author: lunar
date: Sat 17 Oct 2020 09:18:24 PM CST
进程管理
1. 进程
进程是处于执行期的程序以及相关的资源的总称。进程通过fork调用进行创建,创建的方式是复制父进程,fork调用从内核返回两次,一次回到父进程,另一次回到新产生的子进程。
通常,创建新的进程是为了立即执行新的、不同的程序,而接着调用exec()函数就可以创建新的地址空间。
2. 进程描述符及任务结构
内核把进程的列表存放在叫做任务队列的双向循环链表中,链表中的每一项都是类型为task_struct、称为进程描述符的结构体。
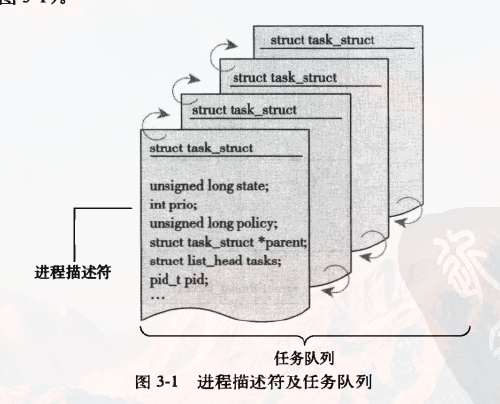
分配进程描述符
linux通过slab分配器分配task_struct结构,可以达到对象复用和缓存着色的目的(后面会讲)。在2.6之前的内核中,各个进程的task_struct存放在它们内核栈的尾部,这样可以根据栈指针迅速计算出位置。现在用slab分配器动态生成task_struct后,只需要在栈顶创建一个thread_info的结构体,这个结构体相比于task_struct更加轻量(task_struct在32位系统下能够达到1.7KB之多),所以进程的创建更加迅速了。

可以看到在thread_info结构体内有一个指向task_struct结构体的指针,对于寄存器富余的硬件体系来说,也可能为了更快找到task_struct,专门拿出一个寄存器用来存放这个指针。
内核栈:进程在内核态运行时,需要有自己的堆栈信息(而不是使用原来的那个栈),这个栈就是内核栈。知晓了kernel stack, thread_info, task_struct三者的任一位置都可以得到另外两个的位置。
正因为如此:在task_struct内部通过联合体来表示stack或thread_info的位置:
union thread_union {
struct thread_info* thread;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
当进程刚刚切换到内核态时,内核栈还是空的,thread_info被创建在底部,而栈从顶部开始往下增长。内核栈的大小一般是一个内存页的大小,在32位机器上是4KB。看起来很小,但是Linus那批人已经在源码上尽量保证系统调用不会有栈溢出了,所以尽管放心。
顺便说一句,内核态的进程没有私有堆的概念可言。内核态的进程通过kmalloc()函数统一分配动态内存,分配的动态内存由内核统一管理。所以理论上内核态动态分配的内存可以被所有内核态的其它进程访问到。
3. 进程创建
Unix系统将进程的创建分为两步去执行:fork()和exec()(exec()这里指所有exec()一族的函数)。首先,fork()函数通过拷贝当前进程创建一个子进程,两者的区别仅仅在于PID和某些资源的统计量。exec()函数负责读取可执行文件并将其载入地址空间开始运行。
写时拷贝
