第三部分 目标文件里有什么
目标文件的格式:
他们和可执行文件的内容和结构十分相似,所以一般都和可执行文件格式一起采用一种格式存储。在win下 PE(Portable Executable)格式;在Linux下 ELF(Executable Linkable Format)文件。
动态链接库(DLL / .so)以及静态链接库(.lib (Win) / .a (Linux))文件都是按照可执行文件格式存储。
源程序编译后的机器指令经常被放到代码段(.code / .text),全局变量和局部静态变量数据经常放在数据段(.data), .bbs 未初始化数据段 保存未初始化的全局变量和局部静态变量。 这一套是C的内存结构

这样的可执行文件就五脏俱全了,直接就可以交给CPU run起来了;
问:为什么源代码被编译后分成两种段:程序指令和程序数据。代码段和数据段?
答:当程序被装载后,数据和指令分别被映射到两个虚存区域。数据区可读可写 , 代码区 只读。可以分开设置权限,防止代码区被改写;
提高程序的局部性。对CPU的缓存命中率提高有好处;
共享内存。当程序中运行多个该程序 的副本时,他们的指令都是一样的,内存中只需要保存一份该程序的指令部分。
*****************************************************************
* "真正了不起的程序员对自己的程序的每一个字节都了如指掌。" ---佚名*
*****************************************************************
step0. SimpleSection.c
#include <stdio.h> int printf(const char* format, ...);//它除了有一个参数format固定以外,后面跟的参数的个数和类型是可变的(用三个点“…”做参数占位符)
//以固定参数的地址为起点确定变参的内存起始地址。
int global_init_var = 84; int global_uinit_var; void func1(int i) { printf("%d ", i); } int main(void) { static int static_var = 85; static int static_var2; int a = 1; int b; func1(static_var + static_var2 + a + b); return 0; }
step1.编译SimpleSection.c源代码,得到了SimpleSection.o
gcc -c SimpleSection.c
Step2.使用bitnutils的工具objdump来查看object内部的结构.
objdump -h SimpleSection.o
就这样第一次打开了Object文件:
Idx Name Size VMA LMA File off Algn
0 .text 00000056 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000008 0000000000000000 0000000000000000 00000098 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000004 0000000000000000 0000000000000000 000000a0 2**2
ALLOC
3 .rodata 00000004 0000000000000000 0000000000000000 000000a0 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 00000026 0000000000000000 0000000000000000 000000a4 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000ca 2**0
CONTENTS, READONLY
6 .eh_frame 00000058 0000000000000000 0000000000000000 000000d0 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
上面的各种成分,除了我们熟悉的 代码段 数据段和为初始化数据段,还多了 只读数据段(.rodata), 注释信息段(.comment), 堆栈提示段(.note-GNU-stack);eh_frame应该是和测试有关的一个段
Size是段大小;
FileOff段所在的位置;
CONTENTS和ALLOC表示段的各种属性;CONTENT表示该段在文件中存在.BSS段没有CONTENTS表示它实际上在ELF文件中不存在内容.
代码段:
我们使用objdump来继续看一下每个段的内容: "-s"将所有段内容以十六进制的方式打印出来 "-d"可以将所有包含指令的段反汇编
objdump -s -d SimpleSection.o
暂时忽略其他内容,代码段的内容如下:
Contents of section .text:
0000 554889e5 4883ec10 897dfc8b 45fc89c6 UH..H....}..E...
0010 bf000000 00b80000 0000e800 000000c9 ................
0020 c3554889 e54883ec 10c745f8 01000000 .UH..H....E.....
0030 8b150000 00008b05 00000000 01c28b45 ...............E
0040 f801c28b 45fc01d0 89c7e800 000000b8 ....E...........
0050 00000000 c9c3 ......
