1/zentao/user-login.html' head={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36' } s=requests.session() r=s.get(url,headers=head,verify=False) r.encoding='utf-8' print(r.status_code) print(r.encoding) print(r.text)
返回内容:

访问是否成功:看返回文本的title
这里是需要转下码(r.encoding='utf-8'),转成UTF-8,不然会出现下面这样情况,不够直观
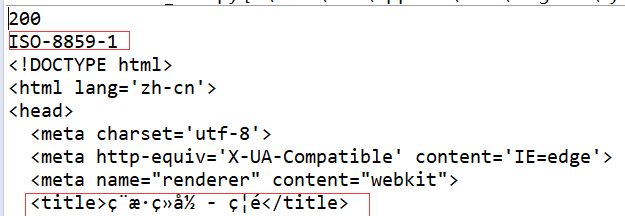
2.发送post请求
还是以禅道输入账号密码登录为例
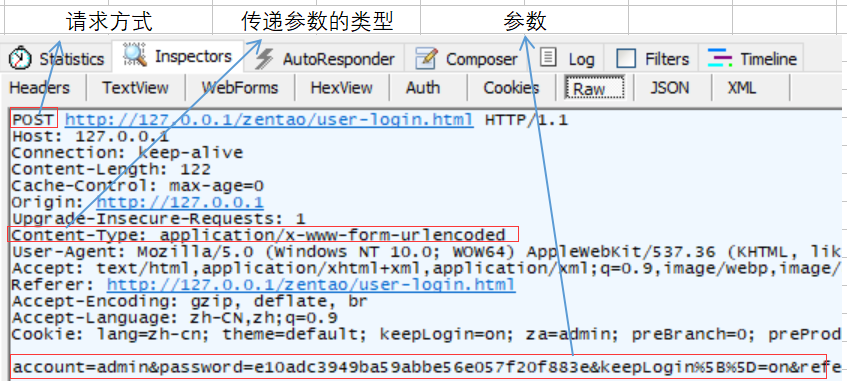
这里在raw里面先关注三个点,一个是请求方式,二是传递参数类型,三是参数
参数这点也可以去webForms里查看

具体代码:
url2='http://127.0.0.1/zentao/user-login.html' head={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36' } s=requests.session() body={ 'account' : 'admin', 'password' : 'e10adc3949ba59abbe56e057f20f883e', 'keepLogin[]' : 'on', 'referer' : 'http://127.0.0.1/zentao/my/' } r=s.post(url2, data=body,headers=head) print(r.status_code) print(r.text)
返回内容:

判断是否登录成功:查看返回内容,这里是已经给你返回了另外一个地址了。
更直接一点的是方法:将参数错误输入,对比正确参数的返回结果(比如admin改为admin1)。错误参数返回如下内容,结果一目了然

接下来发个格式为json的post请求,需要多做的是导入json模块,然后将传递的参数用dumps方法转成json,最后在请求的时候就用 json=xx 去请求
import json import requests s=requests.session() url3='http://httpbin.org/post' testdata={'a':'1', 'b':'2' } data=json.dumps(testdata) r=s.post(url3, json=data) print(r.status_code) print(r.text)
还是详细看下抓包的内容吧
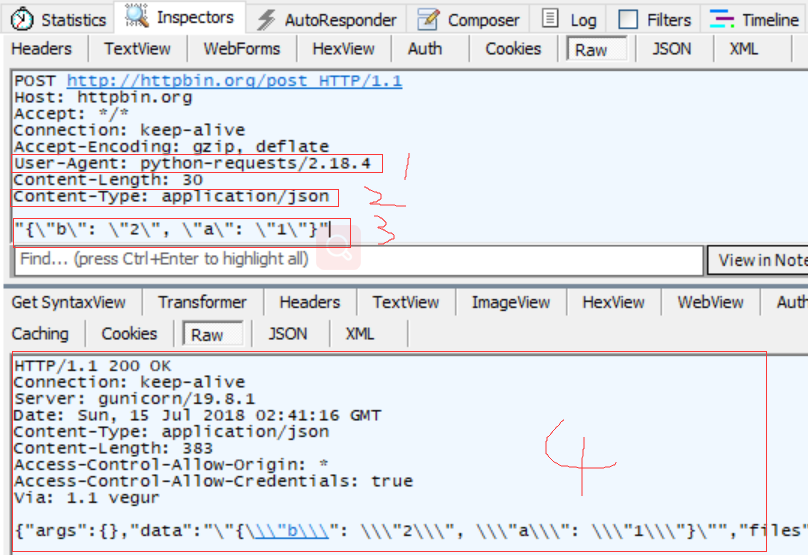
1.这个是我没有加头部,他显示的信息是python-requests,人家一看就是python访问的,就拒绝你了,这也说明了一般需要加头部
2.content-Type=json ; 说明是json的了
3.参数,json参数在wenForms里看不到的。

4.返回内容
3.传图片/附件请求
还是已禅道为例,先来手动抓包看看
步骤:登录→提bug→在复现步骤里添加图片(这里暂时不提交,目的只是先添加成功)
先贴流水账代码
1 #coding:utf-8 2 import requests 3 jpgname='test_road.jpg' 4 jpgpath=r'D: upian oad.jpg' 5 host='http://127.0.0.1:80' 6 s=requests.session() 7 url1='http://127.0.0.1/zentao/user-login.html' 8 head={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36' 9 } 10 11 body={ 12 'account' : 'admin', 13 'password' : 'e10adc3949ba59abbe56e057f20f883e', 14 'keepLogin[]' : 'on', 15 'referer' : 'http://127.0.0.1/zentao/my/' 16 } 17 r=s.post(url1, data=body,headers=head) 18 print(r.status_code) 19 r.encoding='utf-8' 20 print(r.text) 21 22 url=host+'/zentao/file-ajaxUpload-5b32f466b8804.html?dir=image' 23 file={"localUrl":(None,jpgname), 24 "imgFile":('1.jpg',open(jpgpath,'rb'),'image/jpeg') 25 } 26 27 r=s.post(url, files=file) 28 print(r.text) 29 jpg_url=r.json()['url'] 30 print(jpg_url)
返回内容:

