阅读目录
- 一 为何要学习HTTP协议
- 二 用户上网过程
- 三 HTTP协议
- part1 http协议概述
- part2 请求协议
- part3 响应协议
- 四 抓包分析HTTP协议
一 为何要学习HTTP协议
http协议就是通信的双方共同遵守的标准,就好比要合伙办事的两家公司签署的合同。
openstack中各组件是基于restful api通信的,restful api可以单纯的理解为一个url地址:http://www.egon.com/index.html
因而不管研究openstack内的任何组件,都离不开http协议,要想成为一名合格的架构师,这些必须搞明白
二 用户上网过程
用户从打开浏览器输入网址到看到页面经历了什么?
1.首先必须web服务器运行
2.客户端运行浏览器软件
3.用户输入http://www.sina.com.cn/
4.客户端浏览器处理http://www.sina.com.cn/,发起查询本地DNS操作,将www.sina.com.cn->202.103.0.33
5.客户端浏览器发送http请求http://202.103.0.33:80/index.html (注意:80是web服务器的默认端口,index.html是默认的请求的资源)
6.服务端web服务收到该http的request请求头,从请求头中获取客户端的方法GET/POST.../index.html这个路径,及客户端请求的其他相关信息
7.服务端web服务根据取得的信息,回复respone响应头
响应头中包含:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中,压缩后返回给客户端。
8.客户端浏览器收到服务端发来的数据,解压后解析html内容,用户就看到网页内容了
9.html内可能嵌套其他的链接,比方说图片、视频、javascript脚本,flash等,客户端浏览器会继续发起http请求来获取它们。这样来自图片和视频的压力就被分散到各个服务器,一个站点由无数个站点相互连接起来,就形成了World Wide Web,简称WWW。
综上,其实就是一次http请求-响应的流程
三 HTTP协议
web服务器即socket服务端,浏览器即socket客户端,这叫B/S架构,B与S之间通信的标准是HTTP协议(目前版本1.1,比1.0好在可以允许多个http请求复用一个TCP连接)
part1 http协议概述
HTTP(hypertext transport protocol),即超文本传输协议。这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。其实我们要学习的就是这个两个格式!客户端发送给服务器的格式叫“请求协议”;服务器发送给客户端的格式叫“响应协议”。
特点:
- HTTP叫超文本传输协议,基于请求/响应模式的!
- HTTP是无状态协议,FTP是有状态。
URL:统一资源定位符,就是一个网址:协议名://域名:端口/路径,例如:http://www.oldboy.cn:80/index.html
part2 请求协议
请求协议的格式如下:
请求首行; // 请求方式 请求路径 协议和版本,例如:GET /index.html HTTP/1.1 请求头信息;// 请求头名称:请求头内容,即为key:value格式,例如:Host:localhost 空行; // 用来与请求体分隔开 请求体。 // GET没有请求体,只有POST有请求体。
浏览器发送给服务器的内容就这个格式的,如果不是这个格式服务器将无法解读!在HTTP协议中,请求有很多请求方法,其中最为常用的就是GET和POST。不同的请求方法之间的区别,后面会一点一点的介绍。
GET请求
HTTP默认的请求方法就是GET
* 没有请求体
* 数据必须在1K之内!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
GET / HTTP/1.1 Host: www.sina.com.cn Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Encoding: gzip, deflate, sdch Accept-Language: zh-CN,zh;q=0.8 Cookie: SINAGLOBAL=223.71.229.3_1484011627.259786; Apache=223.71.229.3_1484011627.25978
- GET / HTTP/1.1:GET请求,请求服务器路径为 http://www.sina.com.cn/ ,协议为1.1;
- Host:www.sina.com.cn 请求的主机名为www.sina.com.cn;
- Connection: keep-alive:客户端支持的链接方式,保持一段时间链接,默认为3000ms;
- User-Agent:.......:与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这都是通过获取User-Agent头信息而来的;
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8:告诉服务器,当前客户端可以接收的文档类型,其实这里包含了*/*,就表示什么都可以接收;
- Accept-Encoding: gzip, deflate,sdch:支持的压缩格式。数据在网络上传递时,可能服务器会把数据压缩后再发送;
- Accept-Language: zh-cn,zh;q=0.5:当前客户端支持的语言,可以在浏览器的工具选项中找到语言相关信息;
-
Cookie:SINAGLOBAL=223.71.229.3_1484011627.259786; Apache=223.71.229.3_1484011627.259788
因为不是第一次访问这个地址,所以会在请求中把上一次服务器响应中发送过来的Cookie在请求中一并发送去过;这个Cookie的名字为SINAGLOBAL
POST请求
(1). 数据不会出现在地址栏中
(2). 数据的大小没有上限
(3). 有请求体
(4). 请求体中如果存在中文,会使用URL编码!