偏移量 十六进制表示的段内容 ASCII码表示
反汇编得到的汇编语言如下:
Disassembly of section .text:
0000000000000000 <func1>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 89 c6 mov %eax,%esi
10: bf 00 00 00 00 mov $0x0,%edi
15: b8 00 00 00 00 mov $0x0,%eax
1a: e8 00 00 00 00 callq 1f <func1+0x1f>
1f: c9 leaveq
20: c3 retq
0000000000000021 <main>:
21: 55 push %rbp
22: 48 89 e5 mov %rsp,%rbp
25: 48 83 ec 10 sub $0x10,%rsp
29: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp)
30: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 36 <main+0x15>
36: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 3c <main+0x1b>
3c: 01 c2 add %eax,%edx
3e: 8b 45 f8 mov -0x8(%rbp),%eax
41: 01 c2 add %eax,%edx
43: 8b 45 fc mov -0x4(%rbp),%eax
46: 01 d0 add %edx,%eax
48: 89 c7 mov %eax,%edi
4a: e8 00 00 00 00 callq 4f <main+0x2e>
4f: b8 00 00 00 00 mov $0x0,%eax
54: c9 leaveq
55: c3 retq
正好可以看到,代码段的第一条指令的机器码是:0x55 最后一条指令是c3刚好对应 fun的第一条指令和main的最后一条指令.
就这样CPU在装载代码段后 顺序执行这些机器指令 就会按照汇编语言中的逻辑完成相应功能.
数据段和只读数据段:
.data保存了初始化了的全局变量和局部静态变量.代码中刚好1个初始化了的全局变量和1个初始化了的局部静态变量.一共8个bytes
Contents of section .data:
0000 54000000 55000000
第一个字节 0x54 , 第二个字节 0x00, 第三个字节0x00 第四个字节0x00. 刚好是全局变量 84; 为什么这里是0x54000000 而不是0x00000054 是因为这里采用的是
大端对齐(
所谓的大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
);
main函数中的第一个static变量的值正好是0x55000000;
.rodata :read-only只读字段一般是存放程序里面的只读变量(如 const修饰的变量) 和 字符串常量.
BBS段:
static int x1 = 0;
static int x2 = 1;
x1会被放到BBS段 而 x2会被放到data段.这是因为x1=0可以认为是未初始化的,因为为初始化的都是0.这是一个编译器的优化造成的问题!
一个自己添加的段内容:
比如,我想使用某个图片在内存中:
objcopy -I binary -O elf32-i386 -B i386 icon.jpg icon.o
可以使用objcopy工具,将图片以"elf32-i386"格式导入到目标文件中的.data段中去.
objdump -ht icon.o icon.o: 文件格式 elf32-i386 节: Idx Name Size VMA LMA File off Algn 0 .data 0001395c 00000000 00000000 00000034 2**0 CONTENTS, ALLOC, LOAD, DATA SYMBOL TABLE: 00000000 l d .data 00000000 .data 00000000 g .data 00000000 _binary_icon_jpg_start 0001395c g .data 00000000 _binary_icon_jpg_end 0001395c g *ABS* 00000000 _binary_icon_jpg_size
SYMBOL Table: 里面存放的是在该Obj文件中定义的变量符号.方便链接的时候, 链接器找到这些变量.
自定义段:
.开头的前缀的系统保留的.我们可以在ELF文件中插入 一个 "music"段,里面存放了一首mp3音乐,当ELF文件运行起来后可以读取这个段播放MP3.
如果你希望部分代码能够放到你所指定的段中去,以实现某些特定的功能.GCC提供了一个拓展机制,使得程序员可以指定变量所处的段:
__attribute__((section("FOO"))) int global = 42; __attribute__((section("BAR"))) void foo() { }
ELF文件结构描述:

头文件:
我们可以使用readelf命令来详细查看ELF文件
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (可重定位文件)
Machine: Advanced Micro Devices X86-64
Version: 0x1
入口点地址: 0x0
程序头起点: 0 (bytes into file)
Start of section headers: 1056 (bytes into file)
标志: 0x0
本头的大小: 64 (字节)
程序头大小: 0 (字节)
Number of program headers: 0
节头大小: 64 (字节)
节头数量: 13
字符串表索引节头: 10
Magic: ELF魔术.这16个字节用来标识ELF文件的平台属性.用来确定文件的类型.