在看抓包信息:
这里有两个,一个是登录的(不贴了,越过了),一个是传图片的,主要看下他的

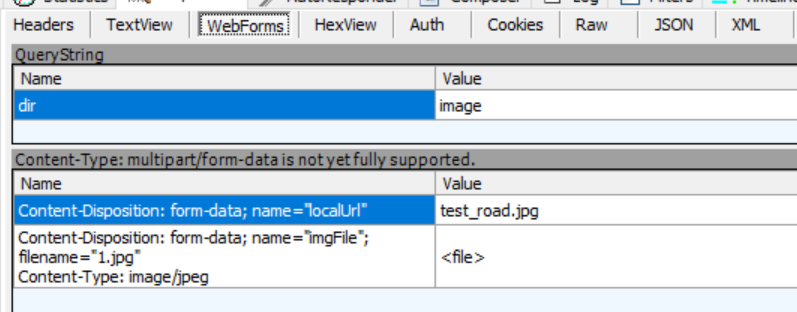
这里的content-Type和WebForms里的参数都有点不一样了,这种表单传参就如上面23行代码开始,传元祖形式。
因为Content-Disposition: form-data;这两项参数是一样的,可以不用管,只需要管name参数即可,因为上面也是标注Name
说下
file={"localUrl":(None,jpgname), #None参数,可有可无。jpgname是对你传的照片命名
"imgFile":('1.jpg',open(jpgpath,'rb'),'image/jpeg') #1.jpg是你照片的名字, open(jpgpath,'rb')是打开你那张照片,'image/jpeg'是格式,抓包也能看见
}
note:
1.这里用files=xxxx,不用json和data
2.检查是否传成功:输入host+后面打印出来的地址,能显示出来你传的那张照片就成功了
3.传附件和传图片一样,将files=xxxx单独拎出来

完整bug代码提交(图片+附件):
#coding:utf-8 import requests import time jpgname='test_road.jpg' jpgpath=r'D: upian oad.jpg' host='http://127.0.0.1:80' s=requests.session() url1='http://127.0.0.1/zentao/user-login.html' head={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36' } body={ 'account' : 'admin', 'password' : 'e10adc3949ba59abbe56e057f20f883e', 'keepLogin[]' : 'on', 'referer' : 'http://127.0.0.1/zentao/my/' } r=s.post(url1, data=body,headers=head) print(r.status_code) r.encoding='utf-8' print(r.text) url2=host+'/zentao/file-ajaxUpload-5b32f466b8804.html?dir=image' file={"localUrl":(None,jpgname), "imgFile":('1.jpg',open(jpgpath,'rb'),'image/jpeg') } r=s.post(url2, files=file) print(r.text) jpg_url=r.json()['url'] print(jpg_url) url3='http://127.0.0.1/zentao/bug-create-1-0-moduleID=0.html' title=time.strftime('%Y_%m_%d_%H_%M_%S') body= { "product": "1", "module": "0", "project": "", "openedBuild[]": "trunk", "assignedTo": "admin", "type": "codeerror", "os": "all", "browser": "all", "color": "", "title": title, "severity": "3", "pri": "0", "steps": '<p>[步骤]</p> <p>1、第一步点</p> <p>2、第二步点</p> <p>3、点三步点</p> <p>[期望]222<img src="%s" alt="" /></p> <p>[结果]</p> <p>[期望]</p>' % jpg_url, "story": "0", "task": "0", "mailto[]": "", "keywords": "", "uid": "5a2955c884f98", "case": "0", "caseVersion": "0", "result": "0", "testtask": "0" }
file=[
('files[]',('2.jpg',open(r'D: upian1.jpg','rb'),'image/png')),
('files[]',('x.jpg',open(r'D: upian
oad.jpg','rb'),'image/png'))
] #传多个用list类型
r=s.post(url3, data=body,files=file) print(r.text)
自行封装成类吧
4.session
百度一大堆具体用法
s=requests.session()
老师说理解为代码里的浏览器,写代码时就和webdriver一样,做个全局变量
后面再用 s 去发送get/post请求
5.dict ⇔ json
import json
d1={'a':'1',
'b':'2'
}
print(type(d1))
j=json.dumps(d1) #dict转json
print(type(j)) #json属于特殊的str类型
print(j)
d2=json.loads(j) #json转dict
print(type(d2))
print(d2)
打印结果

6.添加cookies,绕过验证码登录
用自己公司的网站为例
步骤:打开fiddler→手动登录→在fiddler里获得cookie→添加到代码
具体操作;
验证码页面

登陆后获得的cookie

代码:
#coding:utf-8 import requests url='http:xxxxxxxxxxxxxx' s=requests.session() c=requests.cookies.RequestsCookieJar() c.set('STYLE','xxxxxxxxxxx') c.set('JSESSIONID', 'xxxxxxxxxx') c.set('pgv_pvi', 'xxxxxxxxxxxxx') c.set('loginUserName', 'xxxxxxxx') s.cookies.update(c) #更新cookies r=s.get(url) print(r.text)
检查是否登录成功:
查看返回的内容里面是否有你的登录过后的元素
这是打印出结果

这是手动登录能看见的