表单测试
<!DOCTYPE html> <html> <body> <form method="post"> 用户名:<br> <input type="text" name="username"> <br> 密码:<br> <input type="text" name="password"> <input type="submit" value="登录"> </form> </body> </html>
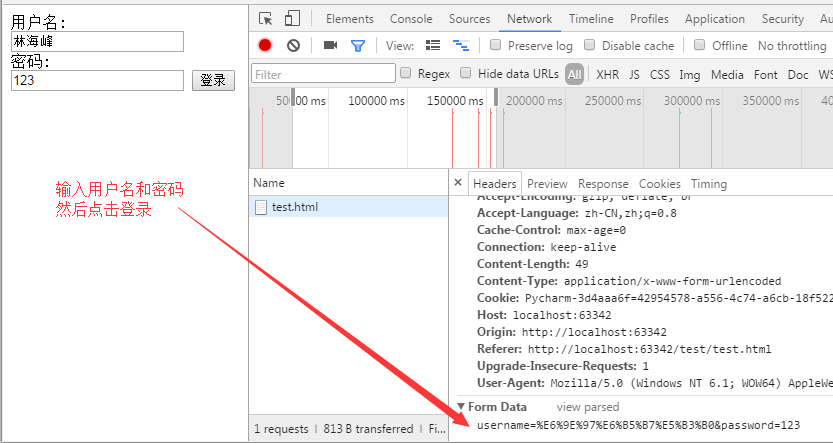
为什么要进行URL编码
我们都知道Http协议中参数的传输是"key=value"这种简直对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?name1=value1&name2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出参数值。 针对“name1=value1&name2=value2”我们来说一下客户端到服务端的概念上解析过程: 上述字符串在计算机中用ASCII吗表示为: 6E616D6531 3D 76616C756531 26 6E616D6532 3D 76616C756532。 6E616D6531:name1 3D:= 76616C756531:value1 26:& 6E616D6532:name2 3D:= 76616C756532:value2 服务端在接收到该数据后就可以遍历该字节流,首先一个字节一个字节的吃,当吃到3D这字节后,服务端就知道前面吃得字节表示一个key,再想后吃,如果遇到26,说明从刚才吃的3D到26子节之间的是上一个key的value,以此类推就可以解析出客户端传过来的参数。 现在有这样一个问题,如果我的参数值中就包含=或&这种特殊字符的时候该怎么办。 比如说“name1=value1”,其中value1的值是“va&lu=e1”字符串,那么实际在传输过程中就会变成这样“name1=va&lu=e1”。我们的本意是就只有一个键值对,但是服务端会解析成两个键值对,这样就产生了奇异。 如何解决上述问题带来的歧义呢?解决的办法就是对参数进行URL编码 URL编码只是简单的在特殊字符的各个字节前加上%,例如,我们对上述会产生奇异的字符进行URL编码后结果:“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。 为什么要进行URL编码
POST请求是可以有体的,而GET请求不能有请求体。
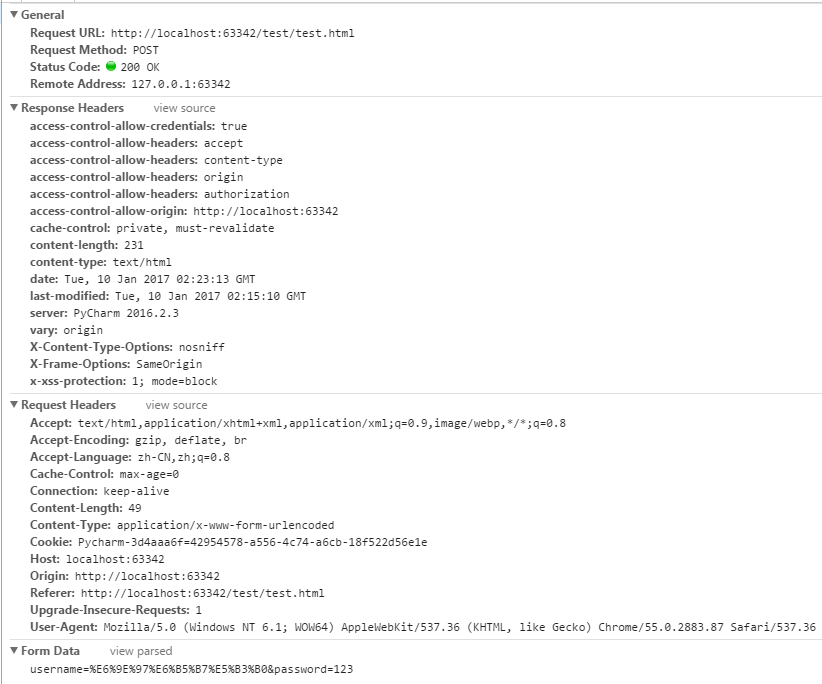
- Referer: http://localhost:63342/test/test.html:请求来自哪个页面,例如你在百度上点击链接到了这里,那么Referer:http://www.baidu.com;如果你是在浏览器的地址栏中直接输入的地址,那么就没有Referer这个请求头了;
- Content-Type: application/x-www-form-urlencoded:表单的数据类型,说明会使用url格式编码数据;url编码的数据都是以“%”为前缀,后面跟随两位的16进制。
- Content-Length:49:请求体的长度,这里表示13个字节。
- username=‘林海峰’:请求体内容!hello是在表单中输入的数据,keyword是表单字段的名字