段表
保存ELF文件中各种段的基本属性结构.段表是ELF文件中除头文件之外最重要的结构.之前使用"objdump -h"查看的是ELF文件中包含的关键段,下面使用
readelf -S SimpleSection.o

重定位表
".rel.text"段,他的类型是sh_type,也就是一个重定位表(Relocation Table).链接器在处理目标文件的时候,需要对目标文件中某些部位进行重定位.即代码段和数据段中那些对绝对地址的引用的位置.
这些重定位文件的信息都记录在ELF文件的重定向表里面.
在这个例子中因为printf函数的调用,".text"段中至少有它是对绝度地址的应用.所以出现了".rel.text"
链接的接口---符号
不同目标文件之间的链接正式靠目标文件之间对地址的引用,即对函数和变量的地址的引用.我们将函数和变量统称未符号,函数名或者变量名就是符号名.
每一个目标文件都有一个符号表.每个定义的符号有一个对应的值,叫做符号值.对于函数和变量来说就是他们的地址.
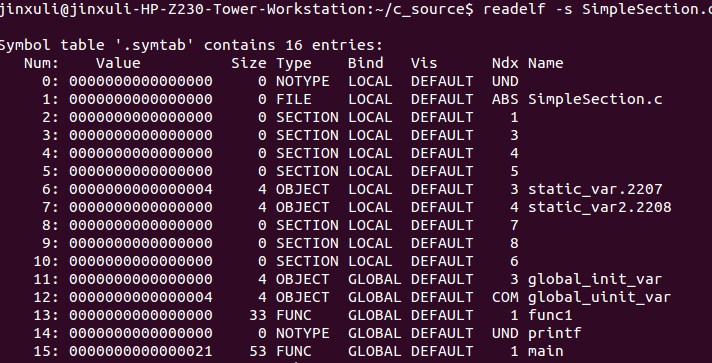
特殊符号:
链接器脚本中定义的变量,我们可以直接在程序中使用他们.
符号修饰与函数签名:
编译器编译源代码产生的目标文件时,符号名与相应的变量和函数名不能相同,这样如果库中有的函数不能和目标文件中的符号重名,所以规定C语言编写的源代码中所有的变量和函数经过编译以后,
在相应的符号名前面加下划线"_".而Fortran语言的源代码经过编译后,所有符号名前面+"_"后面也"_".
c++又使用了命名空间来解决这个问题.
*******************************************************************
c++函数重载一种简单的情况:同名函数可以根据参数的不同实现不同的功能,怎么实现的呢?
**************************************************************
C++符号修饰
c++拥有类 继承 虚机制 重载 名称空间等特性 .为了实现这些复杂的机制, 出现了 符号修饰 与 符号改编.
函数签名:

使用c++编译单元自带的宏定义来判断当前编译单元,因为C++会按照自己的修饰规则修饰memset函数,使得符号不能链接到C库中的memset函数.
#ifdef __cplusplus extern "C"{ #endif void *memset(void *, int, size_t); #ifdef __cplusplus } #endif
强符号与弱符号:
编程中经常遇到符号重复定义错误.定义在文件中的global变量是一种强符号,有些符号的定义是弱符号(weak Symbol 让我想起来OC里也非常常见这样强弱之分的变量).对于c/c++来说,编译器默认函数和初始化了的全局变量成为强符号,未初始化的全局变量是弱符号.我们通过:
__attribute__((weak)) weak2 = 2;
当定义一个若引用的变量或者函数的时候,如果最终未定义,编译不会报错(会被默认的初始化)但是运行的时候如果调用到了他 ,那么会发生错误.
用处:对于库函数来说,十分有用.比如库中定义的弱符号可以被用户定已成强符号所覆盖,从而使得程序可以使用自定义版本的库函数.比如,
在Linux程序涉及中,如果一个程序被设计成可以支持单线程或多线程的模式,就可以通过弱引用的方法来判断当前的程序是链接到了单线程的Glibc库还是多线程的Glibc库(是否在编译时有-lphread选项, 可以让编译器在链接的时候在:搜索路径(默认路径以及-L指定的路径)中找libpthread.a/so,并进行链接可以让程序调用一些线程函数),从而执行单线程版本还是多线程版本的程序.