在创建子进程时就复制父进程的整个地址空间并不是一种聪明的做法。首先是速度会很慢,其次是子进程创建出来可能并不需要地址空间的每一块都与父进程不同,其中很大一部分都可以与父进程共享。
所以,linux采取的策略是父进程和子进程表面上享有不同的地址空间,但实际上指向同一块物理内存。资源只在其中某个进程需要写入的时候才会进行复制,在此之前都是以只读的方式进行共享。
fork()
Linux通过 clone() 调用实现fork(),然后由 clone() 去调用 do_fork()。
do_fork调用copy_process()函数,然后让进程开始运行。copy_process函数完成的工作包括:
- 调用dup_task_struct()为新进程创建一个内核栈、thread_info和task_struct,值保持与当前进程相同。
- 子进程着手使自己与父进程区别开来,进程描述符内的许多成员都被清0,但是大部分数据依然没有被修改。
- 子进程的状态被设置为 TASK_UNINTERUPTIBLE,以保证它不会被投入运行。
- 调用alloc_pid() 为新进程分配一个有效的 pid
- 根据传递给clone()的参数标志,copy_process() 拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等。
- 最后,copy_process()做扫尾工作并返回一个指向子进程的指针。
回到do_fork()函数,如果copy_process()成功返回,则子进程被唤醒并投入运行,并且操作系统一般会有意让子进程优先执行,因为一般子进程都会马上调用exec()函数,可以避免写时拷贝的额外开销。
4. 线程在Linux中的实现
Linux 实现线程的方式非常独特,从内核的角度来说,并没有线程这个概念,Linux 把所有的线程都当作进程看待,线程被当作与其它“进程”共享某些资源的进程。
创建线程
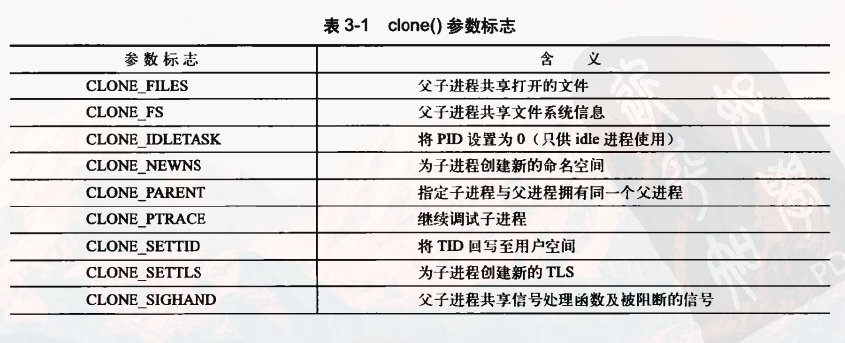
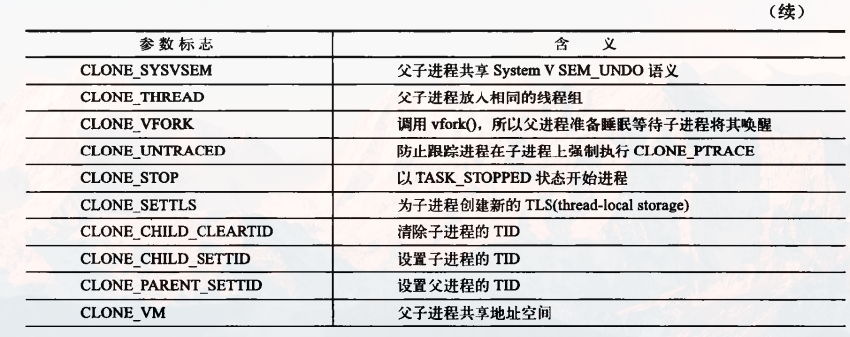
线程创建时通过clone()函数来实现,只不过需要传递一些参数标志来指明需要共享 的资源:
内核线程
内核进程和普通的进程的区别在于内核进程没有独立的地址空间,它们只在内核空间中运行,从不切换到用户空间去。
而内核线程只能由内核线程创建,创建的函数为 kthread_create
内核线程在后面还会详细讨论。
5. 进程终结
进程退出时,首先会释放一系列资源,比如打开的文件等。然后调用exit_notify()函数向父进程发送信号表示自己要退出了,需要给自己的子进程找养父。养父一般为线程组的其它线程或者init进程。
然后将进程状态置为 EXIT_ZOMBIE,僵尸进程将再也不会被调度。接着调用schedule() 切换到新的进程。
到了这一步,与进程有关的资源都释放掉了,但是进程本身的内存包括内核栈、thread_info结构和task_struct结构等还留在内存内。这样做可以让系统有办法在子进程终结之后仍然有办法获得它的信息。