Referer的应用
Referer请求头是比较有用的一个请求头,它可以用来做统计工作,也可以用来做防盗链。 统计工作:我公司网站在百度上做了广告,但不知道在百度上做广告对我们网站的访问量是否有影响,那么可以对每个请求中的Referer进行分析,如果Referer为百度的很多,那么说明用户都是通过百度找到我们公司网站的。 防盗链:我公司网站上有一个下载链接,而其他网站盗链了这个地址,例如在我网站上的index.html页面中有一个链接,点击即可下载JDK7.0,但有某个人的微博中盗链了这个资源,它也有一个链接指向我们网站的JDK7.0,也就是说登录它的微博,点击链接就可以从我网站上下载JDK7.0,这导致我们网站的广告没有看,但下载的却是我网站的资源。这时可以使用Referer进行防盗链,在资源被下载之前,我们对Referer进行判断,如果请求来自本网站,那么允许下载,如果非本网站,先跳转到本网站看广告,然后再允许下载。
part3 响应协议
3.1 响应内容
响应协议的格式如下:
响应首行; 响应头信息; 空行; 响应体。
响应内容是由服务器发送给浏览器的内容,浏览器会根据响应内容来显示。遇到<img src=''>会开一个新的线程加载,所以有时图片多的话,内容会先显示出来,然后图片才一张张加载出来。
wsgi server
#_*_coding:utf-8_*_
#!/usr/bin/env python
from wsgiref.simple_server import make_server
# 定义application函数:
def application(environ, start_response):
print(environ)
start_response('200 OK', [('Content-Type', 'text/html')])
f=open('test.html','rb')
return [f.read()]
# 创建一个服务器,IP地址为空,端口是8000,处理函数是application:
httpd = make_server('', 8000, application)
print('Serving HTTP on port 8000...')
# 开始监听HTTP请求:
httpd.serve_forever()
test.html
<!DOCTYPE html> <html> <body> <form> 用户名:<br> <input type="text" name="username"> <br> 密码:<br> <input type="text" name="password"> <input type="submit" value="登录"> </form> </body> </html>
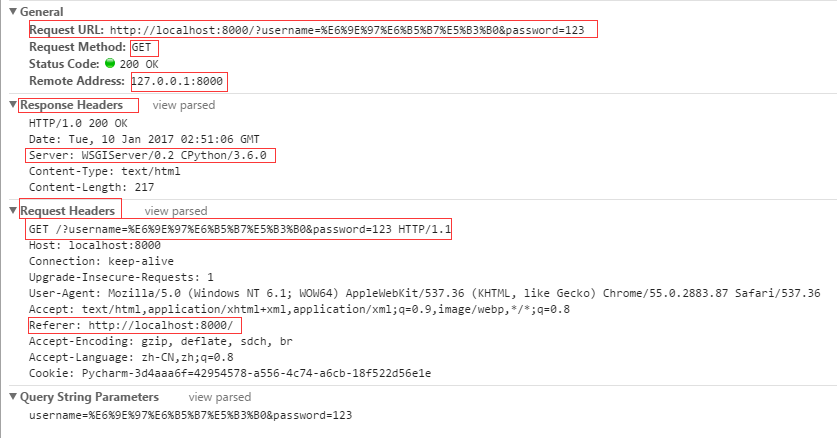
- HTTP/1.1 200 OK:响应协议为HTTP1.1,状态码为200,表示请求成功,OK是对状态码的解释;
- Server:WSGIServer/0.2 CPython/3.6.0:服务器的版本信息;
- Content-Type: text/html;charset=UTF-8:响应体使用的编码为UTF-8;
- Content-Length: 217:响应体为217字节;
