第一次参加数据预测竞赛,发现还是挺有意思的。本文中的部分内容参考第一名“诗人都藏在水底”的解决方案。
从数据划分、特征提取、模型设计、模型融合/优化,整个业务流程得到了训练。作为新手在数据划分和模型训练以及模型融合上做的不够好(都是套路)。
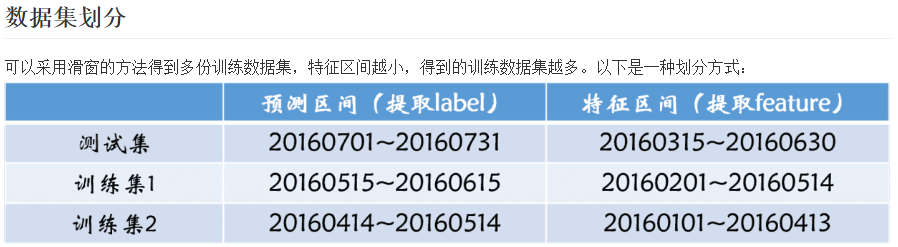
首先,数据划分方式最自然的按照月份-》后面的月份这种自然顺序(滑窗)即可,在整个数据集上做特征提取实在是不能发挥出 特征的优势,因为数据量本身挺大,太多的脏数据,会导致训练出的模型不准确。
看来这个竞赛并没有涉及到太多的数据清洗处理等工作。
用户特征、商户特征、优惠券相关的特征、用户-商家交互特征有很多。

从单模型到多模型的加权融合。每一个模型都是在训练集上调优到极限的。所以调模型并不是一个不重要的工作。主流的回归模型果然还是GBDT嘴刁,
XGBoost,GBDT,RandomForest这三种是他们用的主要模型。