- Set-Cookie: JSESSIONID=C97E2B4C55553EAB46079A4F263435A4; Path=/hello:响应给客户端的Cookie;
- Date: Wed, 25 Sep 2012 04:15:03 GMT:响应的时间,这可能会有8小时的时区差;
3.2 状态码
响应头对浏览器来说很重要,它说明了响应的真正含义。例如200表示响应成功了,302表示重定向,这说明浏览器需要再发一个新的请求。
- 200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
- 404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
- 500:请求资源找到了,但服务器内部出现了错误;
- 302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
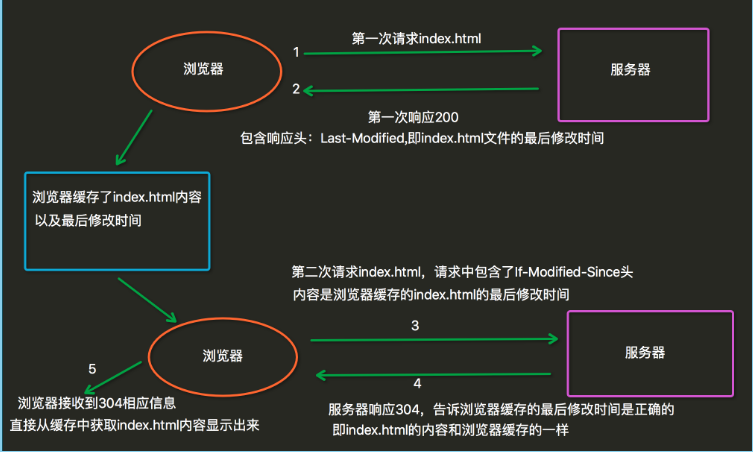
- 304:
当用户第一次请求index.html时,服务器会添加一个名为Last-Modified响应头,这个头说明了 index.html的最后修改时间,浏览器会把index.html内容,以及最后响应时间缓存下来。当用户第 二次请求index.html时,在请求中包含一个名为If-Modified-Since请求头,它的值就是第一次请 求时服务器通过Last-Modified响应头发送给浏览器的值,即index.html最后的修改时间, If-Modified-Since请求头就是在告诉服务器,我这里浏览器缓存的index.html最后修改时间是这个, 您看看现在的index.html最后修改时间是不是这个,如果还是,那么您就不用再响应这个index.html 内容了,我会把缓存的内容直接显示出来。而服务器端会获取If-Modified-Since值,与index.html 的当前最后修改时间比对,如果相同,服务器会发响应码304,表示index.html与浏览器上次缓存的相 同,无需再次发送,浏览器可以显示自己的缓存页面,如果比对不同,那么说明index.html已经做了修 改,服务器会响应200。
3.3 其他响应头
告诉浏览器不要缓存的响应头:
- Expires: -1;
- Cache-Control: no-cache;
- Pragma: no-cache;
自动刷新响应头,浏览器会在3秒之后请求http://www.baidu.com:
- Refresh: 3;url=http://www.baidu.com
3.4 HTML中指定响应头
在HTMl页面中可以使用<meta http-equiv="" content="">来指定响应头,例如在index.html页面中给出<meta http-equiv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器只会显示index.html页面3秒,然后自动跳转到http://www.baidu.com.
四 抓包分析HTTP协议
我们可以打开浏览器在菜单中选择”视图“,“开发者”,"开发者工具",选择Network来监控浏览器与web服务器之间做的事情。
web服务器收到的客户端发来的请求头
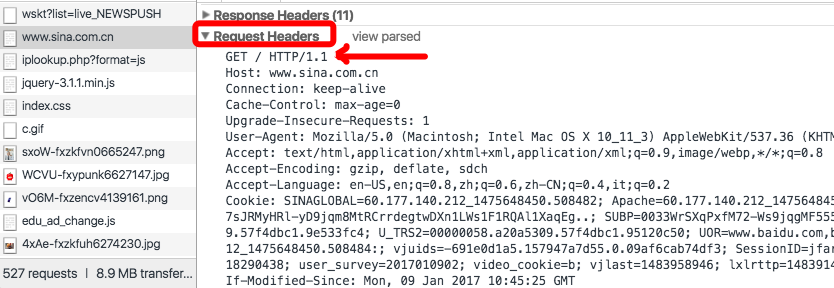
web服务器发给客户端的响应头(返回body就是html了)
